一、JVM概述
①所有的java代码都是在虚拟机中运行的。②一次编译,到处运行。JVM可以和不同的操作系统交互。Java是一门跨平台性语言。
二、JVM、JDK 、JRE区别
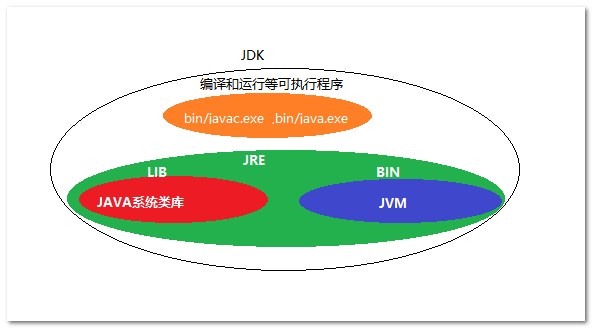
JDK:(Java Development Kit) 是Java语言的软件开发工具包。JRE:在JDK的安装目录下有一个jre目录,里面有bin和lib两个文件夹,可以认为bin里的就是JVM,lib中则是jvm工作所需要的类库,而jvm和lib合起来称为jre。
总结:
- JDK是整个Java的核心,包括了Java运行环境JRE、Java工具和Java基础类库。
- JRE是运行JAVA程序所必须的环境的集合,包含JVM标准实现及Java核心类库。
- JVM是整个java实现跨平台的最核心的部分,能够运行以Java语言写的程序。
三、JVM内存分布
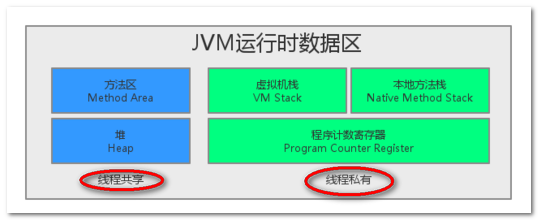
1.方法区
线程共享,存储已经被虚拟机加载的类信息(全限定名,父类全限定名、接口、类、修饰词、方法信息、属性信息...)、常量、静态变量、即时编译器编译后的代码等元数据信息。在方法区有一块非常重要的子内存空间,常量池。
2.堆
Java中的堆是用来存储对象本身以及数组的(数组引用是存放在Java栈中)。Java的垃圾回收机制会自动进行处理。因此这部分空间也是GC管理的主要区域。
另外,堆是被所有线程共享的,在JVM中只有一个堆。
堆内存不足会抛OutOfMemoryError异常。
堆又细分为新生代和老年代,新生代又分为Eden空间、From Survivor空间、To Survivor空间。
public class TestHeap {
private static int i = 1 ;
@Test
public void heapOverflow(){
User[] arr = new User[1024];
for(int i = 0 ; i < 1024 ; i ++){
arr[i] = new User();
}
}
}
//由于堆中存储的是对象,当创建的对象过多时就会发生栈溢出,错误提示:java.lang.OutOfMemoryError: Java heap space
3.栈
线程私有的,它的生命周期与线程相同,这块区域是为方法执行是准备的。每个方法执行时,都会创建一个栈帧(一种数据结构),专门用于用来存放方法中的局部变量(成员变量在堆区)如果线程请求的栈深度大于JVM允许的栈深度,将抛出StackOverflowError异常。
package com.wendao.student;
public class Student {
private static int age = 18; //age引用和18方法区
private String name = "张三"; //name引用都是放在堆区,张三在常量池。
public void say(){
int a = 1;//a 和 1 都存在 say的栈帧里,执行完就回收。
Object b = new Object();//b的引用存在say的栈帧里,实例放在堆。
System.out.println();//当代码执行到这里,栈空间会为这3个方法创建3个栈帧
}
public void introduce(){
say();
}
public static void main(String[] args) {
new Student().introduce();
}
}
public class TestStack {
private static int i = 1 ;
@Test
public void teststack(){
