《汇编语言》- 读书笔记 - 第7章- 更灵活的定位内存地址的方法
7.1 and 和 or 指令
- and 指令: 逻辑与指令,按位进行与运算
mov al, 00001111b
and al, 01010101b
;结果: 00000101b 双方都为1的位为1,其他为0
- or 指令: 逻辑或指令,按位进行或运算
mov al, 00001111b
and al, 01010101b
;结果: 01011111b 只要有1方为1的位就为1,双方都是0的位为0
7.2 关于 ASCII 码
计算机只认01。
于是人们定义了很多规则,ASCII就是一种文字的编码规则
比如小写字母a 在ASCII中定义它的编码是97。
于是在读写a的过程就是:
- 写a
- 按下键盘
a - 程序收到
a按ASCII规则编码,得到97 - 将
97转成二进制1100001保存。(内存或硬盘)
- 按下键盘
- 读a
- 程序从内存读取到
1100001计算机知道这就是10进制的97 - 使用
ASCII规则解码,97代表小写a - 通知显卡将
a画出来。(前面介绍过就是写显存,具体怎么画是显示的工作了)
- 程序从内存读取到
可见数据本身是死的,只有程序按特定规则去处理它,它才有意义。
假如有另一个程序,它包含着另一套规则,那当它读到 1100001 又是完全不同的含义了。
7.3 以字符形式给出的数据
在汇编程序中,用'......'(单引号括字符)的方式声明字符数据,编译器会把它们转化为相应的ASCII码。
程序 7.1
assume cs:code, ds:data
data segment ; 占16字节
db 'Jerry' ; 4A 65 72 72 97
db 'abc' ; 61 62 63
data ends
code segment
start: mov al, 'a'
mov bl, 'b'
mov ax, 4c00h
int 21h
code ends
end start
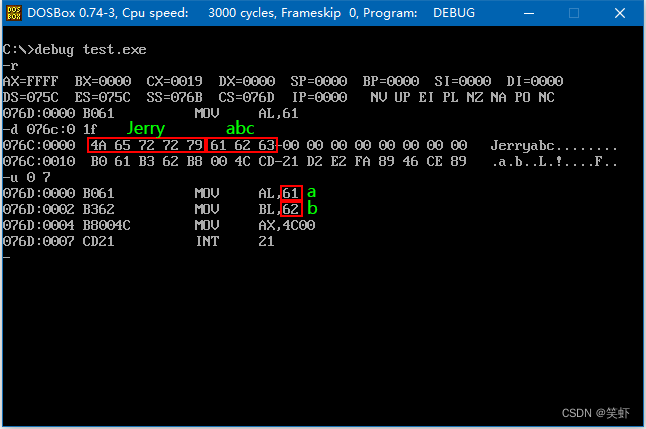
编译器把字符转成了ASCII码。
7.4 大小写转换的问题
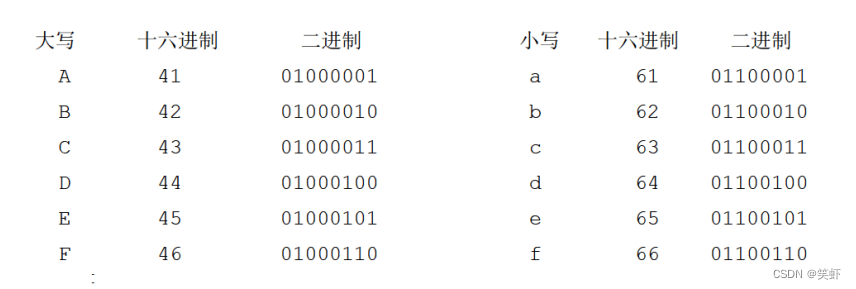
- 观察
ASCII码表(虽然不然能观察规律就行),大小写字母的ASCII码相关32。 - 大小写转换时,大转小 + 32,小转大-32。(但是
ASCII设计的很巧妙,我们不用去判断当前的大小写) A与a区别就是第6位。00100000b=20H=32
01000001
01100001
利用位运算 and 1101 1111 实现转大写。(第6位置0,其他位不变)
A:01000001 a:01100001
and 20H:11011111 11011111
