万维网工作过程
具体过程描述:
(1)鼠标点击链接后,客户端分析链接指向页面的URL
(2)客户端向DNS请求解析www.tsinghua.edu.cn的IP地址
(3)域名系统DNS解析出清华大学服务器的IP地址为166.111.4.100
(4)客户端与服务器建立TCP连接(在服务器端的端口号为80)
(5)客户端发出取文件命令:GET /chn/..
(6) 服务器www.tsinghua.edu.cn给出响应,把文件index.htm发送给客户端
(7)释放TCP连接
(8)浏览器上显示清华大学院系设置文件index.htm中的所有文本
HTTP工作流程

一次完整的HTTP请求事务包含以下四个环节:
建立起客户机和服务器连接。
建立连接后,客户机发送一个请求给服务器。
服务器收到请求给予响应信息。
客户端浏览器将返回的内容解析并呈现,断开连接。
HTTP协议结构
请求报文
对于请求报文,主要包含三部分,报文首部,空行(CR+LF),报文主体。如下图所示:
//GET例子 GET /56.jpg HTTP/1.1 //请求行 Host www.4399.com //主机的域名,完整的请求URI为www.4399.com/56.jpg User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36 Accept image/webp,image/*,*/*;q=0.8 Referer http://www.imooc.com/ Accept-Encoding gzip, deflate, sdch Accept-Language zh-CN,zh;q=0.8 //各种首部字段 //空行(CR+LF)
请求行
包含用于请求的方法,请求URI和HTTP版本
结构:method URI version
method
HTTP的请求方法,一共有9种,但GET和POST占了99%以上的使用频次。
GET方法用来请求访问已被URI识别的资源,指定的资源经服务器端解析后返回相应内容。
POST通常用于向指定资源提交数据进行处理,提交的数据被包含在请求体中,相对而言比较安全些。
URI
统一资源标识符,用字符串标识某一互联网资源。(附二,介绍URL和URI区别)
version
HTTP协议的版本,该字段有HTTP/1.0和HTTP/1.1两种。
各种首部字段
在HTTP/1.1中,请求头除了Host都是可选的。包含的头五花八门,这里只介绍部分。
Host:指定请求资源的主机(资源主机的域名)和端口号。端口号默认80。
Connection:值为keep-alive和close。keep-alive使客户端到服务器的连接持续有效,不需要每次重连,此功能为HTTP/1.1预设功能。close即服务器发送完请求的文档后就可释放连接。
Accept:浏览器可接收的MIME类型。假设为text/html表示接收服务器回发的数据类型为text/html,如果服务器无法返回这种类型,返回406错误。
Cache-control:缓存控制,Public内容可以被任何缓存所缓存,Private内容只能被缓存到私有缓存,non-cache指所有内容都不会被缓存。
Cookie:将存储在本地的Cookie值发送给服务器,实现无状态的HTTP协议的会话跟踪。
Content-Length:请求消息正文长度。
另有User-Agent、Accept-Encoding、Accept-Language、Accept-Charset、Content-Type等请求头这里不一一罗列。由此可见,请求报文是告知服务器请求的内容,而请求头是为了提供服务器一些关于客户机浏览器的基本信息,包括编码、是否缓存等。
空行(一行)
报文主体(多行)
响应报文
响应报文是服务器对请求资源的响应,主要也包含三部分,报文首部,空行(CR+LF),报文主体。如下图所示:
//响应例子 HTTP/1.1 200 OK //请求行 Date: Fri, 22 May 2009 06:07:21 GMT Content-Type: text/html; charset=UTF-8 //各种首部字段 //空行(CR+LF) <html> //报文主体 <head></head> <body> <!--body goes here--> </body> </html>
请求行(一行)
结构:version status_code status_message
version
描述所遵循的HTTP版本。
status_code
