日前国内大模型开源市场又多了一个猛将:百川智能,厂商卷,消费者就受益,这块模型由原搜狗创始人带队研发,背后融合有一些搜索的思路,日前公开了其53B的大模型,未来的企业应用上又多了一份选择。
https://www.baichuan-ai.com/ 官方网站

申请内测
内测申请比较简单,手机号登陆网站后,点击“加入内测”按钮,就加入了等待列表,审核速度还是比较快的。
 审核通过后,会有短信通知,就可以正常使用对话交流了。
审核通过后,会有短信通知,就可以正常使用对话交流了。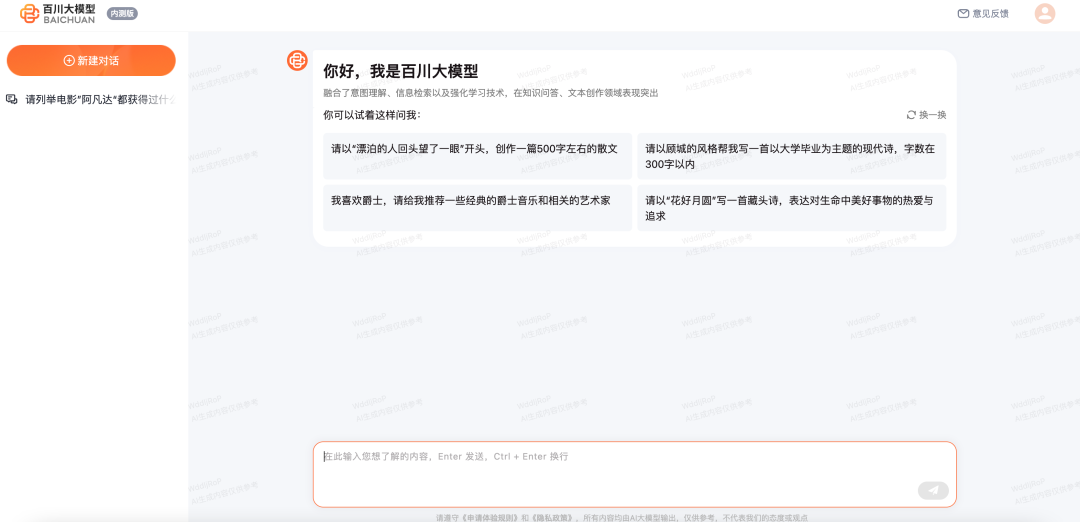
小尺寸开源模型
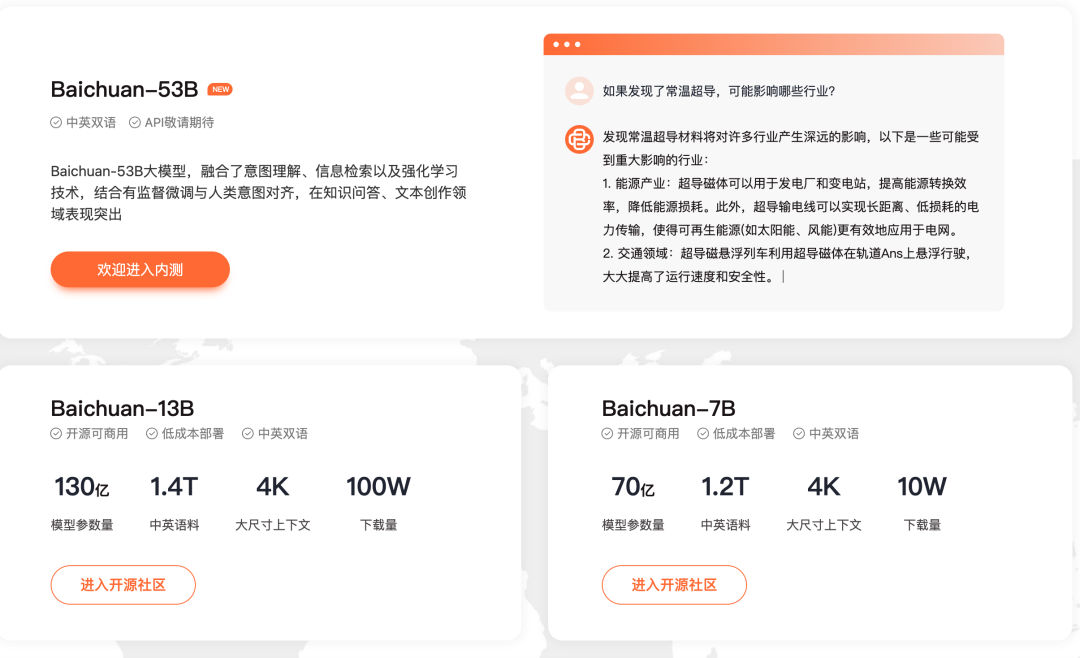
百川旗下的 Baichuan-7B 与 Baichuan-13B 两个模型目前已经开源可商用,为企业内部应用提供了两个不错的选择。 Baichuan-7B 是一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约 1.2 万亿 tokens 上训练的 70 亿参数模型,支持中英双语,上下文窗口长度为 4096。在标准的中文和英文 benchmark(C-Eval/MMLU)上均取得同尺寸最好的效果。
Baichuan-7B 是一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约 1.2 万亿 tokens 上训练的 70 亿参数模型,支持中英双语,上下文窗口长度为 4096。在标准的中文和英文 benchmark(C-Eval/MMLU)上均取得同尺寸最好的效果。

Baichuan-13B 是包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。Baichuan-13B 有如下几个特点:
更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
同时开源预训练和对齐模型:预训练模型是适用开发者的『 基座 』,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
更高效的推理:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。

对话体验
对话界面与主流基本一致,可以拿一些想法与百川模型进行交流,看看实际效果。


随着时间的推移,会有更多的国产模型开放能力出来,功能也会越来越强大,但目前普遍离GPT-3.5都还有些距离,厂商们加油吧。
公众号回复“Claude实战”,“ChatGPT实战”,“WPSAI实战”,获取相应的电子书。
—扩 展 阅 读—