RESTful API 的存在是 web 开发历史上的一个里程碑。在本文中,我将和你探讨几种节省 REST API 开发时间的方法,并给出相关的 Node.js 示例。
什么是 RESTful API
首先,想问一个问题,你的项目里真的有真正的 RESTful API 吗?
如果你认为你的项目有 RESTful API,那么你很可能错了。RESTful API 背后的思想是遵循REST 规范中描述的所有架构规则和限制的方式进行开发。然而,实际上,这在实践中基本上是不可能的。
一方面,REST 包含了太多模糊和模棱两可的定义。例如,在实践中,HTTP 方法和状态码中的一些术语的使用与其预期目的相反,或者根本不使用。
另一方面,REST 开发产生了太多的限制。例如,对于在移动应用程序中使用的实际 api,原子资源的使用是次优的。再如,完全拒绝请求之间的数据存储实质上禁止了随处可见的“用户会话”机制。
不过,我想说,也没你想的那么糟糕!
REST API 规范能做什么?
尽管存在上面说到的缺点,但使用合理的方法,REST 仍然是创建真正优秀 api 的一个绝佳选择。因为你通过高质量的 API 规范实现的 api 将会是一致的,具有清晰的结构、良好的文档和高的单元测试覆盖率。
通常,REST API规范与其文档相关联。
正确的 API 描述不仅仅是编写好 API 文档。在这篇文章中,我想分享一些例子,教你如何做到:
- 单元测试更简单、更可靠;
- 用户输入的预处理和验证;
- 自动序列化,确保响应一致性;
- 静态类型
但首先,让我们从 API 规范开始。
OpenAPI 规范
OpenAPI 是目前最广泛接受的 REST API 规范格式。该规范以 JSON 或 YAML 格式编写在单个文件中,由三个部分组成:
- 带有 API 名称、描述和版本以及任何附加信息的标头。
- 所有资源的描述,包括标识符、HTTP 方法、所有输入参数、响应代码和主体数据类型,以及指向定义的链接。
- 所有可用于输入或输出的定义,以 JSON 模式格式。
不过,OpenAPI 的结构有两个明显的缺点:过于复杂和冗余。例如,一个小项目就可以产生数千行 JSON 规范。手动维护该文件变得有些难。这对开发者来说是一个威胁。
虽然有许多解决方案,如 Swagger、Apiary、stolight、Restlet。但,这些服务对我来说是不方便的,因为需要快速编辑规范并将其与代码更改对齐。
Tinyspec 规范
在本文中,我将使用基于 tinyspec 规范定义 API。tinyspec 定义的 API 是由具有直观语法的小文件组成,这些文件描述了项目中使用的数据模型。同时,这些文件就放置在代码文件旁边,能够在编写代码的时候提供快速的参考。除此之外,Tinyspec 还能够被自动编译成一个成熟的 OpenAPI 格式,可以立即在项目中使用。
API规范的基石
上面的内容中,我们介绍了一些背景知识。现在,我们可以开始探索如何充分利用它们进行 API 的编写。
1. 为 API 编写单元测试
行为驱动开发(BDD)是开发 REST api 的理想选择。最好不是为单独的类、模型或控制器编写单元测试,而是为特定的 API 编写单元测试。在每个测试中,模拟一个真实的 HTTP 请求并验证服务器的响应。例如,在 Node.js 的单元测试中,用于模拟请求的有 supertest 和 chai-http包。
现在,假设我们有一个 user.models 和一个返回所有 users 的 GET /users 端点。下面我们就用 tinyspec 语法来描述它:
# user.models.tinyspec
User {name, isAdmin: b, age?: i}
# users.endpoints.tinyspec
GET /users
=> {users: User[]}
接着,我们编写相应的测试:
- Node.js:
describe('/users', () => {
it('List all users', async () => {
const {
status, body: {
users } } = request.get('/users');
expect(status).to.equal(200);
expect(users[0].name).to.be('string');
expect(users[0].isAdmin).to.be('boolean');
expect(users[0].age).to.be.oneOf(['boolean', null]);
});
});
上述测试中,我们测试了服务器的返回值,是否遵循规范。不过这一过程似乎有些冗余。为了简化过程,我们可以使用 tinyspec 模型,每个模型都可以转换为遵循 JSON Schema 格式的OpenAPI 规范。
做之前,你首先需要生成 OpenAPI,请执行如下命令:
tinyspec -j -o openapi.json