call();
}
public void call(){
System.out.println(i);
i ++ ;
call();
}
}
// 由于递归不停的调用自身,方法调用一次就产生一个栈帧,等到内存不够分配,就会出现栈溢出,错误提示:java.lang.StackOverflowError
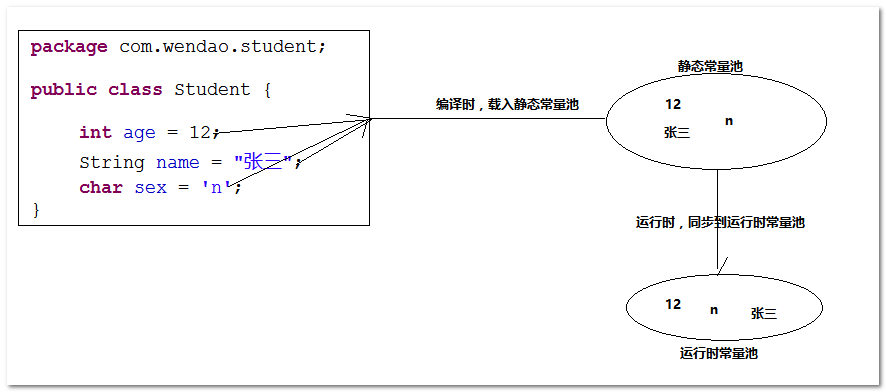
4.方法区中常量池
常量池:分为两种形态,静态常量池和运行时常量池。静态常量池:编译期间产生的内存空间,有些人叫class常量池,class常量池不仅仅存放字符串和数字等字面量数据,还存放类、方法的元数据信息。
运行时常量池:则是jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
①案例一
package com.wendao.student;
public class Student {
String s1 = "Hello";
String s2 = "Hello";
public void print() {
System.out.println(s1 == s2); // true
public static void main(String[] args) {
new Student().print();
}
}
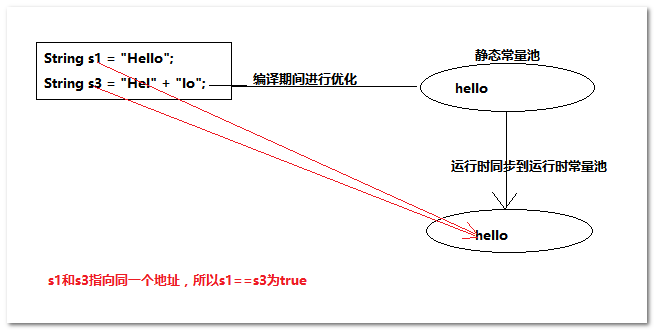
②案例二
package com.wendao.student;
public class Student {
public void print() {
String s1 = "Hello";
String s3 = "Hel" + "lo";
System.out.println(s1 == s3); // true
}
public static void main(String[] args) {
new Student().print();
}
}
s3虽然是动态拼接出来的字符串,但是在编译期间,这种拼接会被优化,编译器直接帮你拼好,因此s3在class文件中被优化成String s3 = "Hello";,所以s1 == s3成立。
注:可以用jad反编译查看,默认环境变量中是没有jad命令的,需要下载jad.exe然后放到jdk的bin目录下,点击下载
③案例三
package com.wendao.student;
public class Student {
public void print() {
String s1 = "Hello";
String s2 = "Hel" +new String("lo");
System.out.println(s1 == s2); // false
}
public static void main(String[] args) {
new Student().print();
}
}
s2虽然也是拼接出来的,但new String("lo")这部分不是已知字面量,是一个不可预料的部分,编译器不会优化,必须等到运行时才可以确定结果。

④案例四
package com.wendao.student;
public class Student {
public void print() {
String s1 = "Hello";
String s2 = "Hel";
String s3 = "lo";
String s4 = s2+s3;
System.out.println(s1 == s4); // false
}
public static void main(String[] args) {
new Student().print();
}
}
