首先是把yolov8的onnx模型转成rknn模型,这里用的是yolov8n-seg.
转模型代码如下,这段是python代码:
if __name__ == '__main__':
platform = 'rkXXXX' #写自己的型号
exp = 'yolov8n_seg'
Width = 640
Height = 640
MODEL_PATH = './onnx_models/yolov8n-seg.onnx'
NEED_BUILD_MODEL = True
# NEED_BUILD_MODEL = False
im_file = './dog_bike_car_640x640.jpg'
# Create RKNN object
rknn = RKNN(verbose=False)
OUT_DIR = "rknn_models"
RKNN_MODEL_PATH = '{}/{}.rknn'.format(OUT_DIR,exp)
if NEED_BUILD_MODEL:
DATASET = './dataset.txt'
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform="rkXXXX")
# Load model
print('--> Loading model')
ret = rknn.load_onnx(MODEL_PATH)
if ret != 0:
print('load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset=DATASET)
if ret != 0:
print('build model failed.')
exit(ret)
print('done')
# Export rknn model
if not os.path.exists(OUT_DIR):
os.mkdir(OUT_DIR)
print('--> Export RKNN model: {}'.format(RKNN_MODEL_PATH))
ret = rknn.export_rknn(RKNN_MODEL_PATH)
if ret != 0:
print('Export rknn model failed.')
exit(ret)
print('done')
else:
ret = rknn.load_rknn(RKNN_MODEL_PATH)
rknn.release()
运行成功之后会得到yolov8n_seg.rknn模型。
往下是cpp代码。
运行rknn模型,不是零copy的话用这段代码。
//设置outputs数组保存结果
rknn_output outputs[io_num.n_output]; //长度为2的数组
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++) {
outputs[i].want_float = 0;
}
ret = rknn_run(ctx, NULL); //运行rknn模型
//这里不是零copy方法,需要用到rknn_outputs_get函数
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
零copy方法用这段代码。
ret = rknn_run(ctx, nullptr);
memcpy(y0, output_mems[0]->virt_addr, output_attrs[0].n_elems * sizeof(char)); //outputs[0]copy到y0
memcpy(y1, output_mems[1]->virt_addr, output_attrs[1].n_elems * sizeof(char));
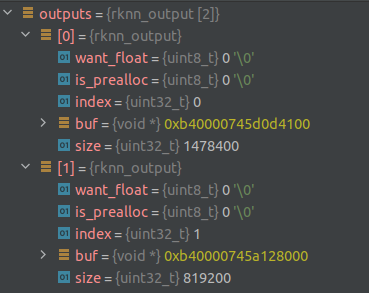
下面来看下rknn模型运行结果outputs的结构。
具体这个结果怎么来的以及详细含义的请参考此处。
outputs的size为2,其中outputs[0]的size是8400*176,8400是box个数,
176包含了3个部分,64是box坐标,80是类别prob, 32是mask coeff.
outputs[1]是proto_type, size为32 * 160 * 160.
want_float是这个结果是否输出为float,这里设0表示还是int输出,后面再反量化。
数据部分保存在buf里,它是(void*), 用的时候cast到(int8_t*).
现在需要写后处理,通过outputs得到目标框和mask.
主要思路如下:
1. 反量化
rknn模型输出的是量化过后的int8_t型,而计算时需要反量化成float型,
先看看rknn模型是怎么量化的。
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
//rknn_query:查询模型与sdk的相关信息
//output_attrs:存放返回结果的结构体变量
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
dump_tensor_attr(&(output_attrs[i]));
}
dump结果如下,可以看到模型输出的type为int8, 量化用的是affine变换,
也就是 output / scale + zp.

那么反量化时就需要 (output - zp) * scale
//反量化计算
static float deqnt_affine_to_f32(int8_t qnt, int32_t zp, float scale) {
return ((float)qnt - (float)zp) * scale; }
2. box部分
8400 * 176, 其中8400是box个数,176包含了3个部分,64是box坐标,80是类别prob, 32是mask coeff.
8400个box部分取出每个box的80个类别prob, 选出最大的类别prob就是这个box的label,
类别prob > 阈值时说明有效,
每176的向量中前64个数据,每16个一组,一共4组,可得到box的(l,t,r,b).
用8400个anchor的中心点与(l,t,r,b)运算可得到box的(x0, y0, x1, y1).
另外把每个box的32维mask coeff保存起来。
注意判断类别prob是否 > 阈值时,要先把类别prob做反量化。
for (int i = 0; i < box_num; i++) {
//遍历8400个box
...
