原论文:Personalized Re-ranking for Recommendation
一、创新点
1、为了解决推荐系统排序全局最优解的问题,文章对重排模块进行了较为详细的介绍
2、在重排序部分,文章提出了基于Transformer结构的个性化重排序模型,显著提升了线上系统的曝光、点击、GMV等指标。
3、使用listwise的思想对整个序列进行 优化。
二、论文背景
前面的文章已经介绍过了,推荐系统的架构大致分为如下几个模块:召回、粗排、精排、重排,那么为什么要引入重排模块呢。在精排阶段,我们希望得到的是一个候选排序队列的全局最优解,但是实际上,通常在精排阶段,我们精排模型是针对用户和每一个候选广告(商品)输出一个分值;而每个候选之间也会相互影响。例如在360搜索广告的场景下,这些候选广告之间的广告样式会互相影响,从而影响最终的排序结果(一些图片类型的广告的点击率通常要比纯文字链广告的点击率要高),所以在360搜索广告的场景下,重排序模块主要在考虑同屏展现广告样式相关的一些信息,利用这些信息对精排候选广告队列进行一个重新的排序。
三、PRM模型详解
整个模型结构如下图所示
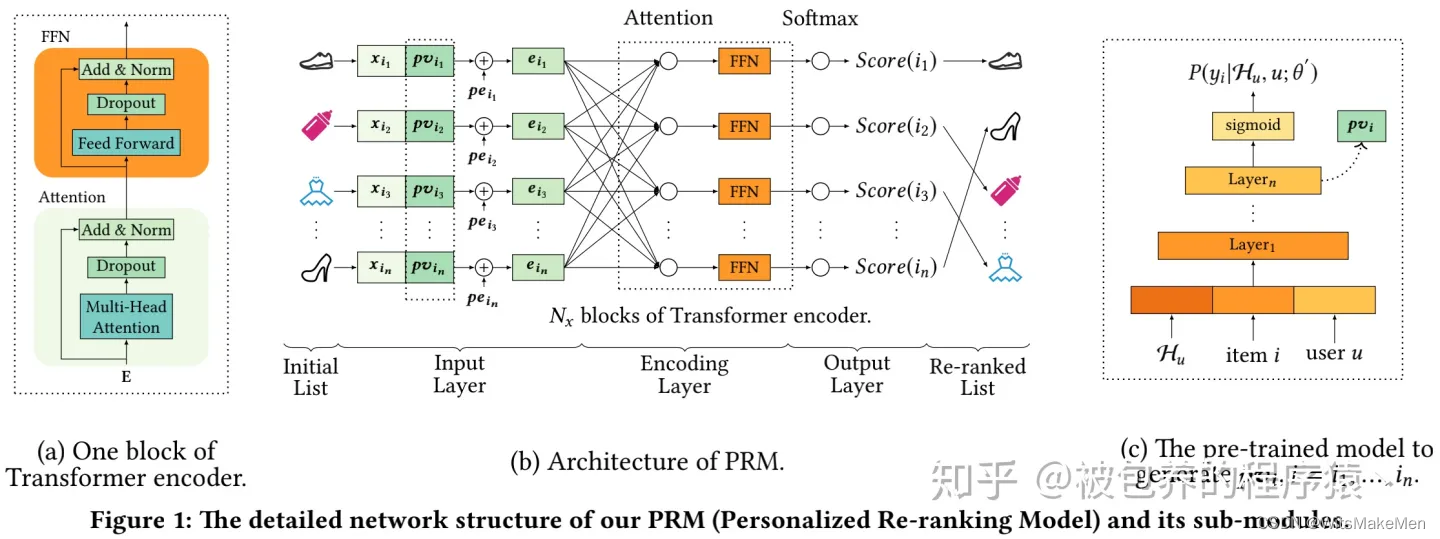
图1 PRM模型结构
整个PRM模型包括三个部分,Input Layer、Encoding Layer和Output Layer。
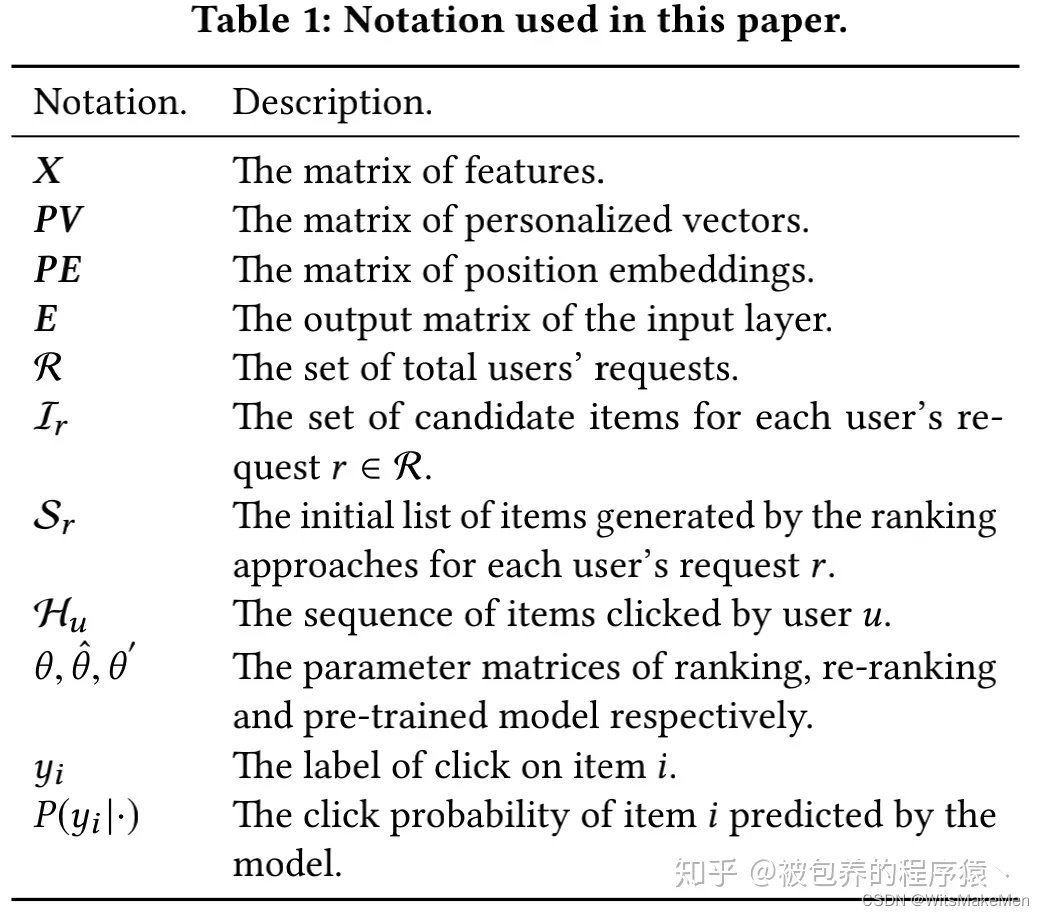
论文参数
1、Input Layer
Input Layer的作用比较好理解,就是对精排阶段的候选广告列表进行一个Embedding表征,得到Embedding向量之后喂给后续的Encoding Layer。Input Layer的原始输入是精排广告序列的原始特征矩阵X。在此基础上,主要引入Personalized Vector(PV)和Position Embedding(PE)。