前言
2019 年,字节跳动服务框架组针对大规模微服务架构下遇到的功能和性能痛点,以及吸收历史上旧框架下积累的经验与教训,着手开发了 RPC 框架 Kitex 以及周边一系列相关基础库,并在 2021 年正式在 Github 上开源。
从 2019 年走到如今的 2023 年,内部微服务规模经历了巨大的扩张,Kitex 框架也在此过程中,经历了一次又一次的性能优化与考验。这篇文章希望分享在此过程中我们所积累的一些性能优化实践,也为我们过去几年的优化工作做一个系统性的梳理总结。
Kitex 的前世今生
为什么需要 RPC 框架
虽然 RPC 框架的历史由来已久,但真正被大规模作为核心组件广泛使用,其实与微服务架构的流行是分不开的。所以我们有必要回顾下历史,探究为什么我们需要 RPC 框架。
单体架构时代
这段时期系统服务的主要特点有:
-
通过函数分割不同业务逻辑
-
性能压力主要集中在数据库,于是产生了数据库层面从分库分表这种手动分布式到真正的自动分布式架构演进过程
常见的业务代码如下:
func BuySomething(userId int, itemId int) {
user := GetUser(userId)
sth := GetItem(itemId)
}
func GetUser(userId) {
return db.users.GetUser(userId)
}
func GetItem(itemId) {
return db.items.GetItem(itemId)
}
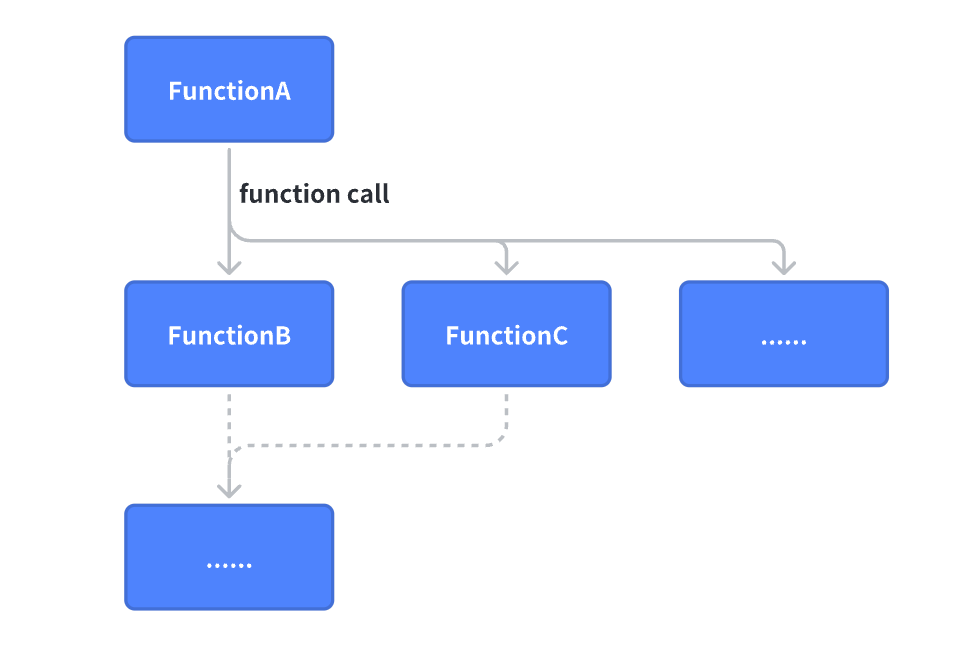
这种编码模式简单直接,在本身具备良好的设计模式时,非常易于重构和编写单元测试。目前许多 IT 系统依然采用这种模式。但是随着互联网业务极速发展,在一些超大型的互联网项目中,也触碰到了一些天花板:
-
计算能力天花板:一个请求拥有的计算能力上限 <= 单服务器总计算能力 / 同时处理请求数
-
研发效率天花板:代码仓库体积,团队人数与编码复杂度不是线性增长的关系,越往后维护难度越大,上线难度也越大。
微服务架构时代
为了解决单体架构的上述问题,我们来到了微服务架构的时代。微服务架构的典型代码如下:
func BuySomething(userId int, itemId int) {
user := client.GetUser(userId) // RPC call
sth := client.GetItem(itemId) // RPC call
}
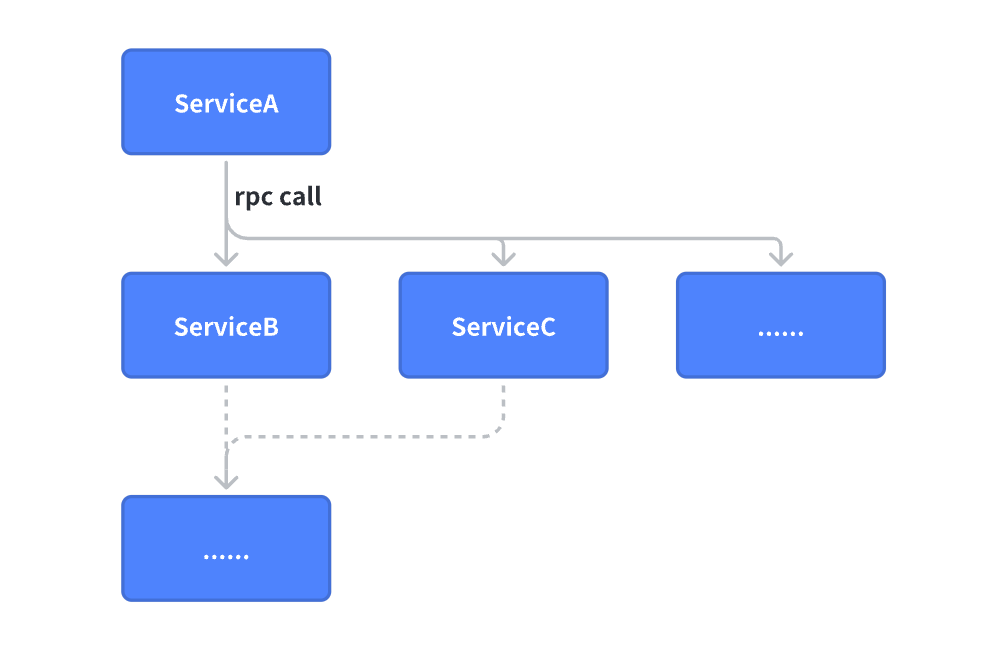
