A题 影响城市居民身体健康的因素分析
以心脑血管疾病、糖尿病、恶性肿瘤以及慢性阻塞性肺病为代表的慢性非传染性疾病(以下简称慢性病)已经成为影响我国居民身体健康的重要问题。随着人们生活方式的改变,慢性病的患病率持续攀升。
众所周知,健康状况与年龄、饮食习惯、身体活动情况、职业等都有密切的关系。如何通过合理地安排膳食、适量的身体运动、践行健康的生活方式,从而达到促进身体健康的目的,这是全社会普遍关注的问题。附件A1是某市卫生健康研究部门对部分居民所做的“慢性非传染性疾病及其相关影响因素流行病学”调查问卷表,附件A2是相应的调查数据结果,附件A3是中国营养学会最新修订的《中国居民膳食指南》中为平衡居民膳食提出的八条准则。
请你们团队研究解决下面问题:
- 问题1:参考附件A3,分析附件A2中居民的饮食习惯的合理性,并说明存在的主要问题。
- 问题2:分析居民的生活习惯和饮食习惯是否与年龄、性别、婚姻状况、文化程度、职业等因素相关。
- 问题3:根据附件A2中的数据,深入分析常见慢性病(如高血压、糖尿病等)与吸烟、饮酒、饮食习惯、生活习惯、工作性质、运动等因素的关系以及相关程度。
- 问题4:依据附件A2中居民的具体情况,对居民进行合理分类,并针对各类人群提出有利于身体健康的膳食、运动等方面的合理建议。
解题思路
首先,需要先进行数据预处理,主要分成三个部分:
- 删除空行;
- 给未标号的群众添加ID号;
- 对缺失数进行填补。
第一问
- 根据附件A3,构建若干项得分细则
- 依据满足条件的比例进行赋分
- 并根据每个得分项绘制箱线图观察饮食习惯的合理性,并从中判断存在的主要问题
第二问
- 在饮食习惯得分表的基础上添加若干项,构建生活习惯得分表
- 然后基于AHP-TOPSIS模型计算每位居民在饮食习惯与生活习惯上的得分,并对得分进行Kolmogorov-Smirnov分布检验
- 将影响因素分为有序因素及无序因素两类:
- 对于有序因素,采用皮尔逊或斯皮尔曼相关性系数进行分析,并绘制热力图。
- 对于无序因素,在进行方差齐性检验后进行Kruskal-Wallis H检验,以判断相关性。
第三问
- 构建BP神经网络,先根据吸烟、饮酒、饮食习惯、生活习惯、工作性质、运动等因素构建若干特征,
- 分别对高血压与糖尿病进行预测
- 然后基于训练好的网络,进行贡献率反解,以此来表征常见慢性病与各因素的相关程度。
第四问
- 先对各居民习惯进行因子分析,将习惯进行归类
- 然后对降维后的因子得分进行K-means聚类分析,并绘制分布图,以此表征每位居民在习惯上的缺陷,并给予相应的建议。
技术文档
计算每位居民的饮食习惯得分,每位居民总共5个分数(另外三个准则无法量化或被下述5个准则包含)
例如,若要满足要求1,调查表的结果中需要同时满足2,3,{5,6},若调查表中只满足了其中一个,则要求1的得分为0.3333分。
记S(X)表示:当第X列的值为非0值时,取1;反之取0。
计D(X)表示:第X列的值
每个要求对应要满足的序号如下表所示:
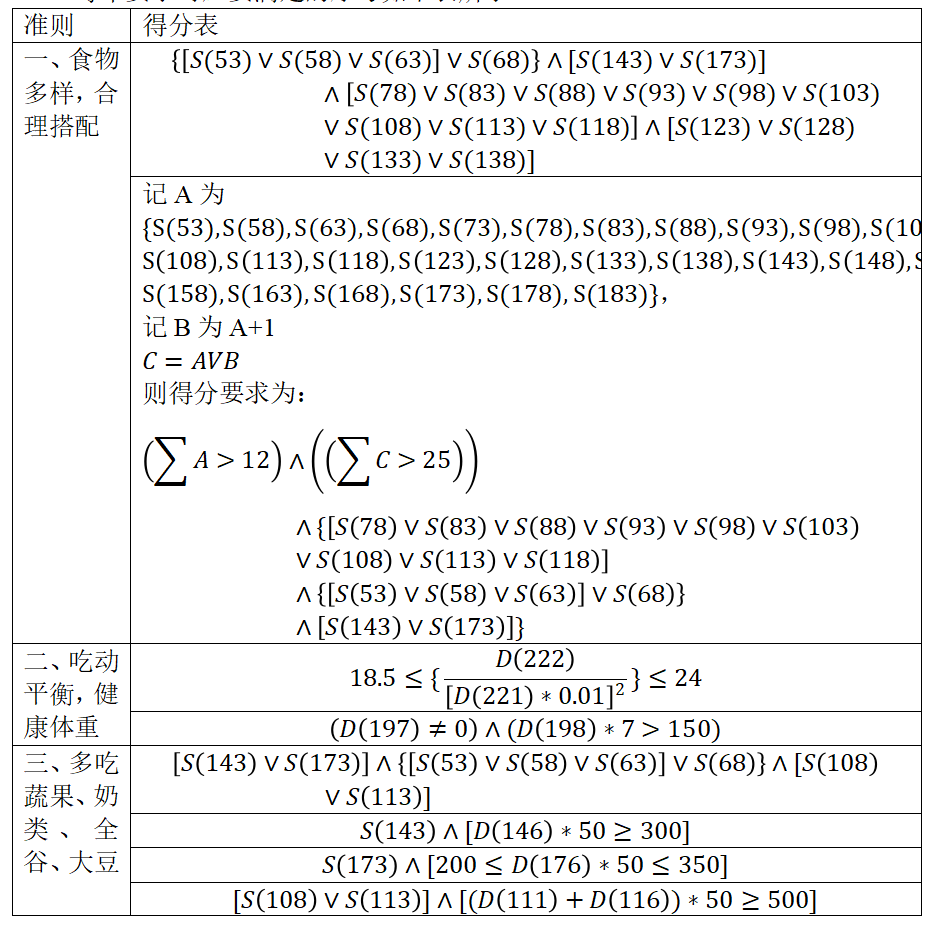

绘制箱线图来表述得分的分布情况:
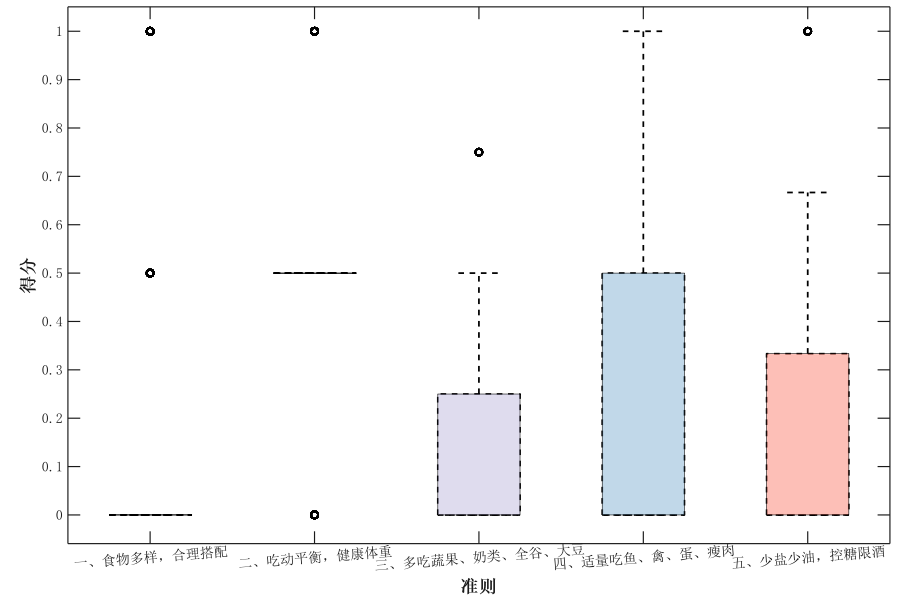
由图即可分析居民在各个准则下的得分分布情况。例如:居民在准则一的得分最低,说明居民的饮食在“事务多样、合理搭配”这一个方面不够合理。
第一问完整代码
clc
