前端技术发展迅速,即便不说是日新月异,每年也都推出新框架和新技术。Tubi 的产品前端代码仓库始建于 2015 年,至今 8 年有余。可喜的是,多年来紧随 React 社区的发展,Tubi 绝大多数的基础框架选型都遵循了社区流行的最佳实践。核心框架和依赖的版本基本都已经或有计划更新到最新的稳定版本。
能做到这一点,主要得益于 Tubi 小而美的前端团队有着强烈的技术自驱力;此外,团队管理层重视工程师文化和技术基础设施建设,愿意给予团队不少于 20% 的整块时间进行功能开发外的必要技术优化和升级。
本文将介绍的 Enzyme 到 React Testing Library(RTL)的迁移发生在 2022 年底,是 Tubi 前端至关重要且有相当工作量的代码迁移项目之一。
迁移动机
在 Tubi ,即便是社区推荐的技术选型,我们也要先对其必要性和价值做出评估,待达成共识后才会采取进一步的行动。回到 Enzyme 到 RTL 的迁移,主要理由有四个:
第一,Airbnb 官方已经不再活跃维护 Enzyme,且没有计划支持最新的 React 18。Tubi 决定升级到最新的 React 18 ,就必须找到并迁移所有 UI 测试到 Enzyme 的替代方案。
第二,RTL 关注于集成测试的设计理念使得团队可以更轻易、高效地写出易于维护的测试代码。
第三,RTL 鼓励从用户实际使用角度写测试用例,因此其 API 设计理念无形中就引入很多 UI 测试的最佳实践,例如对 Web Accessibility 的关注和强调。
第四,RTL 成熟活跃的社区及轻量的实现机制保证了该测试框架可预期的长久生命力。
关于第二点,相对于大家所熟知的测试金字塔模型,RTL 的作者 Kent C. Dods 提出了与之相对应的测试奖杯模型(Test Trophy),如下图所示。Kent 认为,应该把主要精力放到写 UI 集成测试(Integration Test)上,这样模拟 API 调用和返回结果去整合应用,既可以规避因调用异步 API 导致过慢的测试运行速度,又能从用户实际使用角度全方位测试应用的功能,做到事半功倍。

举例说明,当我们测试页面渲染时,不仅测试了预期被渲染的 UI 元素,同时自然而然地覆盖了该页面数据加载、UI 元素展示和潜在的用户交互及权限控制。换句话说,我们通过 UI 测试用例,就可以顺带自然而然地触及更底层的有关 Redux 状态管理、事件派发和数据组织的功能和逻辑,从而轻松覆盖原本需要单元测试去检测的代码功能和分支条件。因此,UI 集成测试兼顾了测试覆盖度和测试运行速度,是更有效、值得推荐的书写前端测试代码的方式。
第三点中提到的 RTL 先进测试理念在下文 Counter 测试的示例中展示无遗。Enzyme 测试一般会与组件的具体实现细节相绑定。
在示例中,Enzyme 通过 button 对应的 increment class name 定位到自增按钮,并通过检查保存在组件内部 state 中 count 的变化来确定自增计数功能被正确执行。而 RTL 通过 getByLabelText 和 getByRole 这样的语义化 API 获取对应遵循 Web Accessibility 规范的元素,进而通过检测用户可见界面的改变而验证计数器自增功能被如预期执行。因此,RTL 测试有两个显而易见的好处:
1. 与 UI 实现细节的解耦让测试代码更加健壮,今后实现细节的变更并不会导致测试代码失效;
2. Web Accessibility 导向的 API 设计鼓励开发者在实现 UI 组件时遵循 Web Accessibility 规范。
import { render, screen } from '@testing-library/react';
import userEvent from '@testing-library/user-event';
import { shallow } from 'enzyme';
import React from 'react';
import Counter from './Counter';
describe('Enzyme tests', () => {
it('should increment by 1', () => {
const wrapper = shallow(<Counter />);
const instance = wrapper.instance();
expect(instance.state.count).toBe(0);
wrapper.find('button.increment').simulate('click');
expect(instance.state.count).toBe(1);
});
