目录
基本概念和操作:
双向链表(Doubly Linked List)是一种常见的数据结构,与单链表相比,它增加了一个指向前驱节点的指针,因此每个节点除了有指向后继节点的指针外,还有一个指向前驱节点的指针。这样就可以对链表进行双向遍历,从而更灵活地操作链表。
通过使用双向链表,我们能够更方便地实现插入、删除、查找等操作。与单向链表相比,双向链表的缺点是需要额外的空间来存储前驱节点的指针,同时也需要更多的代码来维护指针的正确性。
双链表的节点用C#语言描述为:

namespace DataStructLibrary
{
/// <summary>
/// 双链表节点
/// </summary>
public class DbNode<T>
{
private T data;//数据域
private DbNode<T> prev;//前驱引用域
private DbNode<T> next;//后继引用域
/// <summary>
/// 构造器
/// </summary>
/// <param name="val">数据域</param>
/// <param name="p">后继引用域</param>
public DbNode(T val,DbNode<T> p)
{
data = val;
next = p;
}
/// <summary>
/// 构造器
/// </summary>
/// <param name="p">后继引用域</param>
public DbNode(DbNode<T> p)
{
next = p;
}
/// <summary>
/// 构造器
/// </summary>
/// <param name="val">数据域</param>
public DbNode(T val)
{
data = val;
next = null;
}
/// <summary>
/// 构造器
/// </summary>
public DbNode()
{
data = default(T);
next = null;
}
/// <summary>
/// 数据域属性
/// </summary>
public T Data
{
get { return data; }
set { data = value; }
}
/// <summary>
/// 前驱引用域属性
/// </summary>
public DbNode<T> Prev
{
get { return prev; }
set { prev = value; }
}
/// <summary>
/// 后继引用域属性
/// </summary>
public DbNode<T> Next
{
get { return next; }
set { next = value; }
}
}
}
在双向链表中,有些操作(如求长度、取元素、定位等)的算法中仅涉及后继指针,.向链表的算法和单链表的算法均相同。但对前插、删除操作,双向链表需同时修改后缘驱两个指针,相比单链表要复杂一些。
以下是双链表常用的操作:
-
初始化双向链表:初始化双向链表就是创建一个空的双向链表,创建过程如下表所示。
| 步骤 | 操作 |
|---|---|
| 1 | 声明一个为节点类型的start变量 |
| 2 | 在双链表的构造函数中将start变量的值赋为null |
2. 插入操作:在链表的指定位置(如头部、尾部或中间)插入一个新的节点。
2.1 在单链表的开头插入一个新的节点
2.2在链接表的两个节点之间插入节点
2.3在链表末尾插入一个新的节点
具体实现过程如下。
| 步骤 | 操作 |
|---|---|
| 1 | 为新节点分配内存,为新节点的数据字段赋值
|
| 2 | 如果列表是空的,则执行以下步骤在列表中插入节点: a)使新节点的next字段指向 null; b)使新节点的prev字段指向 null;
|
| 3 | 如果将节点插人到列表的开头,执行以下步骤: a)使新节点的 next字段指向列表中的第一个节点; b)使start的prev字段指定该新节点, c)使新节点的 prev字段指向 null; d)使 start 指定该新节点。 |
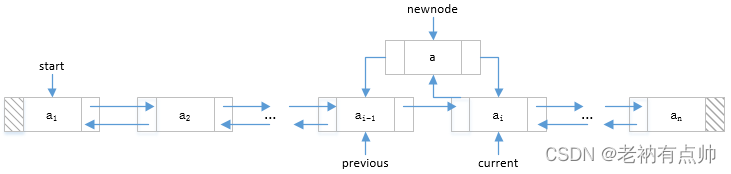
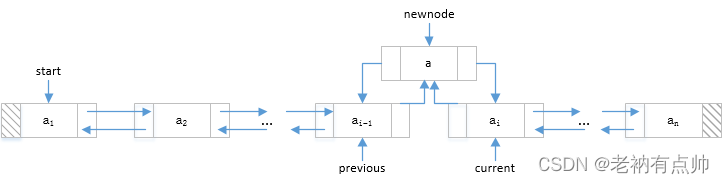
| 4 | 将新节点插入到现有的两个节点之间,执行以下步骤: a)使新节点的next指向当前节点
b)使新节点的 prev指向前一个节点
c)使当前节点的prev指向新节点
d)使前一个节点的next指向新节点
|
| 5 | 将新节点插人到列表的末尾,当移动 current 指针到最后一个节点时,执行下面的步骤: a)使当前节点的next 指定新节点; b)使新节点的prev指向当前节点; c)使新节点的 next为null。 |



3.删除操作
在双向链表中删除一个节点的具体算法如下:
| 步骤 | 操作 |
|---|---|
| 1 | 找到需删除的节点,将要删除的节点标记为当前节点 |