RPC(Remote Procedure Call,远程过程调用) 的意义在于:让业务能够像调用本地方法一样调用远程服务,对业务感知度降到最低,进而做好从单体架构向微服务架构演进过程中,对业务编码习惯的改变降到最小。
性能优化的方向
在不使用 RPC 的情况下,如下图的代码唯一的调用开销仅仅只是一个函数调用的开销,不考虑内联优化的情况下,是一个纳秒级的开销。
func client() (response) {
response = server(request) // function call
}
func server(request) (response) {
response.Message = request.Message
}
而将其换成 RPC 调用后,调用开销直接飙升到了毫秒级:
func client() (response) {
response = client.RPCCall(request) // rpc call - network
}
func server(request) (response) {
response.Message = request.Message
}
这是一个 10^6 级别的延迟差异,既证明了 RPC 的代价很大,也证明了其中的优化空间也很大。
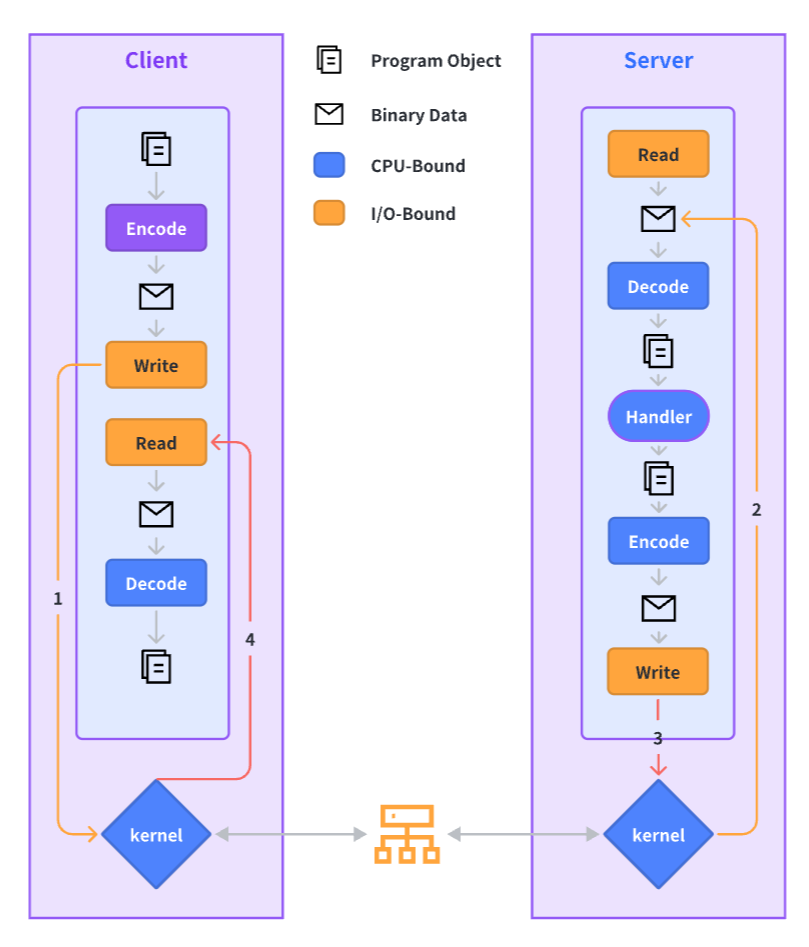
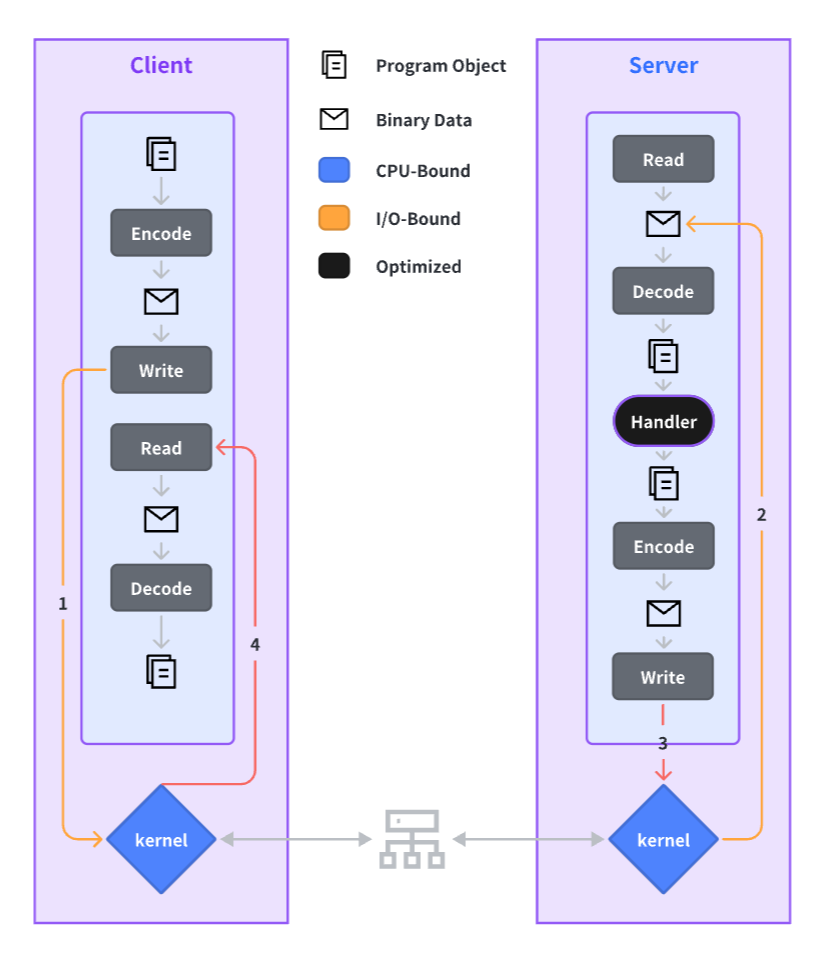
一次 RPC 调用的完整过程如下,后面我们会针对每一个环节给出我们在其上所做的性能优化实践:
为什么自研 RPC 框架
在了解性能实践之前,我们需要解释一件事情是,为什么在已有众多 RPC 框架时,我们依然选择自研一个新的 RPC 框架。主要有以下原因:
-
公司内部主要以 Thrift 协议通信,而主流 Go 框架大多不支持 Thrift 协议,也不容易做多协议的扩展
-
公司内部对性能有极致的要求,需要从全链路上做深度优化(后面会举例)
-
公司内部微服务规模巨大,场景复杂,需要一个支持深度定制的高扩展性框架
Kitex 是什么
发展历程
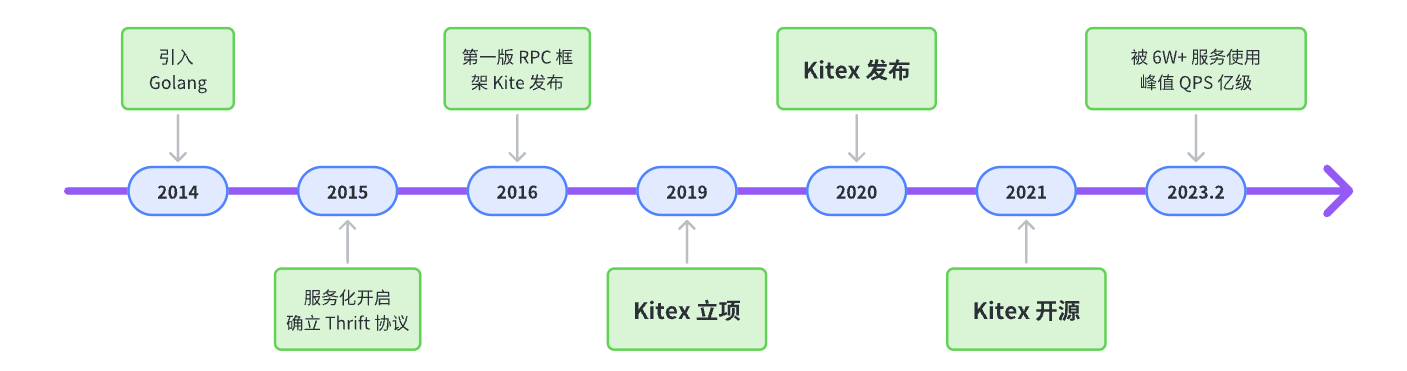
Kitex 从 2019 年正式立项,2020 年在内部发布,2021 年正式开源,直到 2023 年 2 月,已有超过 6 万微服务在使用。
CloudWeGo 大家族
在开发 Kitex 主框架的同时,我们也把许多与 Kitex 并不耦合的高性能组件也一一开源出来,进而形成了 CloudWeGo 的大家族生态:


Kitex 与其他框架对比