虽然s2、s3在赋值的时候使用的字符串字面量,但是拼接成s9的时候,s2、s3作为两个变量,都是不可预料的,编译器毕竟是编译器,不可能当解释器用,所以不做优化,等到运行时,s2、s3拼接成的新字符串,在堆中地址不确定,不可能与方法区常量池中的s1地址相同。s2+s3这种相加,本质是返回新的StringBuilder对象引用,该引用指向堆区,这也是为什么两个字符串相加会产生新的字符串对象。
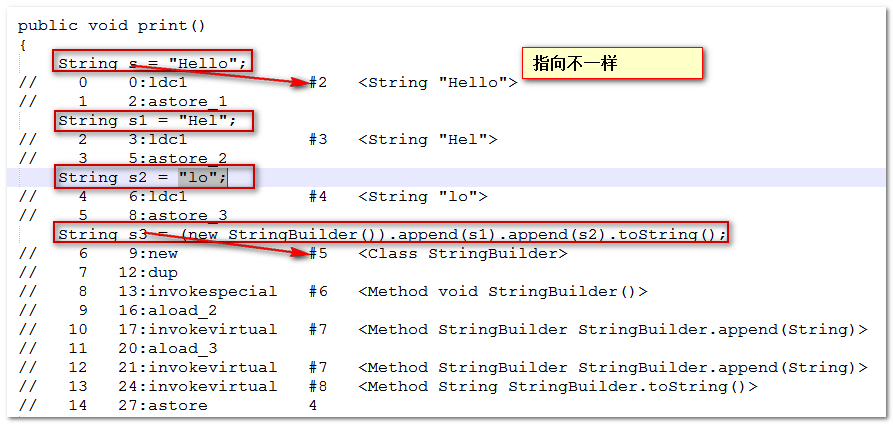
⑤案例五
package com.wendao.student;
public class Student {
public void print() {
String s1 = "Hello";
String s5 = new String("Hello");
String s6 = s5.intern();
System.out.println(s1 == s6); // true
}
public static void main(String[] args) {
new Student().print();
}
}
归功于intern方法,s5的对象在堆中,内容为Hello ,intern方法会尝试将Hello字符串添加到常量池中,并返回其在常量池中的地址,因为常量池中已经有了Hello字符串,所以intern方法直接返回地址;而s1在编译期就已经指向常量池了,因此s1和s6指向同一地址,相等。官方堆intern方法的解释:
当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串(用 equals(Object) 方法确定),则返回池中的字符串。否则,将此 String 对象添加到池中,并返回此 String 对象的引用。
⑥案例六
package com.wendao.student;
public class Student {
public static void main(String[] args) {
String param = "abc";
String param1 = "3abc";
String param2 = param.length() + "abc";
System.out.println(param1==param2);//false
}
}
param1指向常量池,param2指向堆区,即使内容一致,但是引用不一致所以为false
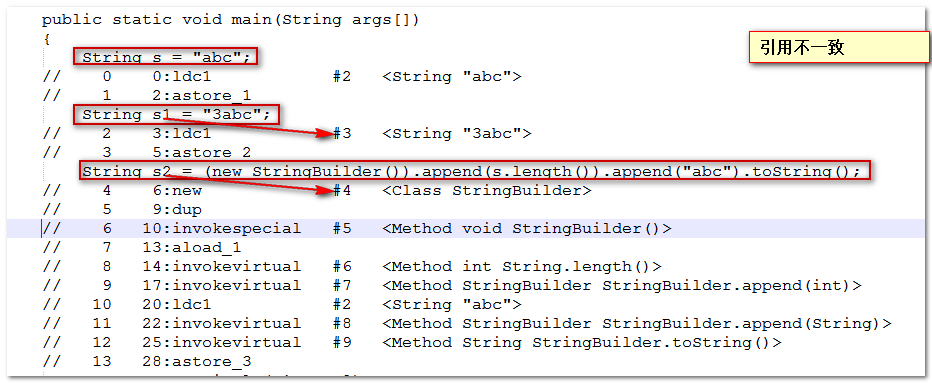
⑦结论:
1.必须要关注编译期的行为,才能更好的理解常量池。
2.运行时常量池中的常量,基本来源于各个class文件中的常量池。
3.程序运行时,除非手动向常量池中添加常量(比如调用intern方法),否则jvm不会自动添加常量到常量池。
5.堆区的新生代、老年代
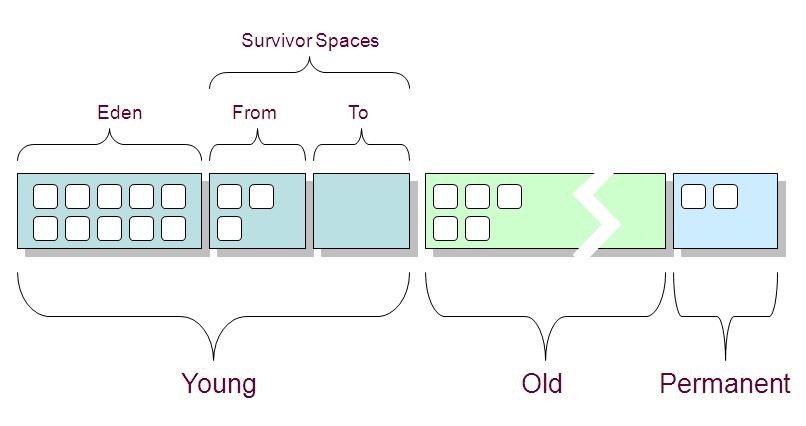
堆大小 = 新生代 + 老年代。默认下,新生代 ( Young ) = 1/3 的堆空间大小,老年代 ( Old ) = 2/3 的堆空间大小;
JDK8中废弃了永久代,替换为Metaspace元空间(本地内存中)
①堆区分代的原因
优化GC性能。如果没有分代,那么所有的对象都在一块,GC的时候要找到哪些对象没用就会对堆的所有区域进行扫描。
而很多对象都是朝生夕死的,如果分代的话,把新创建的对象放到某一地方,当GC的时候先把这块存“朝生夕死”对象的区域进行回收,这样就会腾出很大的空间出来。
②新生代特点
新生代 ( Young ) 被细分为 Eden 和 两个 Survivor 区域,这两个 Survivor 区域分别被命名为 from 和 to,以示区分。
默认的,Edem : from Survivor : to Survivor = 8 : 1 : 1;
