本文介绍了HQTrack,一种新的高质量视频物体追踪框架。HQTrack结合了视频多目标分割器(VMOS)和蒙版细化器(MR),可追踪视频初始帧中指定的物体,并对追踪结果进行细化,以获得更高的准确性。尽管VMOS在多个视频物体分割(VOS)数据集上的训练限制了其适应复杂场景的能力,但MR模型有助于提升追踪结果的精度。HQTrack在不使用额外增强措施,如测试时的数据增强和模型集成等的情况下,通过在视觉物体追踪和分割(VOTS2023)挑战中获得第二名,证明了其效果。
方法
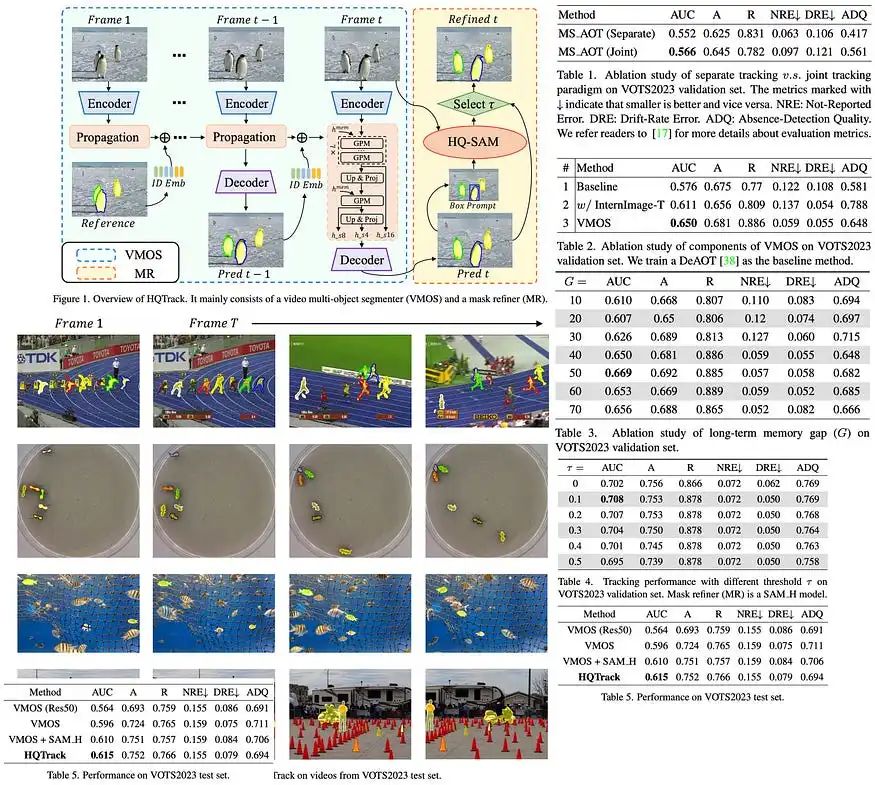
视频多目标分割器
VMOS是HQTrack框架的关键组成部分,是DeAOT模型的变体,专门设计用于提高分割性能。与原始的DeAOT不同,后者在16×尺度的视觉和识别特征上操作,VMOS采用了一个门控传播模块(GPM),与8×尺度级联,并将传播过程扩展到多个尺度。这种方法有助于保留可能在较大尺度上丢失的详细对象线索,从而提高对微小对象的感知能力。VMOS使用上采样和线性投影,仅将传播特征放大到4×尺度,考虑内存使用和模型效率。然后,将这些多尺度传播特征输入简单的特征金字塔网络(FPN)解码器进行蒙版预测。此外,VMOS还整合了Internimage的Intern-T,这是一个基于大规模CNN的模型,使用了可变形卷积,以增强物体的区分能力。
蒙版细化器
HQTrack中的蒙版细化器采用了预训练的HQ-SAM模型,它是Segment Anything Model的变体。由于其在包含11亿个蒙版的高质量数据集上的训练,SAM在图像分割能力和零样本泛化方面引起了重视。然而,由于SAM在包含复杂对象的图像中存在问题,因此开发了HQ-SAM。该模型通过引入额外的参数到预训练模型中来改进SAM,提供了更高质量的蒙版。
