//自己做的有不对的请留言
1.与C语言相比,汇编语言的可移植性(C)
- 一样
- 不清楚
- 较差
- 较好
解析:
汇编是与当前硬件架构紧密相关的,比如你给x86 CPU写的汇编是无法用在 ARM 上面的(指令、寄存器等全都不一样)。即时是相同的架构,给32位CPU的汇编也无法用在16位的CPU上。汇编完全不具备可移植性。
C语言本身是硬件架构无关的,所以它是可以移植的。不同平台下的C编译器能将通用的C语言转换成对应平台(x86,arm,等等)下的汇编语言。(比如常用的编译器gcc可以用 gcc -S a.c 就是将a.c转换成对应的汇编a.s)
2.下面描述错误的是()
- public成员集成为类的接口
- private成员可以在类外部访问
- 类成员由private,protected,public决定访问特性
- 所有成员都可以被外部访问
*3.关于语句char ptr = malloc(0)以下描述错误的是(C)
- 当返回具体内存值时,ptr占用一定的内存空间
- 可能返回一个具体的数值
- 可能返回NULL
- 当返回具体内存值时,ptr占用内存空间不能被使用或者释放
解析
当使用malloc后,只有在没有足够内存的情况下才会返回NULL ,或者异常报告
malloc(0),表示系统已经帮你准备好了堆栈中使用的起始地址只是不允许读写而已,
NULL 一般定义为 (void *)0,指向0的地址,malloc是程序在堆栈中分配空间,不会是0地址
例如:
int pp =(strlen((ptr=(char *)malloc(0))0显示错误
malloc(0)是指分配空间内存大小为0
NULL是不指向任何实体
mallo(0)也是一种存在不是NULL
**4.假设char test[8]={0x01,0x02,0x03,0x04,0x05,0x06,0x07,0x08};int test_p = (int )test 表达式 int a=test_p[1];以大端模式存储在1000~1003H的内存地址上,则1000H上存储的是(D)
- 0x01
- 0x02
- 0x05
- 0x08
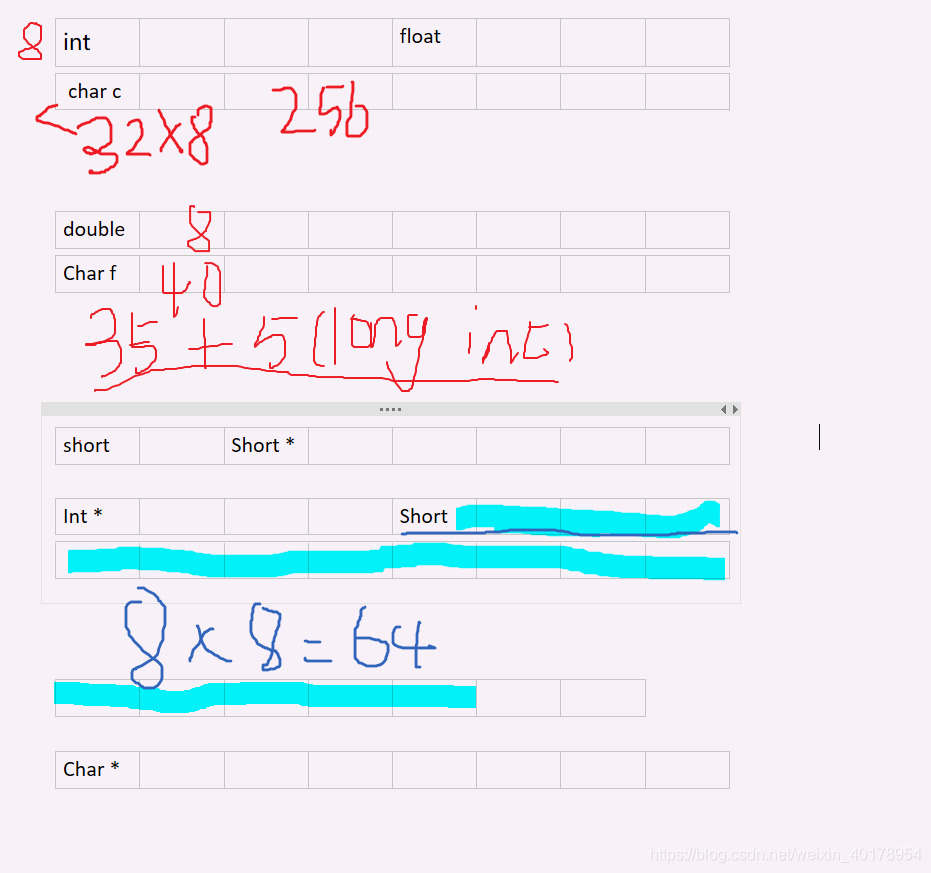
5.32位系统中有如下结构体:
typedef struct{ int a; float b; char c[253]; double d; char f[35]; long int e; short g; short *ptr; int *ptr2; short h[33]; char *ptr3; }HKVISION; sizeof(HKVISION)? 怎么优化??