| 2 | 如果删除的节点为第一个节点,直接使 start 指向当前节点的下一个节点 |
| 3 | 如果删除的节点为两个节点之间的节点,执行以下步骤: a)使前一个节点的 next 字段指向当前节点的后面一个节点 b)使当前节点的后一个节点的 prev 字段指向前一个节点
c)释放标记为当前节点的节点内存
|
| 4 | 如果删除的为最后一个节点,只要执行删除的节点为两个节点之间的节点的步骤 a)和c) |


4.遍历双向链表的所有节点。
双向链表使你能够以正向和反向遍历列表。以正向遍历列表的算法是:
反向遍历双向链表的算法是:。
双向链表使你能够以正向和反向遍历列表。以正向遍历列表的算法是:
有关线性表的其他操作如求表长度、判断为空等操作在顺序表中的实现比较简单,参见以下的双链表C#代码:
/// <summary>
/// 双链表数据结构实现接口具体步骤
/// </summary>
public class DbLinkList<T>:ILinarList<T>
{
private DbNode<T> start;//双向链表的头引用
private int length;//双向链表的长度
/// <summary>
/// 初始化双向链表
/// </summary>
public DbLinkList()
{
start = null;
}
/// <summary>
/// 在双链表的末尾追加数据元素 data
/// </summary>
/// <param name="data">数据元素</param>
public void InsertNode(T data)
{
DbNode<T> newnode = new DbNode<T>(data);
if (IsEmpty())
{
start = newnode;
length++;
return;
}
DbNode<T> current = start;
while (current.Next!= null)
{
current = current.Next;
}
current.Next = newnode;
newnode.Prev = current;
newnode.Next = null;
length++;
}
/// <summary>
/// 在双链表的第i个数据元素的位置前插入一个数据元素data
/// </summary>
/// <param name="data">数据元素</param>
/// <param name="i">第i个数据元素的位置</param>
public void InsertNode(T data, int i)
{
DbNode<T> current;
DbNode<T> previous;
if (i < 1)
{
Console.WriteLine("Position is error");
return;
}
DbNode<T> newNode = new DbNode<T>(data);
//在空链表或第一个元素前插入第一个元素
if (i == 1)
{
newNode.Next = start;
start = newNode;
length++;
return;
}
//在双链表的两个元素间插入一个元素
current = start;
previous = null;
int j = 1;
while(current != null && j < i)
{
previous = current;
current = current.Next;
j++;
}
if (j == i)
{
newNode.Next = current;
newNode.Prev = previous;
if(current!= null)
{
current.Prev = newNode;
previous.Next = newNode;
}
length++;
}
}
/// <summary>
/// 删除双链表的第i个数据元素
/// </summary>
/// <param name="i"></param>
public void DeleteNode(int i)
{
if(IsEmpty() || i < 1)
{
Console.WriteLine("Link is empty or Position is error!");
}
DbNode<T> current = start;
if(i==1)
{
start = current.Next;
length--;
return;
}
DbNode<T> previous = null;
int j = 1;
while(current.Next != null && j<i)
{
previous = current;
current = current.Next;
j++;
}
if (j == i)
{
previous.Next = current.Next;
if(current.Next!= null)
{
current.Next.Prev = previous;