clear
data=xlsread('深圳杯\A题-附件\附件2 慢性病及相关因素流调数据.xlsx');
data(1:2,:)=[];
label=data(:,1);
data(:,1)=[];
for i=1:size(data,1)
for j=1:size(data,2)
if isnan(data(i,j))
data(i,j)=0;
end
end
end
score=[]; %用于存放得分
%% 计算第一个得分
SumA=2; %A的得分条款数
temp_record=zeros(size(data,1),1);
for i=1:size(data,1) %遍历每一个人
if ((data(i,53)>0||data(i,58)>0||data(i,63)>0)||data(i,68)>0)&&(data(i,143)>0||data(i,173)>0)&&(data(i,78)>0||data(i,83)>0||data(i,88)>0||data(i,93)>0||data(i,98)>0||data(i,103)>0||data(i,108)>0||data(i,113)>0||data(i,118)>0)&&(data(i,123)>0||data(i,128)>0||data(i,133)>0||data(i,138)>0)
temp_record(i,1)=temp_record(i,1)+1;
end
A=[data(i,53),data(i,58),data(i,63),data(i,68),data(i,73),data(i,78),data(i,83),data(i,88),data(i,93),data(i,98),data(i,103),data(i,108),data(i,113),data(i,118),data(i,123),data(i,128),data(i,133),data(i,138),data(i,143),data(i,148),data(i,153),data(i,158),data(i,163),data(i,168),data(i,173),data(i,178),data(i,183)];
B=[data(i,54),data(i,59),data(i,64),data(i,69),data(i,74),data(i,79),data(i,84),data(i,89),data(i,94),data(i,99),data(i,104),data(i,109),data(i,114),data(i,119),data(i,124),data(i,129),data(i,134),data(i,139),data(i,144),data(i,149),data(i,154),data(i,159),data(i,164),data(i,169),data(i,174),data(i,179),data(i,194)];
for k=1:size(A,2)
if A(k)>0||B(k)>0
C(k)= 1;
end
end
if ((sum(A)>12)&&(sum(C)>25))&&((data(i,78)||data(i,83)||data(i,88)||data(i,93)||data(i,98)||data(i,103)||data(i,108)||data(i,113)||data(i,118))&&((data(i,53)||data(i,58)||data(i,63))||data(i,68))&&(data(i,143)||data(i,173)))