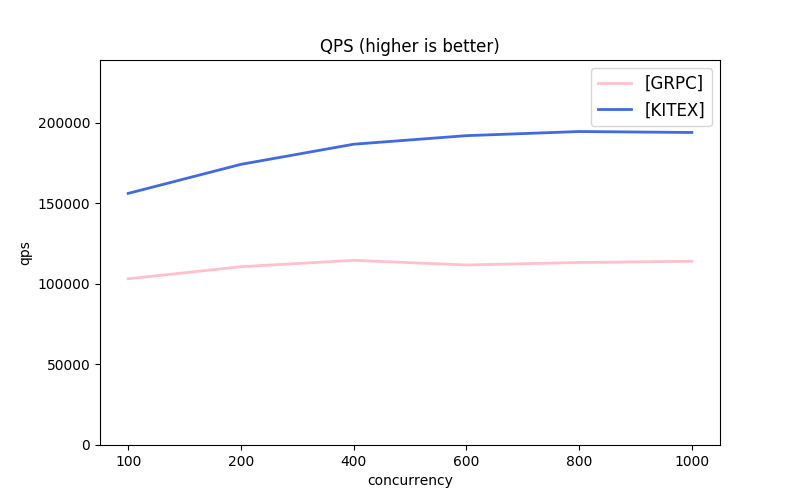
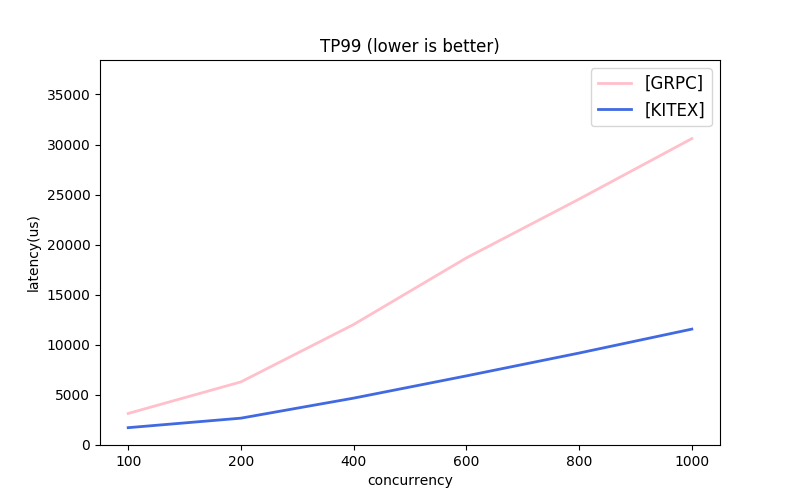
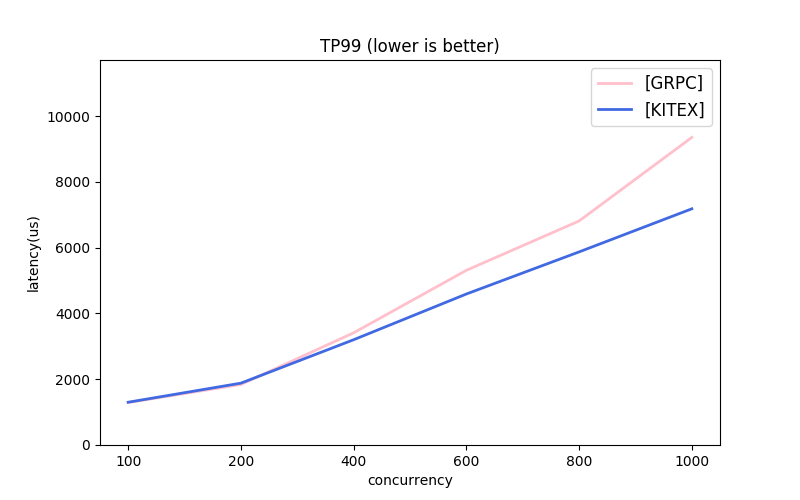
Kitex 同时支持 Thrit 与 gRPC 协议,但 Go 生态下支持 Thrift 的框架并不多,所以这里我们选择使用 gRPC 协议来与 grpc-go 框架进行横向对比:
gRPC Unary 对比:
gRPC Steaming 对比:

Kitex 框架性能优化实践
Kitex 许多性能优化的思路其实并不与 Go 语言相绑定,但这里为方便,我们主要以 Go 来举例。
接下来我们会顺着前面一次 RPC 调用的完整流程图,一一介绍 Kitex 的性能优化实践。
编解码优化

常见编解码的问题
以 Protobuf 为例:
-
计算开销:
-
需要运行时通过反射获取额外信息
-
需要调用众多函数并创建众多小对象
-
-
GC 开销:不容易重用内存

生成代码优化:FastThrift & FastPB
我们在 Kitex 支持的两种协议 Thrift 和 Protobuf 中,都实现了通过大量生成代码来实现编解码的能力。由于生成代码可以最大化提前预置好运行时的信息,所以可以提供以下好处:
- 预计算好 Size,并重用该内存
序列化时,我们可以用极低的成本调用 Size() 并以此提前创建好一块固定大小的内存空间。
type User struct {
Id int32
Name string
}
func (x *User) Size() (n int) {
n += x.sizeField1()
n += x.sizeField2()
return n
}
// Framework Process
size := msg.Size()
data = Malloc(size)
Encode(user, data) // encoding user object directly into the allocated memory to save one time of copy
Send(data)
Free(data) // reuse the allocated memory at next Malloc
- 尽可能减少函数调用和中间对象创建
虽然函数调用和小对象创建成本都很低,但是对于编解码这种热路径,对这些低成本高频次代码的优化也能带来非常大的收益,尤其是 Go 是带 GC 的语言。
可以看到,由于底层 fastWriteField 函数会在编译时被内联,所以序列化 FastWrite 函数本质上是在顺序写入一块固定内存空间(FastRead 也是类似)。