在HQTrack中,MR细化了由VMOS生成的预测蒙版,尤其是在VMOS的结果可能因其在受限的尺度关闭数据集上的训练而导致质量不足的复杂场景中。MR计算来自VMOS的预测蒙版的外部包围框,将这些框提示以及原始图像输入到HQ-SAM模型中,并生成细化蒙版。
HQTrack的最终输出蒙版从VMOS和HQ-SAM的结果中选择。如果VMOS和HQ-SAM之间的交并比(IoU)分数高于某个阈值,就会选择细化的蒙版。这个过程鼓励HQ-SAM专注于细化当前的对象蒙版,而不是重新预测另一个目标对象,从而提高分割性能。
实验
消融研究
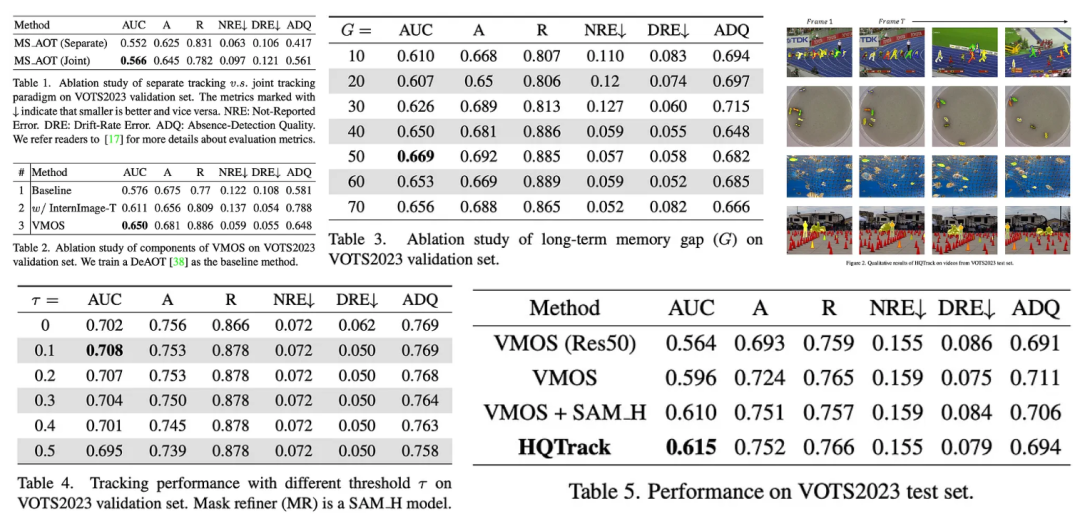
在对不同追踪范式进行消融研究时,发现使用单一追踪器对所有目标对象进行联合追踪比分别追踪(每个目标对象分别追踪)表现更好。联合追踪的更好表现可能是因为追踪器理解目标对象之间的关系,提高了对干扰干扰的鲁棒性。
针对视频多目标分割器(VMOS)进行的分量研究表明,将原始的ResNet50主干网络替换为InternImage-T,并添加多尺度传播机制,会显著提高性能。曲线下面积(AUC)分数从0.611增加到0.650,证实了这些修改的有效性。
考虑到视觉物体追踪和分割(VOTS)视频中的长序列,重新评估了长期内存间隔参数。研究发现,内存间隔为50提供了最佳性能。
HQTrack的蒙版细化器(MR)也经过了检验。发现直接细化所有分割蒙版并不是最优的。尽管用SAM细化蒙版可以显著提高性能,但会损害质量较低的蒙版的性能。因此,提出了一个选择过程:当VMOS和SAM之间的交并比(IoU)分数高于阈值时,选择细化的蒙版作为最终输出。
论文链接:https://arxiv.org/abs/2307.13974v1
代码链接:https://github.com/jiawen-zhu/HQTrack
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除