
Title: Tracking Anything in High Quality
PDF: https://arxiv.org/pdf/2307.13974v1.pdf
Code: https://github.com/jiawen-zhu/hqtrack
导读
本文介绍了一种名为HQTrack的高质量视频目标跟踪框架。视频目标跟踪是计算机视觉中基础的视频任务。近年来,感知算法的显著增强使得单/多目标和基于框/蒙版的跟踪得以统一。其中Segment Anything Model(SAM)引起了广泛的关注。
HQTrack主要由两个组件构成:视频多目标分割器(VMOS)和蒙版优化器(Mask Refine)。在视频的初始帧中给定要跟踪的目标,VMOS将目标蒙版传播到当前帧。然而,由于VMOS是在几个相似的视频对象分割(VOS)数据集上训练的,其在复杂和边角场景的泛化能力有限,因此在这一阶段得到的蒙版(Mask)结果可能不够精确。
为了进一步提高跟踪蒙版的质量,作者采用了一个预训练的MR模型来优化跟踪结果。值得注意的是,HQTrack在视觉目标跟踪和分割(VOTS2023)挑战中排名第二,而且没有使用任何测试时的数据增强或模型集成等技巧,充分证明了该方法的有效性。
引言
作为跟踪领域中最具影响力的挑战之一,视觉目标跟踪(VOT)面临着诸多挑战,例如目标间关系的理解、多目标轨迹跟踪、精确的蒙版估计等。
视觉目标跟踪借助深度学习技术取得了巨大进展,当下主流的跟踪方法都是基于Transformer框架。TransT 提出了基于Transformer的ECA和CFA模块,用来替代长期以来使用的相关计算。最近,一些跟踪器引入了纯Transformer架构,特征提取和模板搜索区域交互在单个主干网络中完成,跟踪性能被推向新的高度。这些跟踪器主要关注单一目标跟踪,并输出边界框用于性能评估。因此,仅使用SOT跟踪器并不适用于VOTS2023挑战。
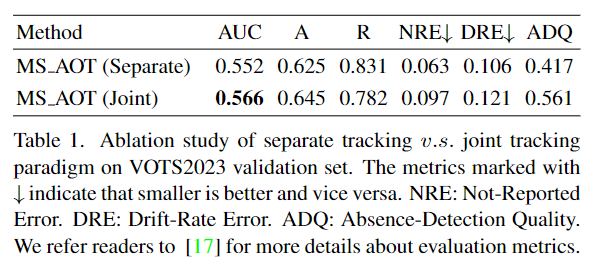