JVM 每次只会使用 Eden 和其中的一块 Survivor 区域来为对象服务,所以无论什么时候,总是有一块 Survivor 区域是空闲着的。因此,新生代实际可用的内存空间为 9/10 ( 即90% )的新生代空间;
新生代GC(minor gc):指发生在新生代的垃圾回收动作,因为JAVA对象大多数都是朝生夕死(80%对象)的特性,所以minor gc非常频繁,使用复制算法快速的回收。
③老年代特点
存放"新生代"中生存了较长时间的对象,以及较大的对象。
内存空间比新生代要大。
垃圾回收的执行频率也会低很多。
老年代GC(major gc)----------指发生在老年代的垃圾回收动作,所采用是的标记--整理算法。
老年代几乎都是经过survivor熬过来的,它们是不会那么容易“死掉”,因此major gc不会像minor gc那样频繁。
④分代/堆模型
示例从一个object1来说明其在分代垃圾回收算法中的回收轨迹。
1、object1新建,出生于新生代的Eden区域

2、第一次minor GC,object1 还存活,移动到Fromsuvivor空间,此时还在新生代。

3、第二次minor GC,object1 仍然存活,此时会通过复制算法,将object1复制到ToSuv区域此时object1的年龄age+1。

4、第n次minor GC,object1 仍然存活,如果object1年龄为15直接进入老年代。当然还有一种情况要考虑,当object1年龄不足15,也有可能进入老年代。
如果survivor区内很多年龄不太大的对象怎么办呢,大家年龄都不足以进入老年代,但数量太多,survivor也吃不消啊。于是还有一条规则,就是survivor区内所有年龄相同的对象大小总和如果超过survivor区空间的一半,年龄大于等于该年龄的对象都直接进入老年代,不受参数MaxTenuringThreshold参数的限制了。

5、object1存活一段时间后,发现此时object1不可达GcRoots,而且此时老年代空间比率已经超过了阈值,触发了majorGC(也可以认为是fullGC,但具体需要垃圾收集器来联系),此时object1被回收了。fullGC会触发 stop the world。
总结:
在以上的新生代中,我们有提到对象的age,对象存活于survivor状态下,不会立即晋升为老年代对象,以避免给老生代造成过大的影响,它们必须要满足以下条件才可以晋升:
1、minor gc 之后,存活于survivor 区域的对象的age会+1,当超过(默认)15的时候,转移到老年代。
2、动态对象,如果survivor空间中相同年龄所有的对象大小的总和大于survivor空间的一半,直接进入老年代。
⑤GC类型以及促发条件
(1)分类:
针对HotSpot VM的实现,它里面的GC其实准确分类只有两大种:
- Partial GC:并不收集整个GC堆的模式
Old GC: 只收集old gen的GC。只有CMS的concurrent collection是这个模式
Mixed GC: 收集整个young gen以及部分old gen的GC。只有G1有这个模式
- Full GC: 收集整个堆,包括young gen、old gen、perm gen(如果存在的话)等所有部分的模式。
Young GC:当young gen中的eden区分配满的时候,或者说剩余内存小于即将new出来的对象的体积的时候触发。
Old GC: 当old gen区域分配满的时候
Full GC: 当准备要触发一次young GC时,如果发现统计数据说之前young GC的平均晋升大小比目前old gen剩余的空间大,则不会触发young GC而是转为触发full GC。