func (x *User) FastWrite(buf []byte) (offset int) {
offset += x.fastWriteField1(buf[offset:])
offset += x.fastWriteField2(buf[offset:])
return offset
}
// inline
func (x *User) fastWriteField1(buf []byte) (offset int) {
offset += fastpb.WriteInt32(buf[offset:], 1, x.Id)
return offset
}
// inline
func (x *User) fastWriteField2(buf []byte) (offset int) {
offset += fastpb.WriteString(buf[offset:], 2, x.Name)
return offset
}
优化效果
从前面的 3.58% 优化到了 0.98%:

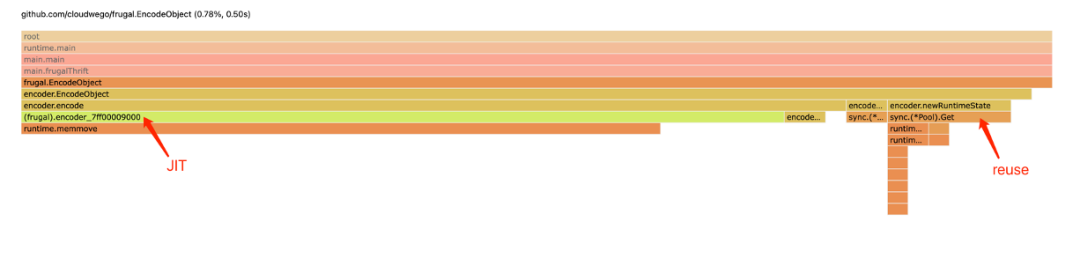
JIT 替代生成代码:Frugal(Thrift)
在前面硬编码的方法上,取得了不错收益后,我们也接到了一些反馈,比如:
-
生成代码体积随着字段增加而线性膨胀
-
生成代码依赖使用者命令行版本,多人协作易互相覆盖
所以,我们自然而然地产生了一个疑问,前面生成的代码能否通过运行时自动生成?这个问题本身其实就是一个答案,即需要引入 JIT(Just-in-time compilation) 技术来优化代码生成。
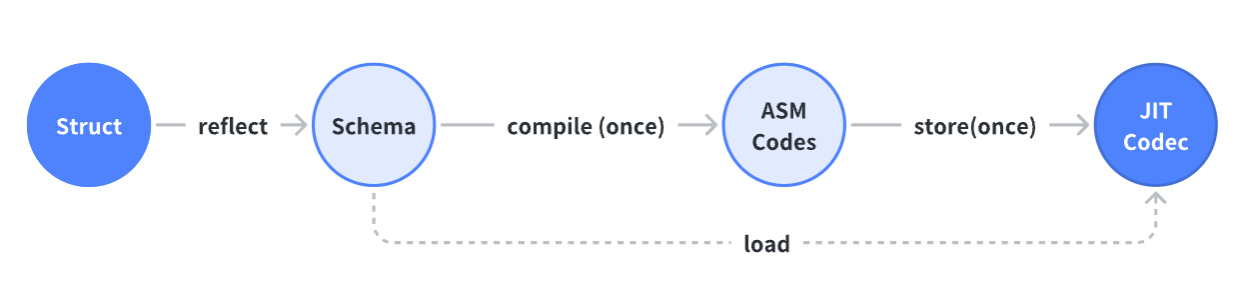
优势:
-
使用寄存器传递参数,以及更深度的内联,提高函数调用效率
-
核心计算函数使用被充分优化的汇编代码
优化效果
从前面的 3.58% 优化到了 0.78%:
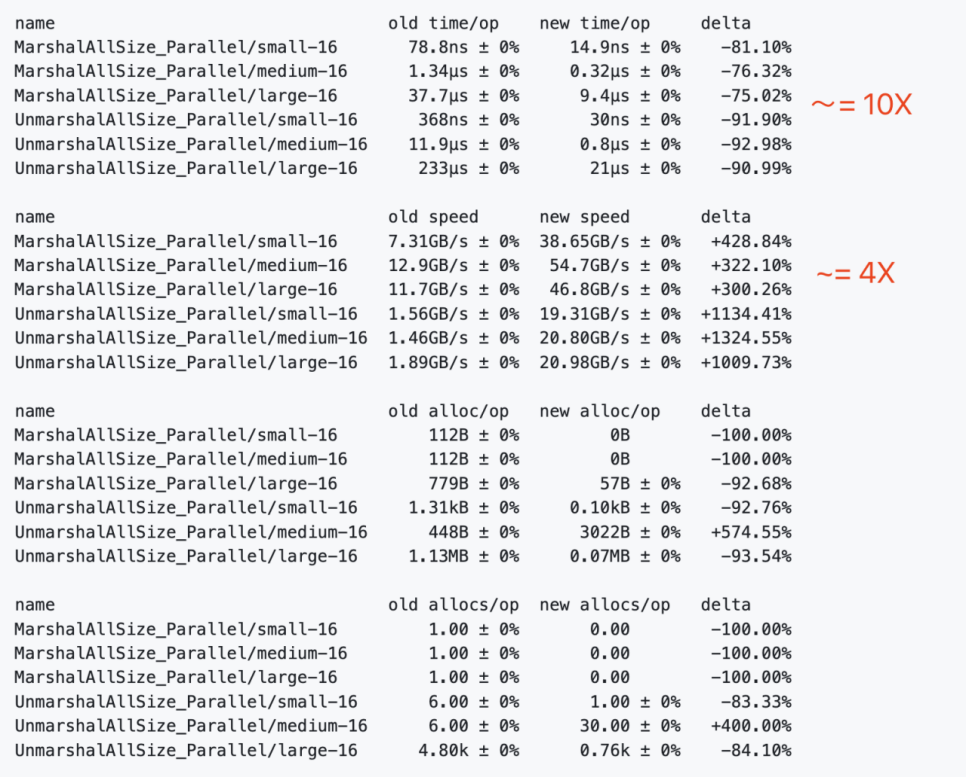
Frugal VS Apache Thrift 编解码性能对比:
网络库优化
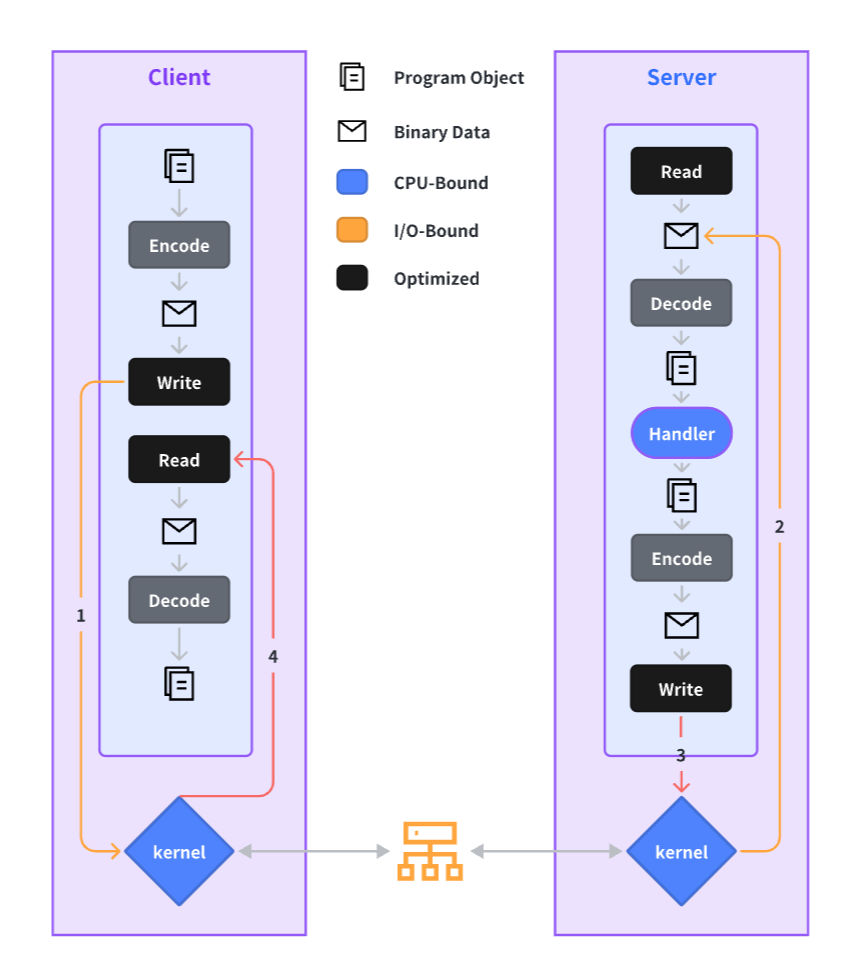
原生 Go Net 在 RPC 场景的缺陷
-
一连接一协程,在上下游实例数众多时,Goroutines 数量涨到一定程度之后性能会骤降,尤其不利于大规格实例业务。
-
无法自动连接感知关闭状态
-
一个 struct 在做 NoCopy 序列化时,产物往往是多维数组,而 Go 的