如果只将候选广告的原始特征矩阵X喂给Encoding Layer,则模型只会获取到候选商品之间的交互信息,为了引入商品-用户之间的交互信息,则引入了Personalized Vector;Position Embedding则主要是引入精排阶段ranking order的相关信息。所以最后最终的Embedding矩阵如下
原始特征和个性化特征做concate,然后在加上position偏置项。最后将上述Embedding经过一个单层的前向网络得到Input Layer的输出。
那么如何对PV进行建模呢,这里文章给出了两个办法,一种是将PV融入到PRM模型中做端到端的训练,另外一种是采用一个额外的模型进行预训练得到PV的Embedding Vector,文章采用的是后一种方法。这里文章也给出了解释(如下图),可以理解为第一中方法只能挖掘用户-精排候选item之间的交互信息,但是实际上我们这里需要的是用户更加泛化通用的embedding表征,所以利用一个单独的预训练的模型(也可以用简化版的精排模型),但是我觉得采用端到端的训练方式和预训练的方式两者之间的差距还需要进一步评估,具体两者差距多少持保留态度。具体预训练模型的结构如图1右侧部分所示,就是一个简单的MLP,这里也就不做过多介绍了,值得一提的是,为了更好的表征用户个性化的信息,在这个预训练部分引入了一些用户历史行为特征、用户基础特征(年龄、性别)、item特征这三类。

2、Encoding Layer
Encoding Layer的作用就是将Input Layer输出的Embedding信息进行高阶信息的交叉,而单层Encoding Layer的结构包括一个multi-head self-attention和一个前向网络(具体参考图1最左侧的部分)。具体multi-head self-attention和transformer相关的内容在这里就不做过多的介绍了,感兴趣的小伙伴可以参考之前的几篇博文进行了解。