});
describe('RTL tests', () => {
it('should increment by 1', () => {
render(<Counter />);
const countLabel = screen.getByLabelText('count');
expect(countLabel).toHaveTextContent(0);
userEvent.click(screen.getByRole('button', { name: 'Increment' }));
expect(countLabel).toHaveTextContent(1);
});
});
作者:隔壁正在装修真羡慕
链接:https://juejin.cn/post/7260024054066085946
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。此外,RTL 和 Enzyme 的 npm 下载次数统计也清晰反映出当前 RTL 已经取代 Enzyme,成为 React 前端项目测试框架的不二选择。因此,我们将 Enzyme 到 RTL 的迁移工作提上了正式日程。

迁移规划
了解迁移项目规模和整体概况对于我们制定切实可行的迁移规划和策略至关重要。Tubi 产品前端代码仓库有着高达 92% 的代码测试覆盖率。依照迁移项目启动前的统计,我们依赖 Enzyme 的 UI 测试文件总共有 440+ 个(涉及的总代码行数应该超过 10 万行)。如果迁移不能很快完成,随着新 Enzyme 测试的创建,这个工作量还会持续增加。
因此,我们新功能和新组件的开发需要尽早强制使用 RTL 去测试;同时,对于存量 Enzyme 测试,我们需要找到一个渐进的方案实现逐步迁移。一个分而治之的迁移路径由此浮现,如下图所示。

验证可行性
为了进一步验证 RTL 是否可以匹配我们对新功能新组建的 UI 测试需求,我们决定从实战出发,将 RTL 应用到我们当时正在开发的世界杯活动页面上。选用这个页面做验证,是本着先难后易的原则。因为这个着陆页足够复杂,涉及响应式 UI 、deep links 调用、API mocks 、用户交互和页面跳转等众多复杂场景的测试。我们认为,如果 RTL 可以很好地满足在复杂场景下的测试,那么相对简单的 UI 测试就更不成问题了。
最终的结果令人满意,RTL 可以完美适配上述测试场景。相对于 Enzyme 测试,RTL 测试的实现更加简洁高效,且测试运行时间并没有显著改变。同时,我们还封装了适配 Redux、react-intl 等第三方库初始化的自定义渲染(render)方法,并沿用 Nock 在 API 层面去模拟 API 的响应结果。这一切,都让我们得以在尽量维持技术选型和依赖不变的基础上,做到相对严格地遵循 RTL 官方推荐实践和理念。这些成功而积极的正向反馈坚定了团队向 RTL 测试迁移的信心。
引入 Lint 和进度统计脚本
延续分而治之的策略,在大规模迁移已有测试前,我们实现了一个自定义的 ESlint 规则并将其添加到 Github CI 中,以确保停止添加新的 Enzyme 测试这一共识被贯彻执行。下图中,Lint 规则的 startDate 被设为 2022-12-16,这意味着在该日期后引入的新 Enzyme 测试会引发 Lint 报错。

同时,为了方便掌握迁移进度,并快速定位尚未迁移的代码,我们在项目初期就实现了名为 rtl-migrate 的 npm 命令以辅助迁移。如下图所示,运行 yarn run rtl-migrate 可以获知 Enzyme 测试的整体迁移进度和选定文件夹的迁移概要。运行 yarn run rtl-migrate -p src/ott --type=enzyme 将打印出 src/ott 目录下所有尚未迁移的测试文件。此外,该命令还实现了找出测试文件核心贡献者和根据文件大小过滤排序的功能,这些都为我们分配迁移任务给最恰当的开发者提供了数据参考。文章长度所限,这里不一一展示。

通过 Codemods 自动迁移
根据最初的分析,我们有不少于 440 个测试文件需要迁移。即便按平均每个文件仅 250 行来做最乐观的估算,整个迁移涉及的测试代码改写量将不少于 11 万行代码。这无疑是一个巨大且可能旷日持久的工程。为了尽可能缩短工期,我们决定基于 jscodeshift 构建自己的 Codemods 脚本,以便尽可能自动迁移典型的 Enzyme 代码模式到 RTL 测试,从而节省人工迁移的成本。
选择自己构建 Codemods 脚本,是因为在开源社区中我们并没有找到符合要求的现成 Enzyme 迁移脚本。同时考虑到我们项目对 Enzyme 的独有封装和扩展,如果希望尽可能灵活精准地将更多 Enzyme 测试自动转化为 RTL 测试,构建可以完全掌控的 Codemods 脚本势在必行。