Write([]byte)接口无法支持非连续内存数据的读写。
name := "Steve Jobs" // 0xc000000020
req := &Request{Id: int32(1), Name: name}
// ===> Encode to [][]byte
[
[4 bytes],
[10 bytes], // no copy encoding, 0xc000000020
]
// ===> Copy to []byte
buf := [4 bytes + 10 bytes] // new address
// ===> Write([]byte)
net.Conn.Write(buf)
- 与 Go Runtime 强绑定,不利于改造支持一些新的实验特性。
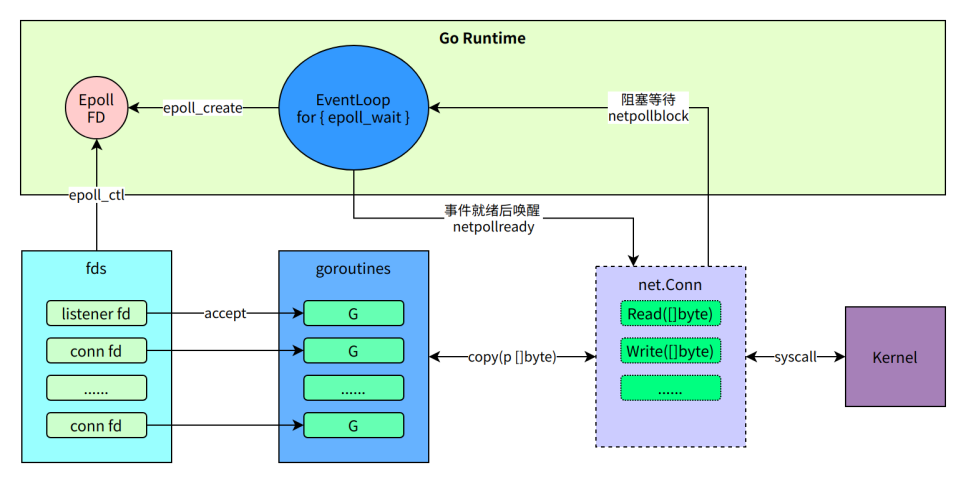
Netpoll 优化实践
主要优化点:
-
协程优化:连接数与协程数不绑定;尽可能复用协程
-
中间层 Buffer:支持零拷贝读写和重用内存,最大化避免编解码时 GC 开销
-
针对 RPC 小包高并发的场景深度定制:协程调度优化,TCP 参数调优等
-
针对内场环境深度定制,包括:改造 Go Runtime 提高调度优先级,内核支持批系统调用等

通信层优化
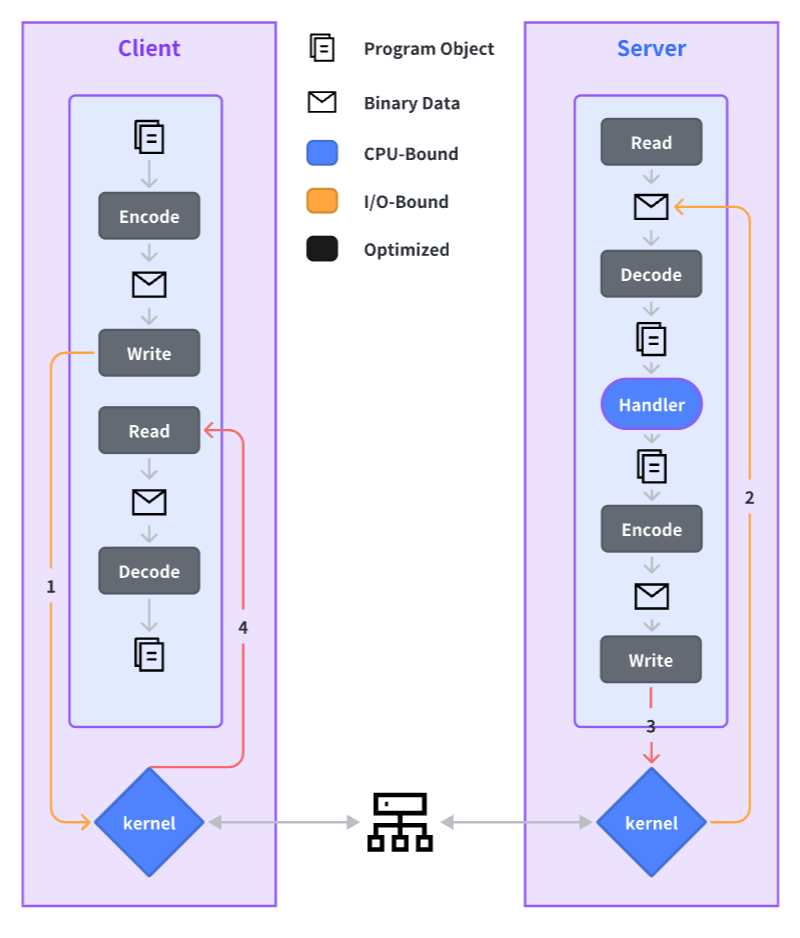
同机通信优化:Service Mesh 下的通信效率问题

在引入 Service Mesh 后,业务进程主要是和同机的另一个 sidecar 进程通信,由此产生了多一级的时延。
传统的 Service Mesh 方案一般都过 iptables 劫持实现流量转发到 sidecar 进程,可想而知从各个层面看性能损耗都是非常夸张的。Kitex 在通信层做了诸多的性能优化尝试,并最终产出了一套系统化的解决方案。
同机通信优化:UDS 替代 TCP

UDS 与 TCP 的性能对比:
======== IPC Benchmark - TCP ========
Type Conns Size Avg P50 P99
Client 10 4096 127μs 76μs 232μs
Client-R 10 4096 2μs 1μs 1μs
Client-W 10 4096 9μs 4μs 7μs
Server 10 4096 24μs 13μs 18μs
Server-R 10 4096 1μs 1μs 1μs
Server-W 10 4096 7μs 4μs 7μs
======== IPC Benchmark - UDS ========