接着,你可以在项目中使用生成的 JSON 并从中获取定义键。该键包含所有的 JSON 模型。模型可能包含交叉引用($ref),因此,如果你有任何嵌入式的模型(例如,Blog {posts: Post[]}),则需要将它们展开,以便在验证中使用。为此,我们将使用 json-schema-def-sync这个包帮助我。
import deref from 'json-schema-deref-sync';
const spec = require('./openapi.json');
const schemas = deref(spec).definitions;
describe('/users', () => {
it('List all users', async () => {
const {
status, body: {
users } } = request.get('/users');
expect(status).to.equal(200);
// Jest
expect(users[0]).toMatchSchema(schemas.User);
});
});
如果你的 IDE 支持运行测试和调试,以这种方式编写测试非常方便。这个时候,整个 API 开发周期被限制为三个步骤:
- 在 tinyspec 文件中设计规范。
- 为 API 编写完整的测试。
- 实现满足测试的代码。
2. 验证输入数据
OpenAPI 不仅描述了响应格式,还描述了输入数据。这允许你在运行时验证用户发送的数据是否一致,以及数据库能够安全地进行更新。
假设我们有以下规范,它描述了对用户信息的更新:
# user.models.tinyspec
UserUpdate !{name?, age?: i}
# users.endpoints.tinyspec
PATCH /users/:id {user: UserUpdate}
=> {success: b}
接着,让我们使用 Koa.js 针对这个规范来写一个带有验证的控制器:
import Router from 'koa-router';
import Ajv from 'ajv';
import {
schemas } from './schemas';
const router = new Router();
router.patch('/:id', async (ctx) => {
const updateData = ctx.body.user;
// 验证
await validate(schemas.UserUpdate, updateData);
const user = await User.findById(ctx.params.id);
await user.update(updateData);
ctx.body = {
success: true };
});
async function validate(schema, data) {
const ajv = new Ajv();
if (!ajv.validate(schema, data)) {
const err = new Error();
err.errors = ajv.errors;
throw err;
}
}
在本例中,如果输入与规范不匹配,服务器将返回 500 Internal server Error 响应。为了避免这种情况,我们可以捕获验证器错误并形成我们自己的返回,该返回将包含有关验证失败的特定字段的更详细信息,并遵循规范。
接着,让我们添加 FieldsValidationError 的定义:
# error.models.tinyspec
Error {error: b, message}
InvalidField {name, message}
FieldsValidationError < Error {fields: InvalidField[]}
现在让我们把它列为可能的 endpoints 响应之一:
# users.endpoints.tinyspec
PATCH /users/:id {user: UserUpdate}
=> 200 {success: b}
=> 422 FieldsValidationError
此时,当客户端发送了无效数据时,我们的便能 catch 到正确的错误信息。
3.模型序列化
几乎所有现代服务器框架都以这样或那样的方式使用对象关系映射(ORM)。这意味着 API 使用的大部分资源是由模型及其实例和集合表示的。
我们把要在响应中发送的这些实体形成 JSON 表示的过程称为序列化。
有许多用于序列化的插件:例如,sequealize-to-json。基本上,这些插件允许你为必须包含在 JSON 对象中的特定模型提供字段列表,以及附加规则。例如,你可以重命名字段并动态计算它们的值。
不过,当一个模型需要几个不同的 JSON 表示,或者当对象包含嵌套的实体关联时,就比较复杂了。这个时候,你可能会开始通过继承、重用和序列化器链接等特性来解决这些问题。
虽然有不同的解决方案,但让我们思考一下: 规范能否再次为这些场景提供帮助?