当然,我们并不期望 Codemods 可以迁移所有测试用例。务实的期望是 Codemods 能以最小代价优先覆盖代码仓库中最常见的测试用例和代码模式。技术选型和决策同样需要衡量投入产出比和最终收益。平衡和取舍往往是技术决策的关键词。尤其对于测试迁移这类一次性的工作而言,实现一个面面俱到的 Codemods 脚本并不是我们的初衷。重点是,我们须确保通过 Codemods 自动迁移带来的时间节省收益大于开发 Codemods 付出的精力消耗。
因此,我们优先找出了 Enzyme 测试中最常见的几种代码模式及其变形,并实现了对应的 Codemods 使其可以被自动转换。这一过程切合我们常说的二八原则,即通过 20% 的成本完成了 80% Codemods 的预定目标,剩余 20% 的功能也许我们可以继续投入 80% 的时间去打磨。考虑到迁移工作一次性投入的特性,对非常见的测试模式我们并没有强求在 Codemods 层级做自动迁移的支持。
回到具体实现,本质上 Codemods 先将特定代码片段转化为抽象语法树,进而识别并修改特定语法树的结构后再重新生成新的代码片段。因此,构建诸如迁移 Enzyme 测试这样功能复杂的 Codemods 时,对 Codemods 功能的拆解和组织尤其重要;否则,复杂性的不断叠加终将导致 Codemods 难以维护。实现之初,我们便仔细设计了 rtl-codemod 代码组织关系和 transformer 间的通信存储机制。具体说明如下图。

这里的关键词是解耦,可以将各 transformer 想象为独立、目的明确的插件或中间件,它们可以互不干扰地独立运行;最终 Codemods 对代码的修改是这些插件按顺序执行的结果。我们设计 rtl-codemod 时,进一步引入了 motions 这个 micro-transformer 的概念,从而构建了两层的插件体系结构,做到了 tranformer 功能的进一步拆解和灵活组装。
作为 Codemods 执行入口的核心,transform 只重点负责配置各 transformers 的执行顺序。其实现大体精简如下:
const transform: Transform = (file, api, options) => {
const j = api.jscodeshift;
const { source } = file;
const ast = j(source);
// NOTE: The order of motions is important. Some motions need to be
// applied before others.
applyMotions(j, ast, [
...renderMotions,
...snapshotMotions,
...findTextMotions,
...inTheDocumentMotions,
...userEventMotions,
// More transform-related motions...
]);
return toSource(ast, options.toSourceOptions);
};此外,作为脚本程序,某 transformer 运行时结果和中间计算产出可以通过持久化存储被其他 tranformers 从特定存储中读取。换言之,存储也可以被理解为 transformer 实现通信和数据共享的媒介。
更多细节可以参考我们开源出来的精简示例实现:github.com/nickqi-tubi…
妥协和适配
做技术决策时,经常会不得不选用一些退而求其次的妥协方案,但这并不完全是一件坏事。相反,为了更好地适配现有代码和模式而主动做出的妥协,往往是一种务实而精明的抉择。
以 Enzyme 迁移为例。
我们在 Enzyme 测试中大量使用了 wrapper.instance() 这种独有 API 去检测组件的期望实例值。这是 Enzyme 测试中常见且官方推荐的模式之一。与之相反,RTL 明确反对针对实现细节设计任何测试用例,这也是 RTL 未曾暴露获取组件实例或内部状态的 API 的原因。
RTL 官方建议
You want your tests to avoid including implementation details so refactors of your components (changes to implementation but not functionality) don't break your tests and slow you and your team down.