-----------------------------
A:01000001 A:01000001
利用位运算 or 0010 0000 实现转小写。(第6位置1,其他位不变)
A:01000001 a:01100001
or 20H:00100000 00100000
-----------------------------
a:01100001 a:01100001
7.5 [bx+idata] (变量 + 固定偏移量)
idata:表示常量。
mov ax, [bx+200] 表示,从内存 ((ds)*16+(bx)+200) 取出数据送入 ax。
[]中的最终结果是物理地址:bx的内容 + 常量 200,得到物理地址后,再从地址取出内容。
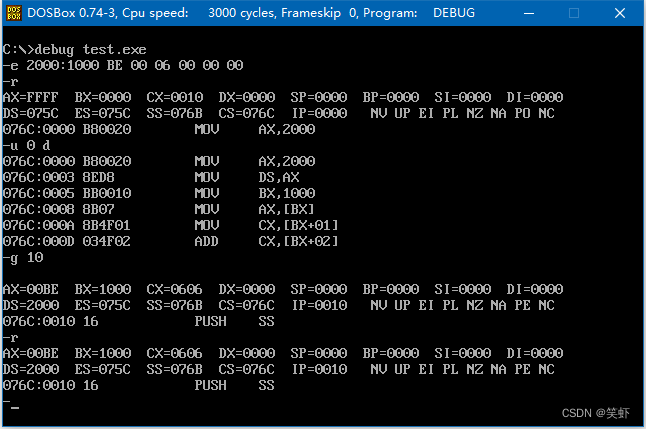
问题 7.1
写出下面的程序执行后,ax、bx、cx 中的内容
code segment ; ax bx cx ds
start: mov ax, 2000h ; 2000
mov ds, ax ; 2000
mov bx, 1000h ; 1000
mov ax, [bx] ; 00BE
mov cx, [bx+1] ; 0600
add cx, [bx+2] ; 0606
code ends
end start
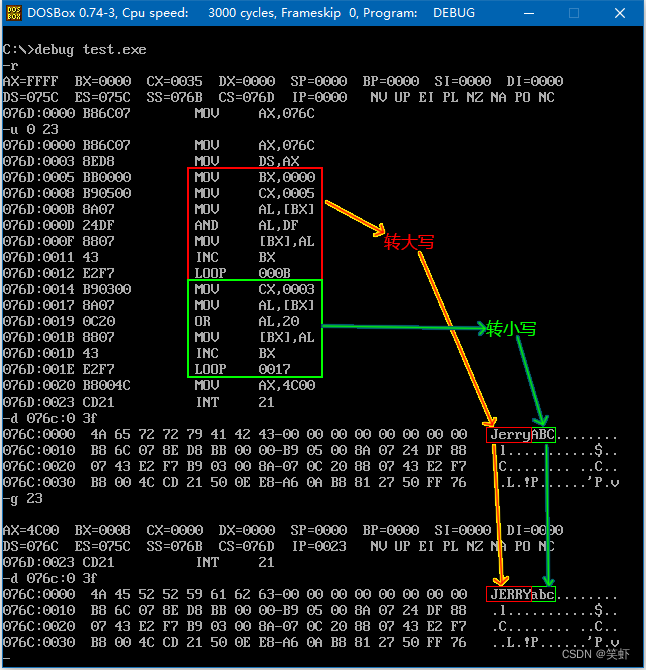
7.6 用[bx+idata]的方式进行数组的处理
idata: 按传址理解,idata就相当于数组地址
bx: 表示遍历量,相当于遍历数组时的 i
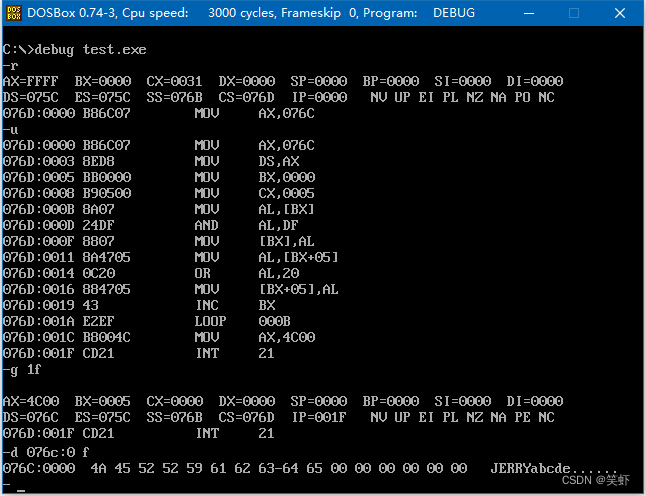
将 data 中定义的第一个字符串转化为大写,第二个字符串转化为小写。
assume cs:code;, ds:data
data segment ; 占16字节
db 'jerry'
db 'ABCDE'
data ends
code segment
start: mov ax, data
mov ds, ax
mov bx, 0 ; i = 0
mov cx, 5 ; len = 5
s: mov al, [0+bx] ; 0表示第一个数组的位置 bx表示索引
and al, 11011111b ; 转大写
mov [0+bx], al ; 送回内存
mov al, [5+bx] ; 5表示第二个数组的位置 bx表示索引
or al, 00100000b ; 转小写
mov [5+bx], al ; 送回内存
inc bx ; i++
loop s ; cx--; cx != 0 继续循环,循环结束
mov ax, 4c00h
int 21h
code ends