Type Conns Size Avg P50 P99
Client 10 4096 118μs 75μs 205μs
Client-R 10 4096 3μs 2μs 3μs
Client-W 10 4096 4μs 1μs 2μs
Server 10 4096 24μs 11μs 16μs
Server-R 10 4096 4μs 2μs 3μs
Server-W 10 4096 3μs 1μs 2μs
从性能测试中,我们可以发现两个结论:
-
UDS 各指标都优于 TCP
-
但是优化幅度并算不上非常大
同机通信优化:ShmIPC 替代 UDS

为了进一步压榨进程间通信的性能,我们研发了基于共享内存的通信模式。共享内存通信的难点在于,如何处理好各个通信状态的进程间同步,所以我们采用的是自研的通信协议,并保留 UDS 作为事件通知管道(IO Queue),共享内存作为数据传输管道(Buffer):
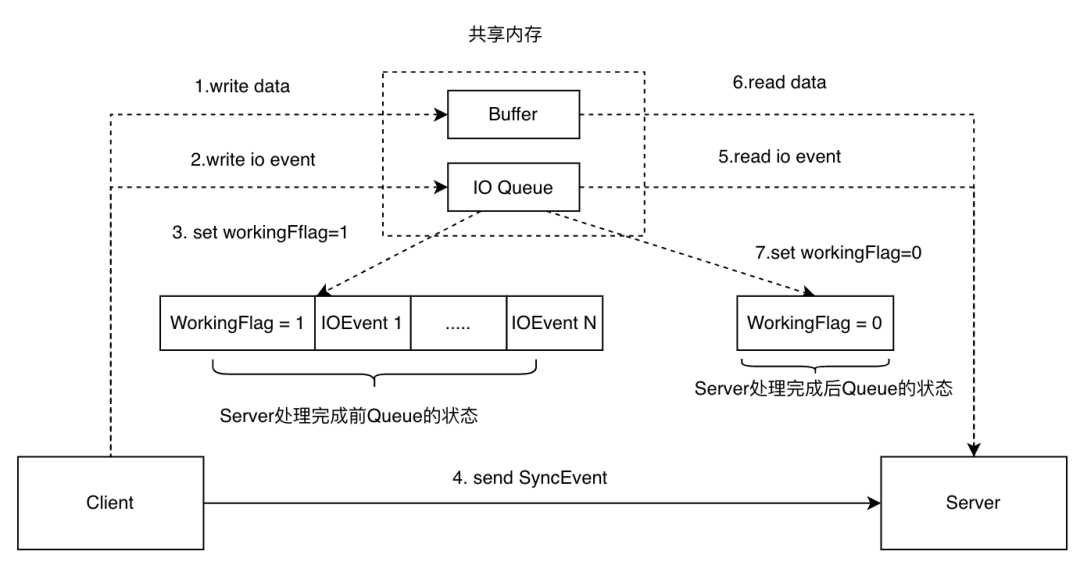
更多 shmipc 的技术细节参考过去我们发布的文章:字节跳动开源 Shmipc:基于共享内存的高性能 IPC。
性能测试:

跨机转同机通信:合并部署解决方案
前面我们在同机通讯上进行了极致的优化,但这仅限于服务进程与 Service Mesh 的数据面通信,对端的服务大概率并不部署在本机。那么如何去优化跨机通信呢?
一个“取巧”的思路就是让跨机问题转变成同机问题。
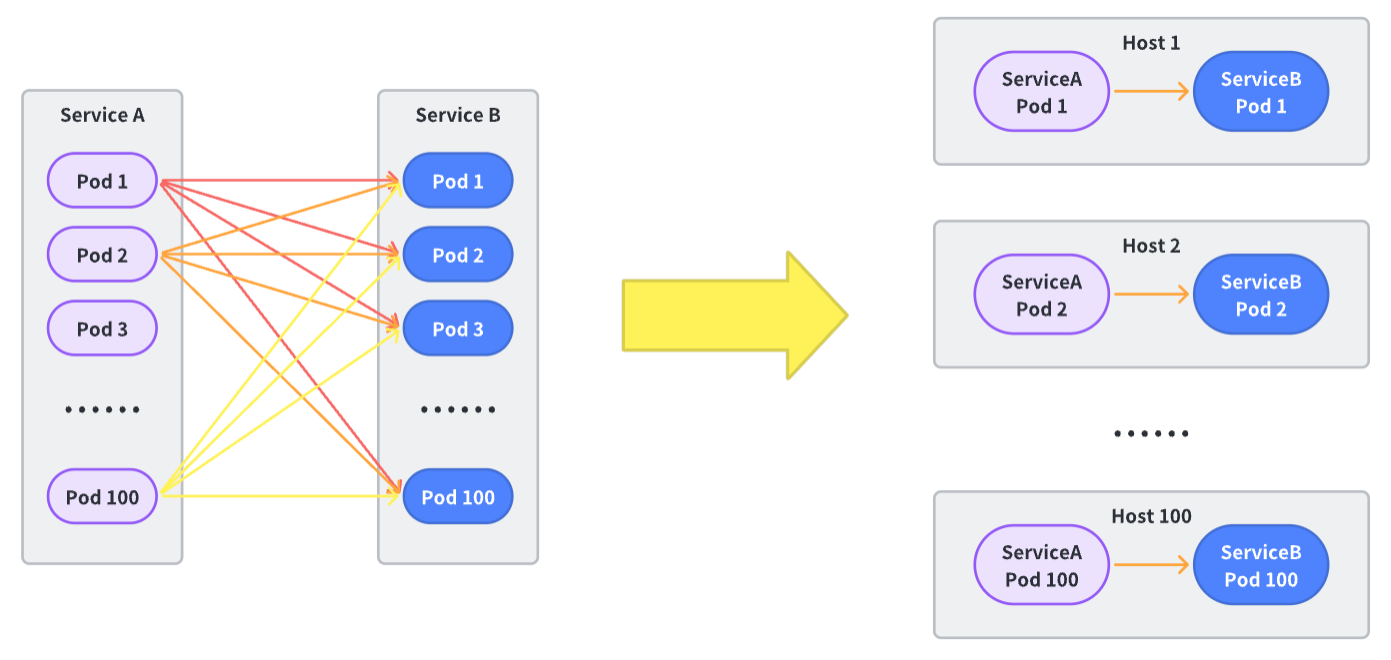
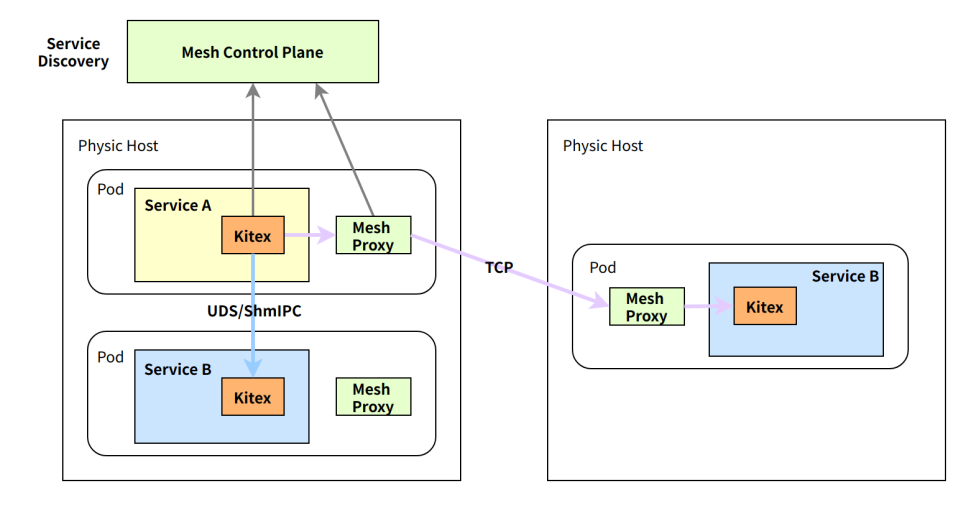
要在大规模的微服务通信中完成这个事情,需要架构上下多层组件通力配合,所以我们研发了合并部署解决方案:
-
容器调度层改造:容器调度系统会基于合并的关系和上下游服务的实例情况,进行亲和性调度,将上下游的实例尽可能调度到一个物理机上。
-
流量调度层改造:服务控制面需要识别到某一个上游容器有哪些同机下游,并在考虑全局负载均衡的情况下,针对每个上游实例情况,计算其访问下游实例的动态权重,尽可能让更多的流量可以进行本地通信。
-
框架改造:扩展定制支持合并部署特殊的通信方式,基于流量调度层的计算结果将请求发给同机实例或 Mesh Proxy。
微服务线上调优实践
除去在框架层我们所做的性能优化外,其实线上还有很大一部分性能瓶颈是来自业务逻辑自身。对此,我们也积累了一些实践经验。
自动化 GC 调优
Go 原生 GC 策略存在的问题
Go 并不是一门专门针对于微服务场景设计的语言,所以自然其 GC 策略并不侧重于在延迟敏感的业务上做优化。但 RPC 服务往往是对 P99 延迟是有一定要求的。