这个时候,我想向你推荐一个构建序列化的 npm 模块: Sequelize-serialize,它支持对 Sequelize模型执行相应的操作。例如,它接受一个模型实例或一个数组,以及所需的模式,然后遍历它以构建序列化的对象。
因此,假设我们需要从 API 返回博客中有帖子的所有用户,包括对这些帖子的评论。我们就可以通过以下规范描述它:
# models.tinyspec
Comment {authorId: i, message}
Post {topic, message, comments?: Comment[]}
User {name, isAdmin: b, age?: i}
UserWithPosts < User {posts: Post[]}
# blogUsers.endpoints.tinyspec
GET /blog/users
=> {users: UserWithPosts[]}
现在我们可以使用 Sequelize 构建请求,并返回与上述规范完全对应的序列化对象:
import Router from 'koa-router';
import serialize from 'sequelize-serialize';
import {
schemas } from './schemas';
const router = new Router();
router.get('/blog/users', async (ctx) => {
const users = await User.findAll({
include: [{
association: User.posts,
required: true,
include: [Post.comments]
}]
});
ctx.body = serialize(users, schemas.UserWithPosts);
});
4. 静态类型
你可能会继续发问:“静态类型怎么办?”
我会向你推荐使用 sw2dts 或 swagger-to-flowtype 模块,你可以基于 JSON 模型生成所有必要的静态类型,并在测试、控制器和序列化器中使用它们:
tinyspec -j
sw2dts ./swagger.json -o Api.d.ts --namespace Api
现在我们可以在控制器中使用类型和测试:
router.patch('/users/:id', async (ctx) => {
// 指定请求数据的类型
const userData: Api.UserUpdate = ctx.request.body.user;
await validate(schemas.UserUpdate, userData);
// 查询数据库
const user = await User.findById(ctx.params.id);
await user.update(userData);
// 返回序列化结果
const serialized: Api.User = serialize(user, schemas.User);
ctx.body = {
user: serialized };
});
让我们进行一些测试:
it('Update user', async () => {
// 静态类型检查
const updateData: Api.UserUpdate = {
name: MODIFIED };
const res = await request.patch('/users/1', {
user: updateData });
const user: Api.User = res.body.user;
expect(user).to.be.validWithSchema(schemas.User);
expect(user).to.containSubset(updateData);
});
请注意,生成的类型定义不仅可以在 API 项目中使用,还可以在客户端应用程序项目中使用,以描述与 API 一起工作的函数中的类型。
5. 强制转换查询字符串类型
如果你的 API 由于某种原因使用 application/x-www-form-urlencoded MIME类型而不是 application/json 来处理请求,请求体将看起来像这样:
param1=value¶m2=777¶m3=false
在这种情况下,web 服务器将无法自动识别类型,此时所有数据将是字符串格式,所以解析后你将得到这个对象:
{
param1: 'value', param2: '777', param3: 'false' }
在这种情况下,请求将无法通过模型验证,因此你需要手动验证正确的参数格式,并将其转换为正确的类型。
不过我们可以通过规范来验证。假设我们有如下的 endpoints 和 models:
# posts.endpoints.tinyspec
GET /posts?PostsQuery
# post.models.tinyspec
PostsQuery {
search,
limit: i,
offset: i,
filter: {
isRead: b
}
}