}
previous = null;
current = null;
length--;
}
else
{
Console.WriteLine("The ith node is not exist!");
}
}
/// <summary>
/// 获得双链表的第i个数据元素
/// </summary>
/// <param name="i"></param>
/// <returns></returns>
public T SearchNode(int i)
{
if (IsEmpty())
{
Console.WriteLine("List is empty!");
return default(T);
}
DbNode<T> current = start;
int j = 1;
while(current.Next != null && j<i)
{
current = current.Next;
j++;
}
if (j == i)
{
return current.Data;
}
else
{
Console.WriteLine("The ith node is not exist!");
return default(T);
}
}
/// <summary>
/// 在双链表中查找值为data的数据元素
/// </summary>
/// <param name="data"></param>
/// <returns></returns>
public T SearchNode(T data)
{
if (IsEmpty())
{
Console.WriteLine("List is Empty");
return default(T);
}
DbNode<T> current = start;
int i = 1;
while (current != null && !current.Data.Equals(data))
{
current = current.Next;
i++;
}
if(current != null)
{
return current.Data;
}
return default(T);
}
/// <summary>
/// 获取双链表的长度
/// </summary>
/// <returns></returns>
public int GetLength()
{
return length;
}
/// <summary>
/// 清空链表
/// </summary>
public void Clear()
{
start = null;
}
/// <summary>
/// 判断链表是否为空
/// </summary>
/// <returns></returns>
public bool IsEmpty()
{
if (start == null)
{
return true;
}
return false;
}
/// <summary>
/// 该函数将链表头节点反转后,重新作为链表的头节点。算法使用迭代方式实现,遍历链表并改变指针指向
/// 例如链表头节点start:由原来的
/// data:a,
/// prev:null,
/// next:[
/// data:b,
/// prev:a,
/// next:[
/// data:c,
/// prev:b,
/// next:null
/// ]
/// ]
///翻转后的结果为:
/// data:c,
/// prev:null,
/// next:[
/// data:b,
/// prev:c,
/// next:[
/// data:a,
/// prev:b,
/// next:null
/// ]
/// ]
/// </summary>
public void ReverseList()
{
if (length == 1 || IsEmpty())
{
return;
}
//定义 previous next 两个指针
DbNode<T> previous = null;
DbNode<T> next = null;
DbNode<T> current = this.start;
//循环操作
while (current != null)
{
//定义next为Head后面的数,定义previous为Head前面的数
next = current.Next;
current.Prev = next;
current.Next = previous;//这一部分可以理解为previous是Head前面的那个数。
//然后再把previous和Head都提前一位
previous = current;
current = next;
}
this.start = previous;
//循环结束后,返回新的表头,即原来表头的最后一个数。
return;
}
}实现方法和原理
在实现双向链表时,需要注意指针的正确性和内存管理等问题。为了提高性能和扩展性,可以使用哨兵节点、循环链表等技术对双向链表进行优化。
-