我们可以先来看看 Go GC 的基础原理:
GOGC 原理:
通过 GOGC 参数设置一个百分比值,默认 100,计算下一次 GC 触发时的堆大小:NextGC = HeapSize + HeapSize * (GOGC / 100) 。即默认为上一次 GC 后 Heap Size 的 2 倍。
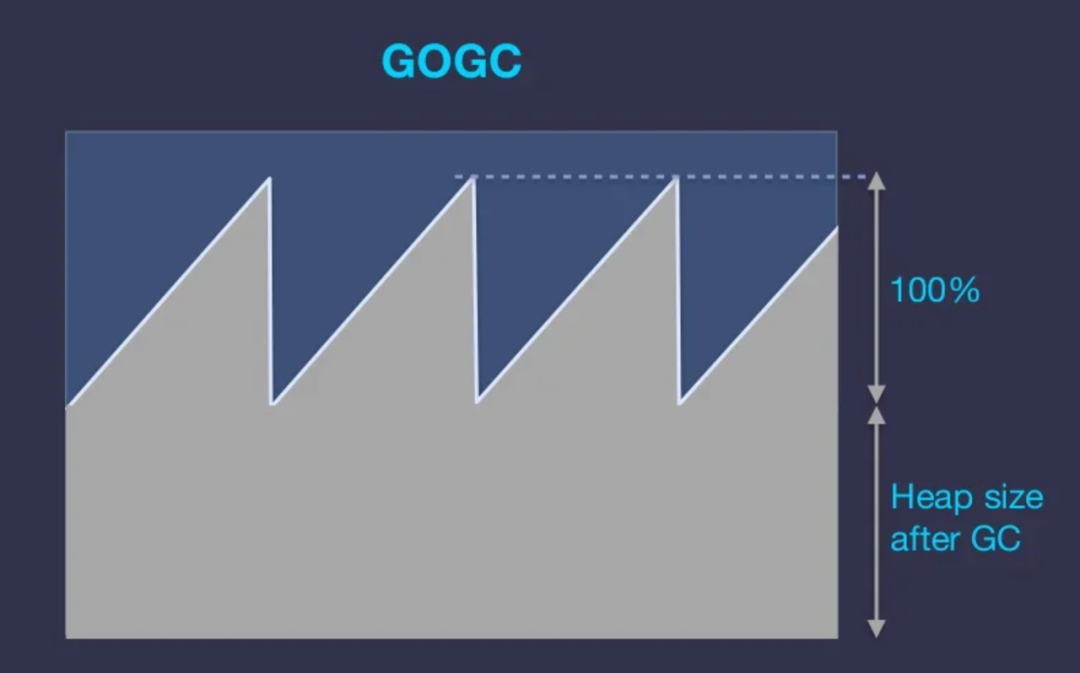
所以假设某服务活跃内存占用是 100MB,则每次堆增长到 200MB 的时候就做触发 GC。即便这个服务有 4GB 的内存。
缺点:
-
微服务场景,服务内存普遍利用率极低,但依然在做着较为激进的 GC
-
对于 RPC 场景,大量对象本身是可高度复用的,对这些复用对象对频繁 GC 会降低复用率
核心诉求:在保证安全的情况下,降低 GC 频率,提升微服务资源复用率
gctuner : 自动化调优 GC 策略
用户通过设置阈值,来控制自己想要的 GC 激进程度,例如设置成 memory_limit * 0.7,低于该值时,会尽可能增大 GCPercent。
-
内存未达到设置的阈值时,GOGC 参数往大了设置,超过时,往小了设置。
-
无论如何 GOGC 最小 50,最大 500。
优势:
-
低内存利用率时,延迟 GC
-
高内存利用率时,恢复到原生 GC 策略
需要注意的点:
-
如果内存资源并非当前进程独占,需要为其他进程预留内存资源
-
不适用于内存易出现过分极端峰值的服务
gctuner 目前已开源在 github 上:https://github.com/bytedance/gopkg/tree/develop/util/gctuner 。
并发调优
我到底能用多少 CPU ? - 容器的谎言
apiVersion: v1
kind: Pod
spec:
containers:
- resources:
limits:
cpu: "4"
微服务的发展伴随着容器化技术的蓬勃发展,目前业内大部分微服务甚至数据库都运行于容器的环境中。这里我们只讨论主流的基于 cgroup 技术的容器。
常见的业务开发模式是,研发人员在容器平台上申请了 4 核 CPU 的容器,然后自然而然认为自己的程序最多只能同时使用 4 个 CPU,并对自己的程序套上这个假设进行参数调优。
上线后,进到容器用 top 一看,各项指标确实是按照 4 核的标准在进行:

甚至用 cat /proc/cpuinfo 一看,也能不多不少刚好看到 4 个 CPU。
processor : 0
// ...