// find label with max score
int label = -1;
float score = -FLT_MAX;
//找到最大score和对应的label
for (int k = 0; k < num_class; k++) //80个类别prob
{
float confidence = deqnt_affine_to_f32(score_ptr[k], zp, scale); //反量化,int转float
if (confidence > score)
{
label = k;
score = confidence;
}
}
float box_prob = sigmoid(score);
if (box_prob >= prob_threshold){
...
softmax(bbox_pred); //对4x16中的每16个一组求softmax,因为作了softmax,就不再需要对每个数据作反量化
...
//anchor中心点
float pb_cx = (grid_strides[i].grid0 + 0.5f) * grid_strides[i].stride;
float pb_cy = (grid_strides[i].grid1 + 0.5f) * grid_strides[i].stride;
float x0 = pb_cx - pred_ltrb[0]; //center_x - l
float y0 = pb_cy - pred_ltrb[1]; //center_y - t
float x1 = pb_cx + pred_ltrb[2]; //center_x + r
float y1 = pb_cy + pred_ltrb[3]; //center_y + b
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = label;
obj.prob = box_prob;
obj.mask_feat.resize(32);
std::copy(bbox_ptr + 64 + num_class, bbox_ptr + 64 + num_class + 32, obj.mask_feat.begin());
objects.push_back(obj);
}
}
上面是用类别prob的阈值过滤了第一波box,
然后还要用nms再过滤一波。
nms_sorted_bboxes(proposals, picked, nms_threshold); //picked里面保存的是proposals的下标
3. mask部分
mask由mask_coeff 和 proto_type进行矩阵乘得到。
mask_coeff保存在上面objects中每个obj的mask_feat里面。
注意上面的mask_feat还没有作反量化。
outputs[1]是数据开头的指针,
为了方便后面的矩阵乘,resize等操作,需要把它转为cv::Mat.
注意如果是int8型的Mat,它会自动把数值限制到[0,255],
而显然mask_feat里面是有负数的,所以要用float型的Mat.
先把nms挑选出来的目标的mask_coeff转为Mat。然后作反量化计算。
//mask_feat里面保存每个目标的mask coeff
cv::Mat mask_feat_qnt(count, 32, CV_32FC1); //float型的Mat, count为nms后目标的个数
for (int i = 0; i < count; i++) {
float* mask_feat_ptr = mask_feat_qnt.ptr<float>(i); //指向第i行的指针
std::memcpy(mask_feat_ptr, proposals[picked[i]].mask_feat.data(), sizeof(float) * proposals[picked[i]].mask_feat.size());
}
//因为mask_feat从outputs[0]中得到,所以用zps[0],scales[0]作反量化
cv::Mat mask_feat = (mask_feat_qnt - out_zps[0]) * out_scales[0];
把proto_type转为cv::Mat. proto_type中的值也要进行反量化计算。
cv::Mat proto = cv::Mat(32, 25600, CV_32FC1, proto_arr);
mask_coeff 和 proto_type 矩阵乘,得到目标的mask.
cv::Mat mulResMask = (mask_feat * proto).t(); //(n,32)*(32,25600)=n*25600,必须加转置,不加的话mask会很奇怪
cv::Mat masks = mulResMask.reshape(count, {
160, 160}); //每个目标有一个160*160的mask
std::vector<cv::Mat> maskChannels;
cv::split(masks, maskChannels); //把count个mask分割开,每个目标的mask保存为vector的一个元素
把每个目标的box, mask保存到结果objects中。
std::vector<Object> objects;
objects.resize(count); //保存结果的object
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]];
// adjust offset to original unpadded
float x0 = (objects[i].rect.x - (wpad / 2)) / scale;
float y0 = (objects[i].rect.y - (hpad / 2)) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width - (wpad / 2)) / scale;
float y1 = (objects[i].rect.y + objects[i].rect.height - (hpad / 2)) / scale;
// clip
x0 = std::max(std::min(x0, (float)(img_width - 1)), 0.f);
y0 = std::max(std::min(y0, (float)(img_height - 1)), 0.f);
x1 = std::max(std::min(x1, (float)(img_width - 1)), 0.f);
y1 = std::max(std::min(y1, (float)(img_height - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
//计算mask并保存到object
cv::Mat dest, mask;
cv::exp(-maskChannels[i], dest); //每个mat单独计算sigmoid
dest = 1.0 / (1.0 + dest); //160x160的mask
dest = dest(roi); //取rect区域
cv::resize(dest, mask, cv::Size(img_width, img_height), cv::INTER_NEAREST);
//crop
cv::Rect tmp_rect = objects[i].rect;
mask = mask(tmp_rect) > 0.5; //mask阈值设为0.5
objects[i].mask = mask;
}
效果如下:

完整版代码放在github的semantic。