temp_record(i,1)=temp_record(i,1)+1;
end
score(i,1)=temp_record(i,1)/SumA;
end
%% 计算第二个得分
SumB=2; %A的得分条款数
temp_record=zeros(size(data,1),1);
for i=1:size(data,1) %遍历每一个人
if 18.5<=data(i,222)/((data(i,221)*0.01).^2)&&data(i,222)/((data(i,221)*0.01).^2)<=24
temp_record(i,1)=temp_record(i,1)+1;
end
if data(i,197~=0)&&((data(i,198)*7)>150)
temp_record(i,1)=temp_record(i,1)+1;
end
score(i,2)=temp_record(i,1)/SumB;
end
%% 计算第三个得分
SumC=4; %A的得分条款数
temp_record=zeros(size(data,1),1);
for i=1:size(data,1) %遍历每一个人
if (data(i,143)>0||data(i,173)>0)&&((data(i,53)>0||data(i,58)>0||data(i,63)>0)||data(i,68)>0)&&(data(i,108)>0||data(i,113)>0)
temp_record(i,1)=temp_record(i,1)+1;
end
if data(i,143)>0&&((data(i,146)*50)>=300)
temp_record(i,1)=temp_record(i,1)+1;
end
if data(i,173)>0&&(200<=(data(i,176)*50)&&(data(i,176)*50)<=350)
temp_record(i,1)=temp_record(i,1)+1;
end
if (data(i,108)>0||data(i,113)>0)&&(((data(i,111)+data(i,116))*50)>=500)
temp_record(i,1)=temp_record(i,1)+1;
end
score(i,3)=temp_record(i,1)/SumC;
end
%% 计算第四个得分
SumD=2;
temp_record=zeros(size(data,1),1);
for i=1:size(data,1) %遍历每一个人
if 120<=(((data(i,78)>0)*data(i,81))+((data(i,79)>0)*data(i,81)/7)+((data(i,80)>0)*data(i,81)/31)+...
((data(i,83)>0)*data(i,86))+((data(i,84)>0)*data(i,86)/7)+((data(i,85)>0)*data(i,86)/31)+...
((data(i,88)>0)*data(i,91))+((data(i,89)>0)*data(i,91)/7)+((data(i,90)>0)*data(i,91)/31)+...