end start
7.7 SI 和 DI (源地址>目标地址)
si 和 di 是 8086CPU 中和 bx 功能相近的存器。
si 和 di 不能够分成两个 8 位存器来使用。
- 常见用法是在两块内存间复制数据时:
ds:si 指向来源
ds:di 指向目的地
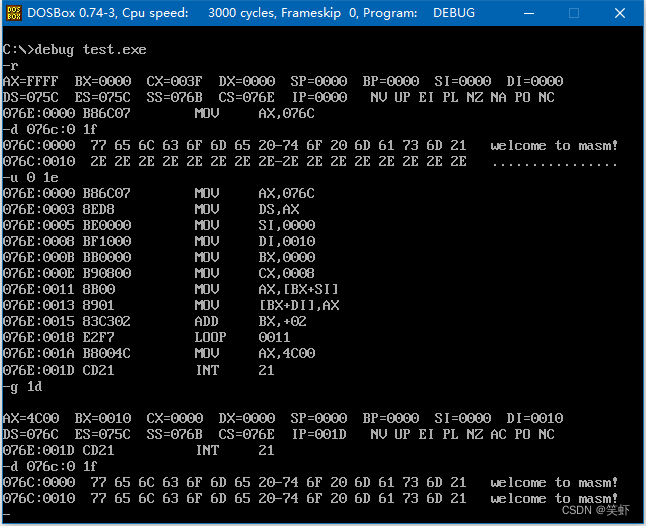
问题 7.2
用 si 和 di 实现将字符串welcome to masm!!复制到它后面的数据区中。
assume cs:codesg,ds:datasg
datasg segment
db 'welcome to masm!' ; 占16字节
db '................' ; 占16字节
datasg ends
codesg segment
start: mov ax, datasg
mov ds, ax
mov si, 0 ; 指向第一行字符开头
mov di, 16 ; 指向第二行字符开头
mov bx, 0 ; i = 0 对应字符索引
mov cx, 8 ; len = 8 每次复制一个字,共循环处理8次
s: mov ax, [si+bx] ; 取第一行的第bx个字符
mov[di+bx], ax ; 送到第二行的第bx位
add bx, 2 ; i++ (每次偏移1个字 = 2字节)
loop s ; cx--; cx != 0 继续循环,循环结束
mov ax, 4c00h
int 21h
codesg ends
end start
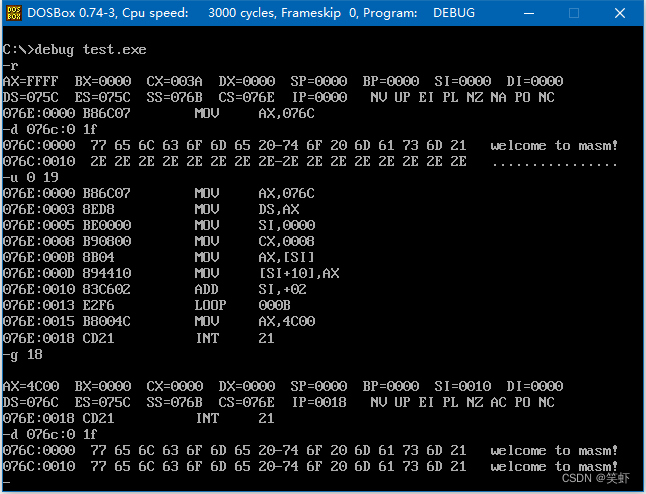
问题 7.3
优化 问题 7.2 减少代码量。
可以利用[bx+idata]或[si+idata]或[di+idata]的方式,来减化。
assume cs:codesg,ds:datasg
datasg segment
db 'welcome to masm!' ; 占16字节
db '................' ; 占16字节
datasg ends
codesg segment
start: mov ax, datasg
mov ds, ax
mov si, 0 ; i = 0
mov cx, 8 ; len = 8 每次复制一个字,共循环处理8次
s: mov ax, 0[si] ; 取第一行(偏移量0)的第bx个字符
mov 16[si], ax ; 送到第二行(偏移量16)的第bx位
add si, 2 ; i++ (每次偏移1个字 = 2字节)
loop s ; cx--; cx != 0 继续循环,循环结束
mov ax, 4c00h
int 21h
codesg ends
end start
7.8 [bx+si]和[bx+di]