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息--表示接收的请求正在处理
2xx:成功--表示请求正常处理完毕
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器处理请求出错
状态码,指明对请求处理的状态,常见的如下。
200:成功。
204:请求处理成功,但没有资源可返回(即浏览器显示的页面无变化)
206:表示客户端进行 了范围请求,而服务器成功执行了这部分的GET请求。
301:永久重定向,请求的资源已被分配新的URI。
302:临时重定向,请求的资源已被分配了新的URI,希望用户(本次)能使用新的URI访问。
303:请求对应的资源存在着另一个URI,应使用GET方法定向获取请求的资源。
304:客户端发送附带条件的请求时,资源已找到,但未符合条件请求。304和重定向没有关系。
400:请求不能被服务器理解。
401:发送的请求需要有通过HTTP认证的认证信息。
403:无权访问该资源。
404:不能找到请求的资源。
500:服务器内部错误。
501:服务器不支持请求的方法。
503:服务器暂时处于超负载或正在进行停机维护。
505:服务器不支持请求的版本。
status_message
显示和状态码等价英文描述。
各种首部字段
这里只罗列部分。
Date:表示信息发送的时间。
Server:Web服务器用来处理请求的软件信息。
Content-Encoding:Web服务器表明了自己用什么压缩方法压缩对象。
Content-Length:服务器告知浏览器自己响应的对象长度。
Content-Type:告知浏览器响应对象类型。
空行(一行)
报文主体(多行)
实际有效数据,通常是HTML格式的文件,该文件被浏览器获取到之后解析呈现在浏览器中。
附一:
各种协议与HTTP协议的关系
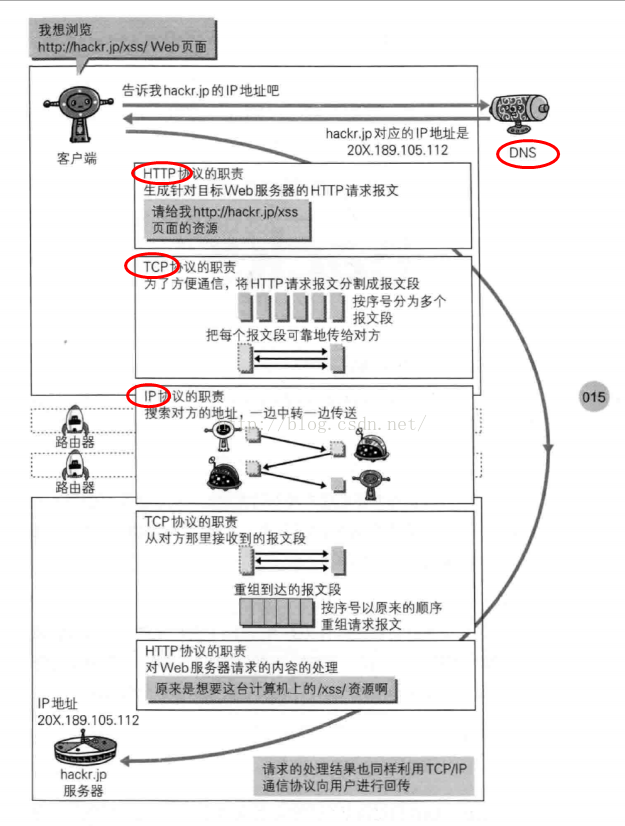
附二:
URL和URI区别
URI为统一资源标识符,用字符串标识某一互联网资源,而URL为统一资源定位符,表示资源的地点(互联网上所处的位置),URL是URI的子集。
附三:
HTTP1.0 HTTP 1.1主要区别
长连接
HTTP 1.0需要使用keep-alive参数来告知服务器端要建立一个长连接,而HTTP1.1默认支持长连接。
HTTP是基于TCP/IP协议的,创建一个TCP连接是需要经过三次握手的,有一定的开销,如果每次通讯都要重新建立连接的话,对性能有影响。因此最好能维持一个长连接,可以用个长连接来发多个请求。
节约带宽
HTTP 1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,否则返回401。客户端如果接受到100,才开始把请求body发送到服务器。
这样当服务器返回401的时候,客户端就可以不用发送请求body了,节约了带宽。
另外HTTP还支持传送内容的一部分。这样当客户端已经有一部分的资源后,只需要跟服务器请求另外的部分资源即可。这是支持文件断点续传的基础。
3.HOST域
现在可以web server例如tomat,设置虚拟站点是非常常见的,也即是说,web server上的多个虚拟站点可以共享同一个ip和端口。
HTTP1.0是没有host域的,HTTP1.1才支持这个参数。
附四:
HTTP1.1 HTTP 2.0主要区别
1.多路复用
HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。
当然HTTP1.1也可以多建立几个TCP连接,来支持处理更多并发的请求,但是创建TCP连接本身也是有开销的。
TCP连接有一个预热和保护的过程,先检查数据是否传送成功,一旦成功过,则慢慢加大传输速度。因此对应瞬时并发的连接,服务器的响应就会变慢。所以最好能使用一个建立好的连接,并且这个连接可以支持瞬时并发的请求。
数据压缩
HTTP1.1不支持header数据的压缩,HTTP2.0使用HPACK算法对header的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
服务器推送
意思是说,当我们对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。
服务器端推送的这些资源其实存在客户端的某处地方,客户端直接从本地加载这些资源就可以了,不用走网络,速度自然是快很多的。
附五:
GET和POST区别
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.