400
优化
int a;
float b;
double b;
long int e;
char *ptr3;
short *ptr;
int *ptr2;
char c[253];
char f[35];
short h[33];
short g;
知识点
不同的地方在于指针 char * long 和 unsigned long
32位编译器:
char :1个字节
char*(即指针变量): 4个字节(32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)
short :2
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 4个字节
long long: 8个字节
unsigned long: 4个字节
64位编译器:
char :1个字节
char*(即指针变量): 8个字节
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 8个字节
long long: 8个字节
unsigned long: 8个字节
5.Linux系统中线程什么是不能共享的(C)
- 全局变量
- 堆
- 栈
- 文件句柄
考点
进程和线程的区别—背诵
6.二叉树描述正确的是(D)
- 二叉树的深度不超过256
- 满二叉树又叫做完全二叉树
- 二叉树子树没有左右之分
- 二叉树每个节点最多两个子树
二叉树知识点
https://blog.csdn.net/u013834525/article/details/80506126
7.TCP工作原理错误的是(D)
- 应用数据被分割成TCP认为最合适发送的数据块
- TCP提供流量控制
- TCP保持他首部和数据校验和,这是一个端到端的校验
- TCP报文段作为IP数据报来传送,而IP数据报到达可能会失序,因此TCP报文到达可能会失序这种情况应用层收到的也是失序的
8.MTU指定了网络中可传输数据包的最大尺寸,常用在以太网中,MTU是几个字节(A)
- 1500
- 随机
- 1024
- 100
这里要和IP 端口区分开来—65536
协议还可以改正
mss
9.32位的程序最大寻址空间是(C)
- 2G
- 1G
- 4G
- 8G
2^32=4G
10.cpu能够执行的是(D)
- 机器语言直接执行
- 机器语言与汇编语言
- 机器语言与汇编语言与硬件描述语言程序
- 机器语言和硬件描述语言程序
11.一下那些方式可以实现Linux 系统下的进程间通信(ABC)
- Socket
- 管道
- 信号
- 全局变量
12.Head和Stack内存空间描述正确的是(CD)
- c中的maloc空间分配是在stack中
- 程序运行过程中函数调用时参数的传递在stack上进行
- stack空间分配由操作系统自动进行分配
- heap上的空间手动分配和释放
13.下面关于中断处理函数说法正确的是(AC)
- 中断处理函数没有返回值
- 中断处理函数可以有返回值
- 中断处理函数没有参数
- 中断处理函数可以有参数
14.下面描述正确的是(ABD)
- 调用函数的时候,实参和形参类型可以不一致
- 调用函数时,实参可以是表达式
- 调用函数时,实参和形参可以共用内存单元
- 调用函数时,程序会为实参和形参分配内存空间
我感觉实参和形参可以一样也可以不一样
形参变量只有在被调用时才分配内存单元,在调用结束时,即可释放所分配的内存单元。因而,形参只有在函数内部有效。函数调用结束后返回主调函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。
因此应预先用赋值、输入等办法使实参获得确定值。
函数调用中发生的数据传送是单向的。 即 只能把实参的值传送给形参,而不能把形参的值反向传送给实参。因此 在函数调用过程中,形参的值发生改变,而实参中的值不会变化
15.已只一个数组table 请利用宏定义求出数组元素的个数
#define N (sizeof(table)/sizeof(table[0]))
16.进程和线程的区别
- 进程是系统资源分配的最小的单位,线程是程序执行的最小单位
- 进程有自己独立的地址空间,每次启动一个进程,系统都会为他自动分配,数据段,代码段,堆栈段,这种操作非常昂贵,而线程和进程共享相同资源仅仅拥有自己的局部变量(栈),共享全局变量和堆,文件句柄等,因此cpu 花销线程明显少于进程
- 线程通信比进程方便得多,但是需要处理好同步和互斥,相同进程下需要用到IP C
- 多进程不容易让程序崩溃,而线程容易因为一个线程掉线导致程序崩溃
**16.程序实现单链表节点Link的定义插入link *insertElem(link *p,int elem,int add),查询 int findElem(link *p,int elem)删除 link deleteElem(link p, int add)
typedef struct node{
int elem;
struct node *next;
}link;
link *insertElem(link *p,int elem,int add){
//操作变量临时
link *temp = p;
//先找到要插入节点的位置
for(int i=0;i<add;i++){
if(temp=NULL){
printf("the position is invalid");
return p;
}
temp=temp->next;
}
//创建插入的节点
link *c=(link *)malloc(link);
c->elem=elem;
//进行插入,先把尾巴查起来
c->next = temp->next;
temp->next=c;
return p
}
int findElem(link *p,int elem){
while(p->next !=NULL){
if(p->elem == elem){
printf( "I have find the elem %d",p->elem);
return p->elem;
}
p=p->next;
}
printf("not found!!\n");
return 0;
}
link *delete(link *p,int add){
link *temp=p;
link *pre_node=p;
if(add==0){//说明是头节点
p=p->next;
free(temp);
return p;
}else{
for(int i=0;i<add;i++){
//记录链表的上一个节点
pre_node=temp;
temp=temp->next;
}
if(p->next == NULL){//说明是尾巴节点
pre_node->next=NULL;
free(temp);
return p;
}else{//中间节点
pre_node->next=pre_node->next-next;
free(temp);
return p;
}
}
}