bx+变量,更加灵活
例如数组操作:
si:表示原数组(指向数组第一个元素在内存中的地址)
di:表示目标数组(指向数组第一个元素在内存中的地址)
bx:表示索引
如此可方便的一个循环中对两个数组进行操作。
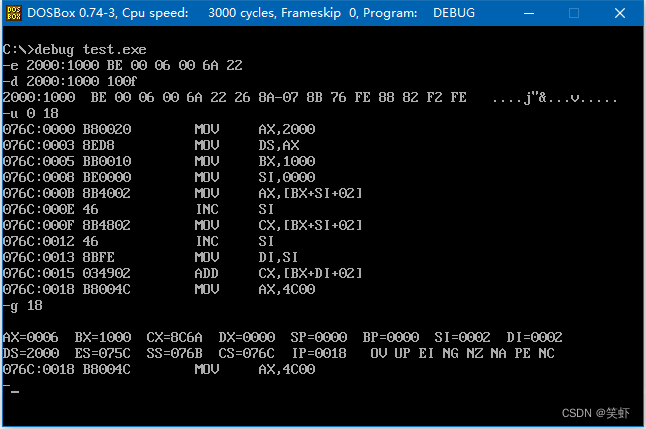
问题 7.4
写出下面的程序执行后,ax、bx、cx 中的内容
; 2000:1000 BE 00 06 00 00 00
assume cs:codesg
codesg segment ; ax bx cx ds si di
start: mov ax, 2000H ;
mov ds, ax ; 2000
mov bx, 1000H ; 1000
mov si, 0 ; 0000
mov ax, [bx+si] ; 00BE
inc si ; 0001
mov cx, [bx+si] ; 0600
inc si ; 0002
mov di, si ; 0002
add cx, [bx+di] ; 0606
mov ax, 4c00h
int 21h
codesg ends
end start
7.9 [bx+si+idata]和[bx+di+idata]
bx+变量+常量,更更加灵活
例如二维数组操作:(通过偏移量,实现行列的概念)
idata:表示二维数组(指向数组第一个元素在内存中的地址)
bx:表示行(相当于嵌套for中,第一层for的 i)
di:表示例(相当于嵌套for中,第二层for的 j)
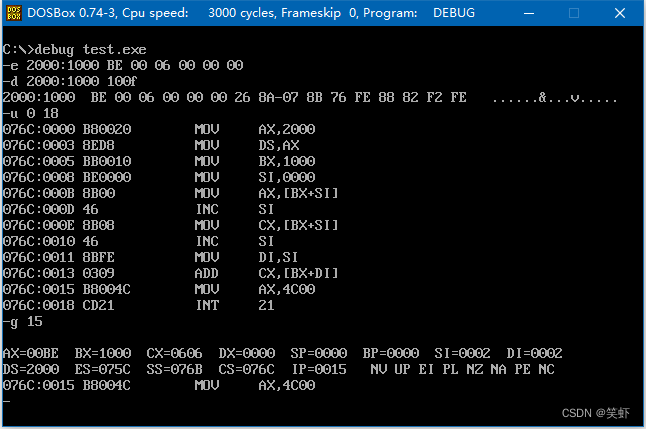
问题 7.5
写出下面的程序执行后,ax、bx、cx 中的内容
; 2000:1000 BE 00 06 00 6A 22
assume cs:codesg
codesg segment ; ax bx cx ds si di
start: mov ax, 2000H ;
mov ds, ax ; 2000
mov bx, 1000H ; 1000
mov si, 0 ; 0000
mov ax, [bx+2+si] ; 0006
inc si ; 0001
mov cx, [bx+2+si] ; 6A00
inc si ; 0002
mov di, si ; 0002
add cx, [bx+2+di] ; 8C6A(6A00+226A)
mov ax, 4c00h
int 21h
codesg ends
end start
7.10 不同的寻址方式的灵活应用
[idata]用一个常量来表示地址,可用于直接定位一个内存单元;[bx]用一个变量来表示内存地址,可用于间接定位一个内存单元;[bxtidata]用一个变量和常量表示地址,可在一个起始地址的基础上用变量间接定位一个内存单元;[bx+si]用两个变量表示地址;[bx+sitidata]用两个变量和一个常量表示地址。