双向链表是一种常见的数据结构,与单向链表相比,它增加了一个指向前驱节点的指针,因此每个节点除了有指向后继节点的指针外,还有一个指向前驱节点的指针。下面介绍双向链表的实现方法和原理,主要包括以下几个方面:
-
节点定义:双向链表中每个节点都需要包含三个基本元素,一个是存储数据的变量,另外两个分别是指向前驱和后继节点的指针。
-
头节点和尾节点:头节点和尾节点是双向链表中的两个特殊节点,头节点没有前驱节点,尾节点没有后继节点。
-
添加操作:向双向链表中添加新节点,需要创建一个新节点,并将其插入到链表的合适位置上,同时设置新节点的前驱和后继指针。
-
删除操作:从双向链表中删除节点,需要找到待删除节点的前驱节点和后继节点,然后修改它们的前驱和后继指针,使其不再指向待删除节点。
-
查找操作:查找双向链表中的某个节点,可以从链表的头节点或尾节点开始遍历整个链表,直到找到目标节点或遍历完整个链表。
-
遍历操作:遍历双向链表,可以从链表的头节点或尾节点开始,依次输出每个节点的数据。
-
长度统计:统计双向链表中节点的数量,可以通过遍历链表并计数的方式来实现。
了解单链表的实现方法和原理对于理解链表性能和优化有很大帮助。同时,需要注意在具体实现时要根据实际情况进行合理的设计和优化,以提高代码的效率和可维护性。
应用场景和使用注意事项
单链表是一种常见的数据结构,常用于以下应用场景:
-
实现栈和队列:单链表可以用来实现栈和队列。在栈中,元素只能从栈顶进出;在队列中,元素只能从队尾进,队首出。利用单链表的头插和尾插操作,可以很方便地实现这两种数据结构。
-
内存分配:在计算机内存管理中,单链表常被用作动态内存分配的数据结构。通过链表节点之间的指针连接,可以动态地申请和释放内存块。
-
音频和视频播放列表:单链表可以用来实现音频和视频播放列表。每个节点表示一个音频或视频文件,并保存下一个文件的位置。通过遍历链表,可以依次播放整个列表中的音频和视频。
-
寻找环形结构:单链表也可以用来处理关于环形结构的问题,例如判断一个链表是否有环、找到环的入口等。
-
缓存淘汰策略:在缓存系统中,当缓存空间已满时,需要淘汰一些数据来腾出空间。单链表可以用来维护缓存中的数据项,同时记录它们的使用情况。当需要淘汰数据时,可以选择最近最少使用的数据项进行淘汰,即删除单链表尾部的节点。
在使用单链表时需要注意以下几点:
-
空指针问题:在链表操作中容易出现空指针问题,例如访问空链表或者一个不存在的节点等。为了避免这些问题,需要对输入参数进行判空处理。
-
内存管理问题:在插入和删除节点时需要分配或释放内存空间,如果管理不当容易出现内存泄漏或者重复释放等问题。可以使用垃圾回收机制或手动管理内存空间来解决这些问题。
-
边界条件问题:在进行链表操作时需要处理一些边界条件和异常情况,例如链表为空、插入位置超出范围等情况,以确保链表的正常运行。
-
性能问题:在处理大规模数据时,单链表会存在一些性能问题,例如随机访问速度较慢、空间开销较大等。因此在实际应用中需要根据实际情况选择合适的数据结构。
算法和复杂度分析:
常见的双向链表算法包括插入、删除和查找操作,下面对它们进行简要分析:
-
插入操作:在双向链表中插入一个节点时,需要找到待插入位置的前驱节点和后继节点,并修改它们的指针。时间复杂度为O(n)。
-
删除操作:在双向链表中删除一个节点时,也需要找到待删除节点的前驱节点和后继节点,并修改它们的指针。时间复杂度为O(n)。
-
查找操作:在双向链表中查找一个节点时,可以从头节点或尾节点开始遍历整个链表,直到找到目标节点或遍历完整个链表。时间复杂度为O(n)。
-
排序算法:双向链表可以使用插入排序、冒泡排序等算法进行排序,排序的时间复杂度取决于具体算法实现。
另外,在实际应用中,可以通过使用哨兵节点、循环链表等技术来优化双向链表的性能和扩展性。
总之,双向链表是一种常见的数据结构,具有良好的灵活性和扩展性。在实际使用中,需要根据具体情况选择合适的算法,并注意内存管理和指针操作。
与其他数据结构的比较:
双向链表是一种常见的数据结构,与其他数据结构相比较有以下优点和缺点:
-
与数组比较:双向链表可以动态增加和删除节点,不需要预先分配固定大小的空间,因此具有更好的灵活性。但是,双向链表的访问时间复杂度为O(n),而数组的访问时间复杂度为O(1),因此在随机访问和遍历操作比较频繁的情况下,数组可能更加高效。
-
与队列比较:双向链表和队列都可以实现FIFO(先进先出)的数据结构,但是双向链表相比队列更加灵活,可以支持在任意位置插入和删除节点,而队列只能在头部插入和尾部删除元素。
-
与栈比较:双向链表和栈都可以实现FILO(先进后出)的数据结构,但是双向链表相比栈更加灵活,可以支持在任意位置插入和删除节点,而栈只能在栈顶插入和删除元素。
-
与哈希表比较:双向链表和哈希表都是常用的数据结构,但是它们的应用场景不同。哈希表适用于快速查找和插入键值对的场景,而双向链表适用于需要频繁插入和删除元素的场景。
总之,双向链表具有一些特点,如动态性、灵活性等优点,但是在访问效率等方面可能不如其他数据结构。在实际应用中,需要根据具体情况选择合适的数据结构,并进行合理的权衡和折衷。