RTL 的设计理念和建议无疑是有道理的。但回到测试迁移这个任务上,考虑到我们已经有至少十万行代码基于 Enzyme 实践,去除对 wrapper.instance() 的依赖意味着我们需要彻底重写大量测试,这无疑极大加剧了测试迁移的实现成本而难以推进。务实的考虑是,我们需要为 RTL 提供一种桥接,使 RTL 测试依然可以适配现存针对组件实例和内部状态的测试。
基于上述原因,我们实现了如下所示的 renderWithInstance 工具方法:
function renderWithInstance(
passedComponentOptions,
renderOptions
) {
let incorrectlyUseInstancePattern;
let WithExtendedClass;
const { extendingClass } = passedComponentOptions;
try {
if (extendingClass.prototype.isReactComponent) {
WithExtendedClass = class WrapperInstance extends extendingClass {
constructor(props) {
super(props);
incorrectlyUseInstancePattern = this;
}
};
} else {
WithExtendedClass = class WrapperInstance {
constructor(_props: any) {
incorrectlyUseInstancePattern = this;
}
};
Object.setPrototypeOf(WithExtendedClass, extendingClass);
}
} catch (e) {
throw new Error(`Problem extending passed 'extendingClass'.\n${e.stack}`);
}
const renderResult = render(
<WithExtendedClass {...passedComponentOptions.props} />,
{
wrapper: getWrapper(renderOptions),
...renderOptions,
}
);
return {
...renderResult,
incorrectlyUseInstancePattern,
};
}
作者:隔壁正在装修真羡慕
链接:https://juejin.cn/post/7260024054066085946
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。通过在迁移后的 RTL 测试中调用 renderWithInstance,我们使自定义的 RTL 渲染方法依然可以暴露组件实例对象而尽量复用已有的检测条件。
it('should call handleUpdateA11y when activeIdx changes', () => {
const updateA11ySpy = jest.spyOn(
incorrectlyUseInstancePattern, 'handleUpdateA11y'
);
const {
incorrectlyUseInstancePattern
} = renderWithInstance({
extendingClass: AlertModal,
props: getProps()
});
incorrectlyUseInstancePattern.componentDidUpdate(
{}, { activeIdx: 1 }
);
expect(updateA11ySpy).toHaveBeenCalled();
});
作者:隔壁正在装修真羡慕
链接:https://juejin.cn/post/7260024054066085946