可以看到,从[idata]一直到[bx+sitidata],都是为了使用更加灵活的方式来定位一个内存单元的地址。这使我们可以从更加结构化的角度来看待所要处理的数据。
本质就是先将[]中寄存器和常量表达式算出结果,作为物理地址,然后指向那块内存。
问题 7.6
编程,将 datasg 段中每个单词的头一个字母改为大写字母
assume cs:codesg,ds:datasg
datasg segment ; 占16*6=16字节
db '1. file ' ; 占16字节,末尾空格填充
db '2. edit ' ; 占16字节,末尾空格填充
db '3. search ' ; 占16字节,末尾空格填充
db '4. view ' ; 占16字节,末尾空格填充
db '5. options ' ; 占16字节,末尾空格填充
db '6. help ' ; 占16字节,末尾空格填充
datasg ends
codesg segment
start: mov ax, datasg
mov ds, ax
mov bx, 0
mov cx, 6
s: mov al,[bx+3] ; 取 bx行第3列
and al, 11011111b ; 转大写
mov [bx+3], al ; 送回内存
add bx, 16
loop s
mov ax, 4c00h
int 21h
codesg ends
end start
问题 7.7
编程,将 datasg 段中每个单词改为大写字母

这段是反面教材,两个循环共用 CX 陷入死循环。
assume cs:codesg,ds:datasg
datasg segment ; 占16*4=24字节
db 'ibm ' ; 占16字节,末尾空格填充
db 'dec ' ; 占16字节,末尾空格填充
db 'dos ' ; 占16字节,末尾空格填充
db 'vax ' ; 占16字节,末尾空格填充
datasg ends
codesg segment
start: mov ax, datasg
mov ds, ax
mov bx, 0
mov cx, 4 ; 循环4次对应4行
s0: mov si, 0 ; 每行的字符索引从0开始
mov cx, 3 ; 本意是循环3次对应3个字符
; 但是它覆盖了上面“行”的循环计数。
; 两层循环共用同一个cx计数,就崩了。
s: mov al,[bx+si] ; 取 bx行第3列
and al, 11011111b ; 转大写
mov [bx+si], al ; 送回内存
inc si ; 内层循环j++ 指向下一个字符
loop s ; 内层循环