下面是对这个 endpoints 的请求:
GET /posts?search=needle&offset=10&limit=1&filter[isRead]=true
接着,让我们编写 castQuery 函数,将所有参数强制转换为所需的类型:
function castQuery(query, schema) {
_.mapValues(query, (value, key) => {
const {
type } = schema.properties[key] || {
};
if (!value || !type) {
return value;
}
switch (type) {
case 'integer':
return parseInt(value, 10);
case 'number':
return parseFloat(value);
case 'boolean':
return value !== 'false';
default:
return value;
}
});
}
现在让我们在代码中使用它:
router.get('/posts', async (ctx) => {
// 转换类型
const query = castQuery(ctx.query, schemas.PostsQuery);
// 验证规范
await validate(schemas.PostsQuery, query);
// 查询数据库
const posts = await Post.search(query);
// 返回序列化结果
ctx.body = {
posts: serialize(posts, schemas.Post) };
});
最佳实践
OK,介绍了以上内容之后,让我们来做一下遵循规范的最佳实践。
使用单独的创建和编辑模型
通常,描述服务器响应的模型与描述用于 New 和 Update 模型的输入的模型不同。例如,POST 和PATCH 请求中可用的字段列表必须严格限制,PATCH 通常将所有字段标记为可选。描述响应的模型可以更加自由。
当你自动生成 CRUDL 端点时,tinyspec 使用 New 和 Update 后缀。用户模型可以通过以下方式定义:
User {id, email, name, isAdmin: b}
UserNew !{email, name}
UserUpdate !{email?, name?}
遵循模型命名约定
对于不同的端点,相同模型的内容可能会有所不同。在模式名称中使用 With* 和 For* 后缀来显示差异和目的。在 tinyspec 中,模型也可以相互继承。例如:
User {name, surname}
UserWithPhotos < User {photos: Photo[]}
UserForAdmin < User {id, email, lastLoginAt: d}
这样的名称能够反映模型的作用,并使文档更易于阅读。
基于客户端类型分离端点
通常,相同的端点会根据客户端类型或发送请求的用户角色返回不同的数据。例如,对于移动应用程序用户和后台管理人员来说,GET /uses 端点可能存在很大的不同。
因此,如果要多次描述同一端点,可以在路径后面的括号中添加其类型。例如:
Mobile app:
GET /users (mobile)
=> UserForMobile[]
CRM admin panel:
GET /users (admin)
=> UserForAdmin[]
REST API 文档工具
在获得 tinyspec 或 OpenAP I格式的规范后,可以生成 HTML 格式的美观文档并发布它。这将使使用你的 API 的开发人员感到轻松,并且肯定比手工填写 REST API 文档模板要好。
下面是一些文档工具:
- Bootprint-openapi (在 tinyspec 中默认使用)
- swagger2markup-cli (jar,有一个用法示例,将在 tinyspec Cloud 中使用)
- redoc-cli
- widdershins
遗憾的是,尽管发布一年了,OpenAPI 3.0 的支持仍然很差,tinyspec 还不支持 OpenAPI 3.0。
在GitHub上发布
发布文档的最简单方法之一是GitHub Page。只需在存储库设置中为 /docs 文件夹启用对静态页面的支持,并将 HTML 文档存储在此文件夹中即可。
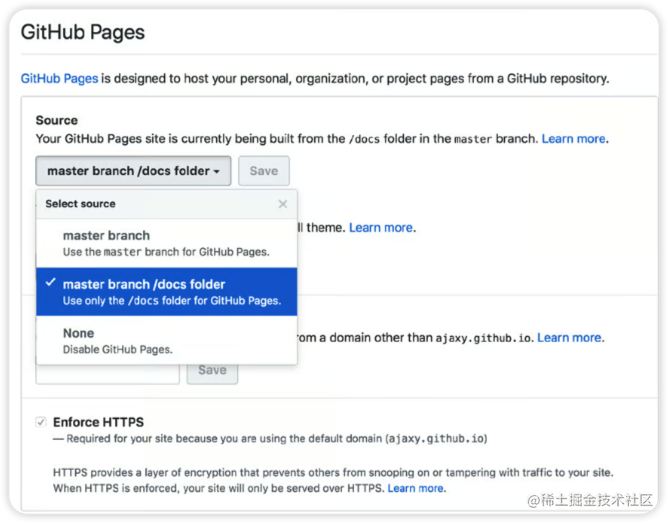
同时,你可以在 scripts/package.json 中添加命令来通过 tinyspec 或其他 CLI 工具生成文档:
"scripts": {
"docs": "tinyspec -h -o docs/",
"precommit": "npm run docs"
}
最后
REST API 开发可能是现代 web 开发和移动端开发中最令人愉快的过程之一。因为它的开发过程没有浏览器、操作系统和屏幕大小的限制,一切都完全在你的控制之下。如果你想让你的 REST API 更具规范,不妨试试文中提到的。
点赞、收藏、加关注,我们下篇文章再见~