((data(i,93)>0)*data(i,96))+((data(i,94)>0)*data(i,96)/7)+((data(i,95)>0)*data(i,96)/31)+...
((data(i,98)>0)*data(i,101))+((data(i,99)>0)*data(i,101)/7)+((data(i,100)>0)*data(i,101)/31))...
*50 ...
&&...
(((data(i,78)>0)*data(i,81))+((data(i,79)>0)*data(i,81)/7)+((data(i,80)>0)*data(i,81)/31)+...
((data(i,83)>0)*data(i,86))+((data(i,84)>0)*data(i,86)/7)+((data(i,85)>0)*data(i,86)/31)+...
((data(i,88)>0)*data(i,91))+((data(i,89)>0)*data(i,91)/7)+((data(i,90)>0)*data(i,91)/31)+...
((data(i,93)>0)*data(i,96))+((data(i,94)>0)*data(i,96)/7)+((data(i,95)>0)*data(i,96)/31)+...
((data(i,98)>0)*data(i,101))+((data(i,99)>0)*data(i,101)/7)+((data(i,100)>0)*data(i,101)/31))...
*50<=200
temp_record(i,1)=temp_record(i,1)+1;
end
if data(i,99)==2&&data(i,118)==1
temp_record(i,1)=temp_record(i,1)+1;
end
score(i,4)=temp_record(i,1)/SumD;
end
%% 计算第五个得分
SumE=3;
temp_record=zeros(size(data,1),1);
for i=1:size(data,1) %遍历每一个人
if 25<=((data(i,187)+data(i,188))*500/2.5/31) && ((data(i,187)+data(i,188))*500/2.5/31)<=30
temp_record(i,1)=temp_record(i,1)+1;
end
if (data(i,178)==0) && (data(i,183)==0) && (data(i,200)==1&&data(i,14)==2)
temp_record(i,1)=temp_record(i,1)+1;
end
if ((data(i,189)*50/2.5/31)<5) && (data(i,17)+data(i,18)+data(i,20)+data(i,21)+data(i,23)+data(i,24)+data(i,26)+data(i,27)+data(i,29)+data(i,30))*50/7<15
temp_record(i,1)=temp_record(i,1)+1;
end
score(i,5)=temp_record(i,1)/SumE;
end
%% 绘制箱线图
h = boxplot(score,'Colors','k','Symbol','o','labels',{
'一、食物多样,合理搭配','二、吃动平衡,健康体重','三、多吃蔬果、奶类、全谷、大豆','四、适量吃鱼、禽、蛋、瘦肉','五、少盐少油,控糖限酒'});
% hTitle = title('Miles per Gallon by Vehicle Origin');
hXLabel = xlabel('准则');
hYLabel = ylabel('得分');
% 线宽
set(h,'LineWidth',1.5)
% 坐标轴美化
set(gca, 'Box', 'on', ... % 边框
'LineWidth', 1,... % 线宽
'XGrid', 'off', 'YGrid', 'off', ... % 网格
'TickDir', 'in', 'TickLength', [.015 .015], ... % 刻度
'XMinorTick', 'off', 'YMinorTick', 'off', ... % 小刻度
'XColor', [.1 .1 .1], 'YColor', [.1 .1 .1]) % 坐标轴颜色
% 字体和字号
set(gca, 'FontName', '宋体')
set([hXLabel, hYLabel], 'FontName', '宋体')
set(gca, 'FontSize', 12)
set([hXLabel, hYLabel], 'FontSize', 15)
% set(hTitle, 'FontSize', 11, 'FontWeight' , 'bold')
% 背景颜色
set(gcf,'Color',[1 1 1])
%箱子颜色
color = [250/255,127/255,111/255;
130/255,176/255,210/255;
190/255,184/255,220/255;
231/255,218/255,210/255;
153/255,153/255,153/255];
h = findobj(gca,'Tag','Box');
for j=1:length(h)
patch(get(h(j),'XData'),get(h(j),'YData'),color(j,:),'FaceAlpha',.5);
end
c = get(gca, 'Children');
%图注
% hleg1 = legend(c(1:2:8,:), 'MSE','MAE','MAPE');
写在最后
下面是学姐自己整理的完整代码与运行结果,需要的同学欢迎咨询~