add bx, 16 ; 外层循环i++ 指向下一歫
loop s0 ; 外层循环
mov ax, 4c00h
int 21h
codesg ends
end start
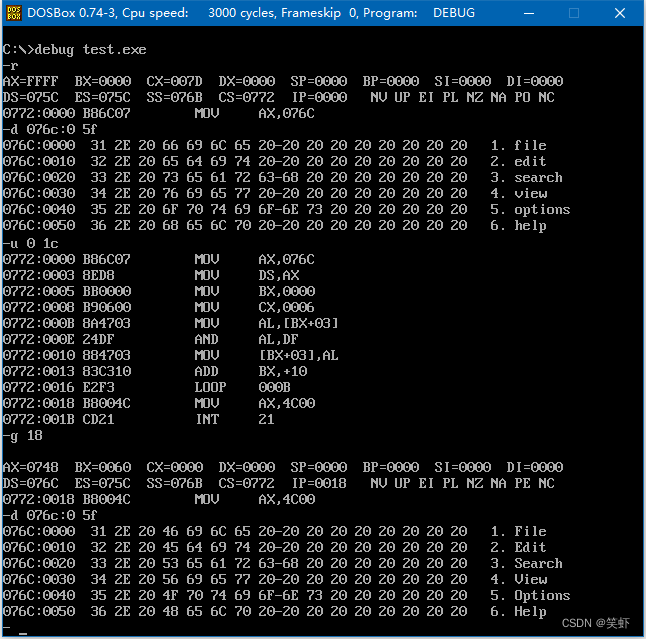
问题 7.8
修复7.7的错误。在每次开始内层循环的时候,将外层循环的 cx 中的数值保存起来,在执行外层循环的 loop 指令前,再恢复外层循环的 cx 数值。可以用寄存器 dx 来临时保存 cx 中的数值,改进的程序如下。
assume cs:codesg,ds:datasg
datasg segment ; 占16*4=24字节
db 'ibm ' ; 占16字节,末尾空格填充
db 'dec ' ; 占16字节,末尾空格填充
db 'dos ' ; 占16字节,末尾空格填充
db 'vax ' ; 占16字节,末尾空格填充
datasg ends
codesg segment
start: mov ax, datasg
mov ds, ax
mov bx, 0
mov cx, 4 ; 循环4次对应4行
s0: mov dx, cx ; 将外层循环的 cx 值保存在 dx 中
mov si, 0 ; 每行的字符索引从0开始
mov cx, 3 ; 循环3次对应3个字符
s: mov al,[bx+si] ; 取 bx行第3列
and al, 11011111b ; 转大写
mov [bx+si], al ; 送回内存
inc si ; 内层循环j++ 指向下一个字符
loop s ; 内层循环
add bx, 16 ; 外层循环i++ 指向下一行
mov cx, dx ; 用 dx 中存放的外层循环的计数值恢复 cx
loop s0 ; 外层循环
mov ax, 4c00h
int 21h
codesg ends
end start
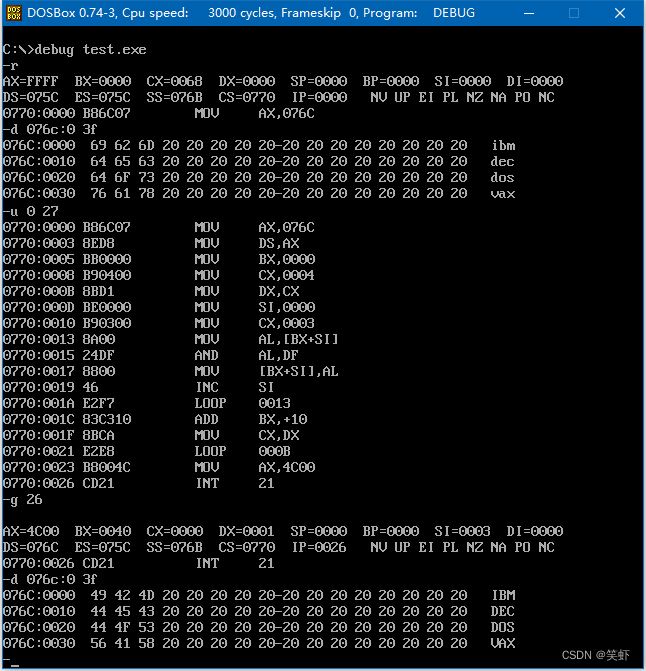
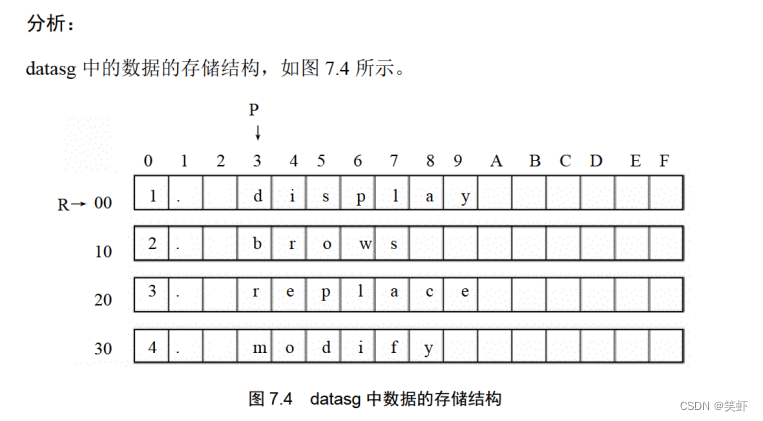
问题7.9
编程,将 datasg 段中每个单词的前 4 个字母改为大写字母
assume cs:codesg,ss:stacksg,ds:datasg
stacksg segment ; 占16字节
dw 0,0,0,0,0,0,0,0
stacksg ends
datasg segment ; 占64字节
db '1. display ' ; 占16字节
db '2. brows ' ; 占16字节
db '3. replace ' ; 占16字节
db '4. modify ' ; 占16字节
datasg ends
codesg segment
start:
codesg ends
end start