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。时间和成本开销
Tubi 前端团队从 Enzyme 到 RTL 的测试迁移工作耗时约两个半月。期间,我们创建并完成了 109 个与之相关的开发任务(stories),共迁移了 466 个测试文件和 10 余万行的测试代码,项目燃尽图如下。
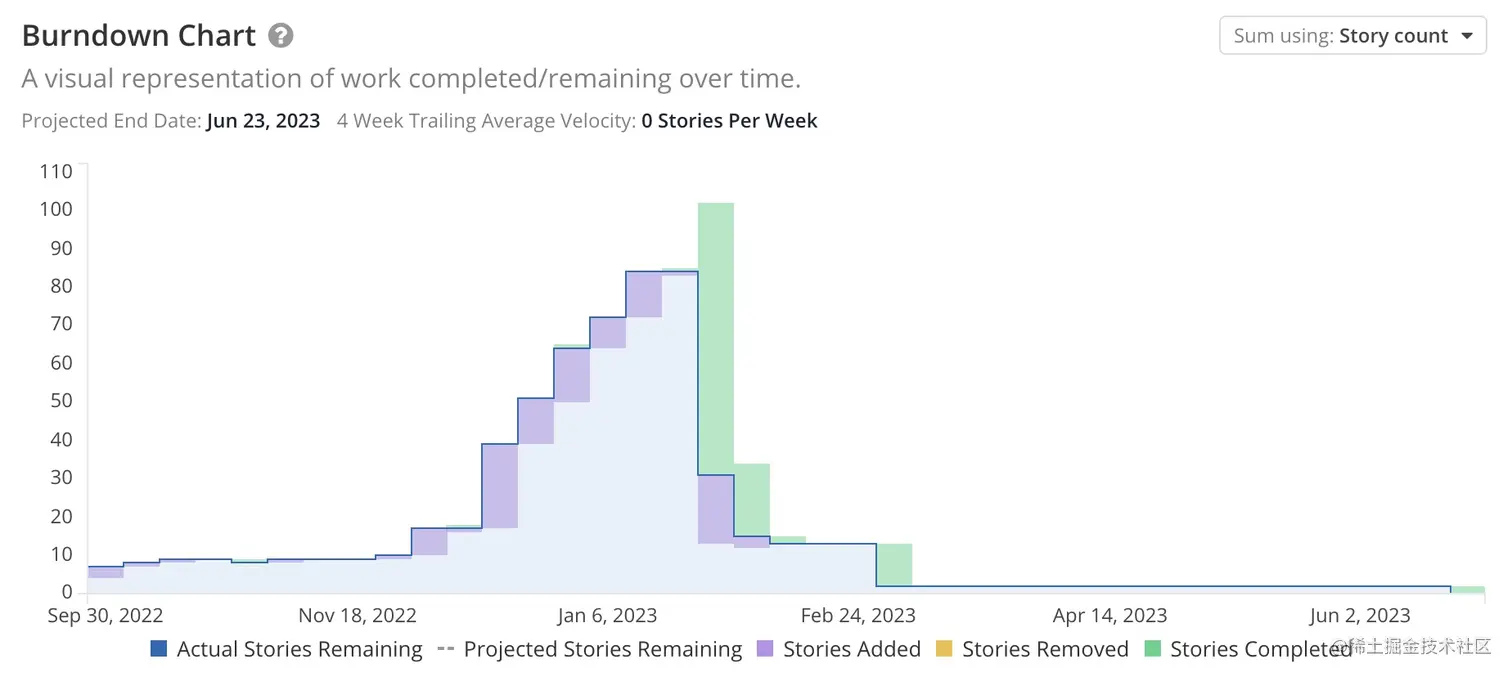
其中,绿色表示 Stories 完成的统计出现骤减,是因为在 Shortcut 系统中,只有对应的代码真正发布到生产环境后才被统计为完成;但实际的迁移工作每天都在推进,而非一蹴而就。
通过燃尽图,我们可以看到 Tubi 从 2022 年 9 月已经开始考虑这一迁移工作。当时只是创建了用于概念验证的前期准备工作和团队内部的分享讨论。11 月底,借着圣诞和新年期间线上代码冻结的时机,我们正式将测试迁移排上日程。
2022 年 11 月底到 12 月中旬,我们投入了近一个半的全职前端工程师(两位负责迁移项目的前端工程师,每人投入约 70% 的时间推进迁移工作),构建辅助迁移的 Codemods 、进度报告脚本和 Lint 工具。同时,他们还尝试手动迁移代码库中的一些典型测试,以便了解迁移的难点并找到对应的解决方案。
2022 年 12 月底,随着辅助工具的完善和对迁移难度的掌控,我们对其他长期工作于 Tubi 产品前端代码仓库的工程师进行了 RTL 测试和迁移方面的培训。之后,将需要迁移的测试文件按对所涉及代码的熟悉程度和工作量进行了统一分配。2023 年 2 月中旬,我们实际已经完成了全部的迁移工作,燃尽图在 2 月底上线时将已经合并的测试代码记为完成。
经验和总结
大多数工程师(尤其是前端工程师)希望紧追技术潮流,使用最新最酷的技术,但对于已有代码仓库而言,框架和依赖迁移的成本不容忽视。成熟的工程团队需要平衡利弊、明确投入产出比和必要性后做出理智的决策。推进迁移时,寻求渐进而为的方式应被视为基本策略。当然,对新旧代码分而治之的差异化对待经常是为了快速推进而做出的必要妥协。
另外,本文中提到的 Codemods 和进度报告脚本等工具也都是辅助迁移的必要前期开发。考虑到迁移往往是一次性的工作,因此对辅助工具开发上的投入,我们认为二八原则依然适用,应尽可能花少量时间满足多数需求,无需做到面面俱到。
如果有机会重新主导一次 RTL 测试迁移项目,以下两点依然有改进空间:
1. Codemods 的范围需要提前界定
虽然我们一直在强调二八原则和避免在一次性的 Codemods 工具上做过度投入,但工程师追求完善自动化工具的天性让我们依然在 Codemods 上花费了比预期更多的时间,实现了对相对不常见的代码模式及其变形的支持。预先引入团队计划和评估决策流程,将有效地避免这一问题。
2. 理应更早引入团队参与,加速项目进展
在项目后期,我们等 Codemods 相对稳定后才请更多团队成员参与进来。回头看,这种瀑布式的开发流程,使整个项目周期拉长了。更好的做法是我们预先确定测试迁移的典型代码模式,并对团队做预先培训。即便 Codemods 没有完全完成,我们依然可以动员整个前端团队,尽早开始手动迁移那些 Codemods 计划中不会支持的代码模式,做到项目的并行推进。
总体而言,此次测试迁移工作为 Tubi 前端团队扫清了之后升级最新 React 18 的障碍。在短短两个月,我们完成了 466 个测试文件和 10 余万行测试代码的迁移,这无疑是一个值得称道的成绩。同时,受益于 React Testing Library,团队实现 UI 测试代码的效率和对 Web Accessbility 的重视得到了极大提升,这也印证了我们对技术项目投入的价值与收益。
作者:Nick QI,Tubi Staff Software Engineer
欢迎加入 Tubi
如果你对类似项目感兴趣,欢迎加入 Tubi!