processor : 1
// ...
processor : 2
// ...
processor : 3
// ...
但实际上,这一切都只是容器为你封装出来的一个美好的假象。之所以要把这个假象做的这么逼真,只是为了让你摆脱编程时的心智负担,顺便再让那些传统的 Linux Debug 工具在容器环境中也能正常运行。
然而实际上,基于 cgroups 实现的容器技术限制的只是 CPU 时间,而非 CPU 个数。如果实际登陆到机器去看进程每一个线程正在使用的 CPU 号码,会发现加起来很可能是超过容器 CPU 设置的:

容器申请 4 个 CPU 单位,意味着可以在一个计算周期(一般 100ms)内以等价于 4 个 CPU 的时间运行,而非只能使用 4 个物理 CPU,也不意味着最少一定能同时有 4 个 CPU 给程序使用。如果超过了使用时间,该容器所有进程会被暂停执行直到计算周期结束 —— 也就是程序可能出现卡顿(throttled)。
上游并行处理越快越好吗?- 并发与超时的关系
当我们知道了原来自己程序允许的物理并行计算能力其实上限很高后,我们便可以使用这个技巧调大/调小自己服务的工作线程数(GOMAXPROCS)或者程序内的请求并发度。
例如以下调用场景,业务以 4 并发度向同一个下游发送请求,每个请求下游需要 50ms 时间处理,所以上游设置超时时间为 100ms。听起来很合理,但如果下游恰好那个时候仅有 2 个 CPU 能够处理请求,且恰好中间有一些 GC 工作或者其他工作,那么第 3 个 RPC 请求就会超时。
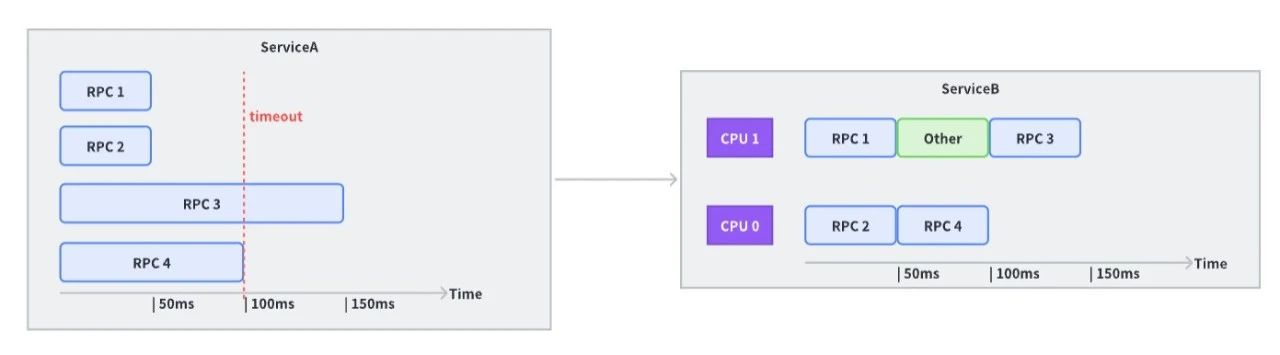
而如果我们设置并发度为 2,则超时概率会大大降低。

当然这并不是说调小并发度就是好的,如果下游计算能力远远冗余,那么调大并发度才能充分释放下游的处理能力。
拒绝内卷 - 为其他进程预留计算能力
如果容器中存在其他进程,你需要考虑给其他进程预留资源。尤其是像 Service Mesh 数据面以同容器 sidecar 部署的场景下,如果一个上游进程把计算周期内分配的时间片用完了,轮到下游进程时,非常容易被 throttled ,这样服务总体的延迟依然是劣化的。
如何调节服务并发度
-
调整工作线程数:例如在 Go 中开放了 GOMAXPROCS 来调整工作线程数。
-
修改代码中的请求并发量:业务需要自己权衡并不断尝试,在调高并发获得的延迟收益和丧失的高峰期稳定性之间做权衡,找到一个合适的并发值。
-
使用批量接口:当然如果业务场景允许的话,更好的做法是把这个接口更换成批量接口。
未来展望
最后的堡垒: Kernel
目前唯一的优化空白区:Kernel。

在线上业务中,我们常常发现这样的现象,即便我们把 RPC 优化到同机通信的程度,对于IO 密集型服务,RPC 的通信开销依然时常能占总开销的 20% 以上。而当前我们已经把进程间通信优化到了非常极致的地步,如果还想要进一步优化,只能触及到彻底打破当下 Linux 进程间通信中的约束了。
我们在这方面已经取得了一些初步成果,在未来的文章中,会继续就这一块内容进行分享,敬请期待。
重新思考 TCP 协议
数据中心内通信场景中, TCP 的缺陷:
-
内网网络质量优异,丢包率极低,TCP 的诸多设计存在浪费
-
大规模点对点通信,TCP 长连接容易退化为短连接
-
应用层以「消息」为单位,而 TCP 数据流无消息边界
这个原因进而让我们开始思考,是否应该有专有的数据中心协议来进行 RPC 通信?
持续深耕现有组件
对于现有组件,我们依然会持续投入精力去进一步提升性能与使用场景:
编解码器 Frugal:
-
支持 ARM 架构
-
优化 SSA 后端
-
利用 SIMD 加速
网络库 Netpoll:
-
重构接口,支持无缝接入现有 Go 生态库
-
SMC-R ( RDMA ) 支持
合并部署:
- 从同机走向同机柜粒度
项目地址
GitHub:https://github.com/cloudwego