视频目标分割的目标是在视频序列中分割出感兴趣的特定目标对象。HQTrack主要由视频多目标分割器(VMOS)和蒙版优化器(MR)组成。通过级联1/8比例的门控传播模块(GPM)来感知复杂场景中的小物体,此外,作者采用Intern-T作为特征提取器,以增强目标的区分能力。为了节省内存使用,VMOS中使用固定长度的长期记忆,在初始帧之后的早期帧的记忆将被丢弃。另一方面,为了进一步提高跟踪蒙版的质量,作者采用了一个预训练的HQ-SAM模型来优化跟踪蒙版。作者从VMOS中计算预测蒙版的外部包围框作为提示框,并将它们与原始图像一起输入到HQ-SAM中来得到优化后的蒙版。最终的跟踪结果是从VMOS和MR中选择的。
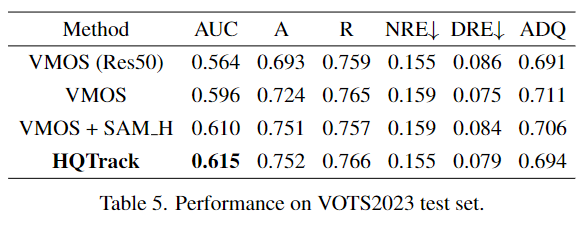
在VOTS2023挑战赛中,其测试视频包含大量长期序列,最长的超过10,000帧,这要求跟踪器能够区分目标外观的剧烈变化,并适应环境的变化。长期视频序列也使得一些基于内存的方法面临内存空间的挑战。另外,VOTS视频中的目标会离开视野,然后再次出现,因此跟踪器需要额外的设计来适应目标的消失和出现。此外,快速运动、频繁遮挡、干扰物和小物体等一系列挑战也使得这个任务更加困难。HQTrack通过使用VMOS和MR的组合,以及采用HQ-SAM来优化蒙版,在VOTS2023挑战赛中获得了亚军。
方法
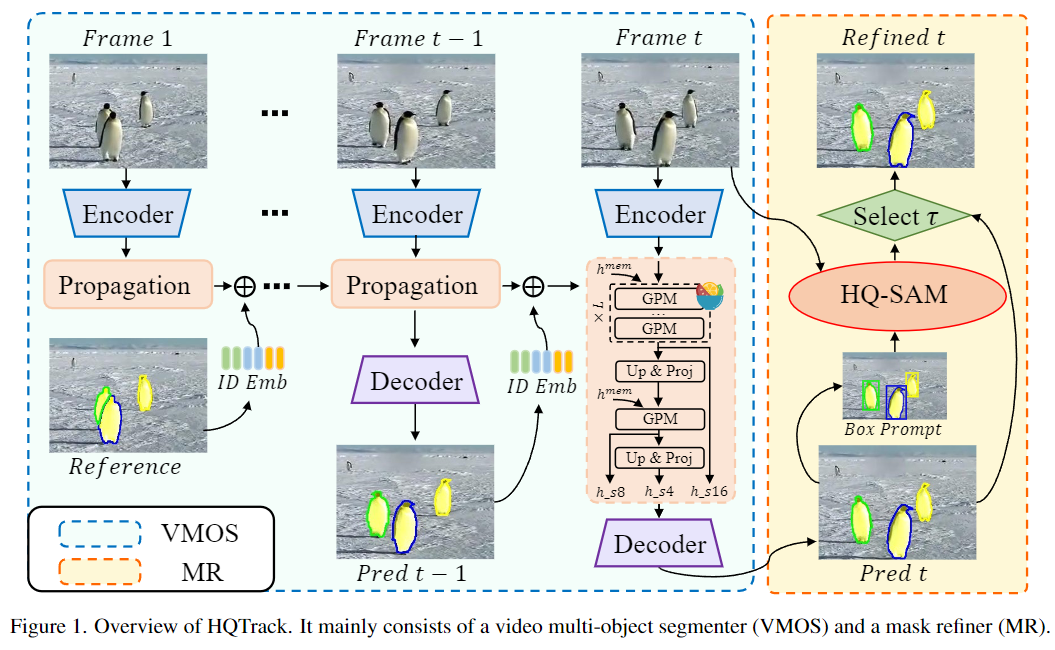
如上图1所示,给定一个视频和第一帧的参考蒙版(带有标注),HQTrack首先通过VMOS对每帧进行目标物体分割。当前帧的分割结果来自于第一帧沿时间维度的传播,利用外观/识别信息和长期/短期记忆的建模。VMOS是DeAOT的一个变体,因此可以在单个传播过程中完成多个目标物体的建模。此外,作者使用HQ-SAM作为MR来优化VMOS的分割蒙版。首先,我们对VMOS预测的目标蒙版进行边界框提取,然后将它们作为提示框输入到HQ-SAM模型中。最后设计了一个蒙版选择器来从VMOS和MR中选择最终的结果。
视频多目标分割器(VMOS)
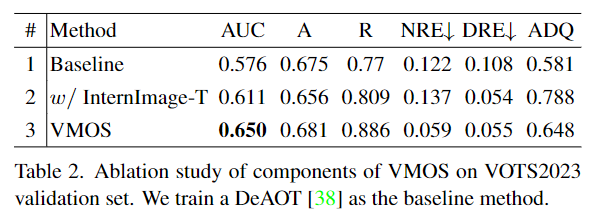
VMOS是DeAOT的一个变体。为了提高分割性能,特别是感知小物体,作者在VMOS中级联了一个8倍比例的GPM,并将传播过程扩展到多个尺度。原始的DeAOT只在16倍比例的视觉和识别特征上进行传播操作,在这个尺度上,很多细节的目标线索会丢失,特别是对于小物体来说,16倍比例的特征不足以进行准确的视频目标分割。