这里为什么要用self-attention这种结构呢,因为在重排序阶段需要考虑的是候选广告之间的相互影响(item之间的交互信息),所以self-attention可以捕捉到精排序列中两两item之间的信息。本身这块Encoding Layer的结构就是比较简单的。同时文章也指出引入多层的Encoding Layer可以进一步捕捉到高阶的交叉信息(也就是Encoding Layer可以叠加多层)。
3、Output Layer
最后的Output Layer的目标是输出各个候选广告的re-ranking score,结构也是比较简单的,用一个Linear Layer加一个softmax就可以了。
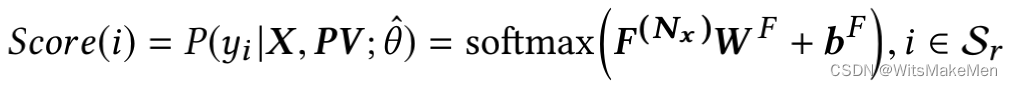
这里不做过多介绍了。
4、损失函数
使用的是listwise的思想,用TOP1作为整个排序排列的代表,对于一个resquest,计算所有的排列的交叉熵损失。
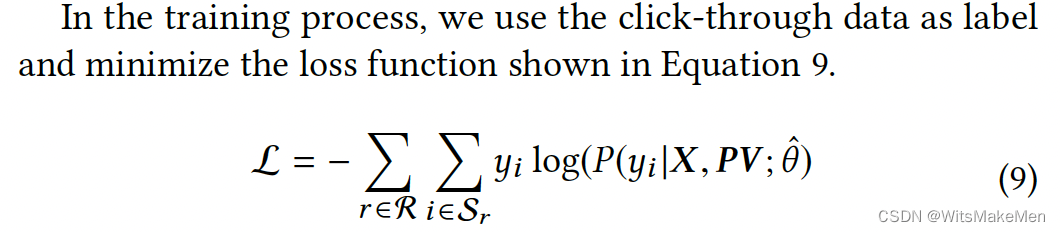
四、实验效果
实验的具体参数设置和离线实验效果这里就不给大家贴出来了,大家可以参考原始论文。这里只给出线上A/B实验效果。
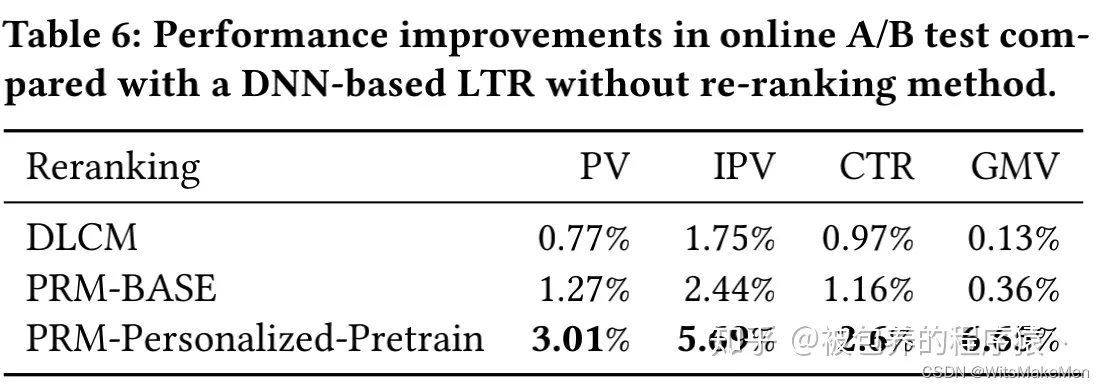
可以看到引入个性化信息之后的PRM模型的线上提升是非常显著的,曝光、点击、GMV都提升了几个点,这个对线上的收益是十分巨大的。所以可见重排序模块还是非常重要的,建模好的话其实可以带来非常明显的线上收益。
五、结论
因为重排序是离最终展现结果最近的一个模块了,所以非常容易提升效果,而且对最终线上系统表现的影响也非常大,通过阅读这篇论文,大家对重排序模块也会有一个大致的了解,其实在重排序阶段还有挺多事情可以做的,比如如何保证最终展现结果的多样性、在广告场景下如何将候选广告插入到自然结果当中(是否应该插入广告、在哪里插入广告等)。这篇论文算是一个比较常规的做法,目前也有一些其他的思路和解法应用在重排序模块,比如强化学习。大家对重排序模块有什么好的见解,也欢迎大家留言或者私信讨论。