在VMOS中,为了考虑内存使用和模型效率,作者只使用上采样和线性投影将传播特征升级到4倍比例。多尺度传播特征将与多尺度编码器特征一起输入到解码器中进行蒙版预测。解码器采用了简单的FPN结构。此外,作为一个新的大规模基于CNN的基础模型,Internimage采用可变形卷积作为核心运算符,在各种典型任务上表现出色,例如目标检测和分割。
蒙版优化器(MR)
MR是一个预训练的HQ-SAM模型(它比SAM能够提供更加精细化的分割结果)。除了大规模训练带来的强大的零样本能力之外,SAM还涉及由不同提示格式实现的灵活的人机交互机制。然而,当处理包含复杂结构对象的图像时,SAM的预测蒙版往往不够准确。为了解决这个问题,同时保持SAM的原始提示设计、效率和零样本泛化性能,所以有研究学者就提出了HQ-SAM,它仅在预训练的SAM模型中引入了一些额外的参数,就能够达到更加精确的分割结果。而本文借助了HQ-SAM,通过将学习输出token注入到SAM的蒙版解码器中,可以获得高质量的蒙版。
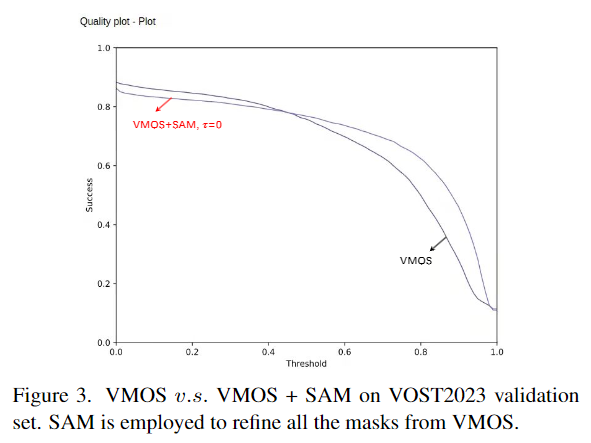
如上图1右侧所示,作者将VMOS预测的蒙版作为MR的输入。由于VMOS模型是在尺度有限的封闭数据集上训练的,来自VMOS的第一阶段预测蒙版可能精度不高,尤其是在处理一些复杂情况时。因此,使用大规模训练的分割算法来优化初步分割结果将带来显著的性能改进。
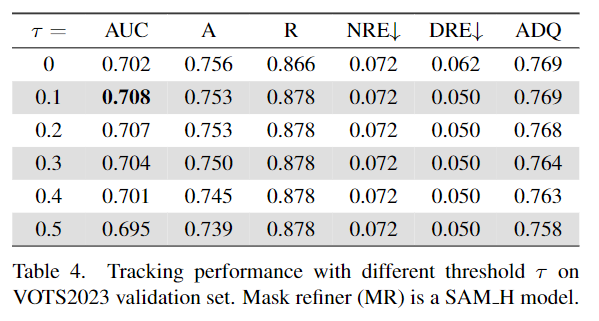
具体而言,作者计算VMOS预测蒙版的外包围框作为提示框,并将它们与原始图像一起输入到HQ-SAM中来获得优化后的蒙版。最后,HQTrack的输出蒙版是从VMOS和HQ-SAM的蒙版结果中选择的。作者发现,对于相同的目标物体,HQ-SAM优化后的蒙版有时与VMOS预测的蒙版完全不同(IoU得分很低),这反而损害了分割性能。这可能是HQ-SAM和参考注释之间对目标的不同理解和定义导致的。因此,作者设置了一个IoU阈值τ(来自VMOS和HQ-SAM的蒙版之间的IoU)来确定哪个蒙版将被用作最终的输出。在这种情况下,只有当IoU得分高于τ时,我们才会选择优化后的蒙版。这个过程使得HQ-SAM专注于优化当前的目标蒙版,而不是重新预测另一个目标物体。
实现细节
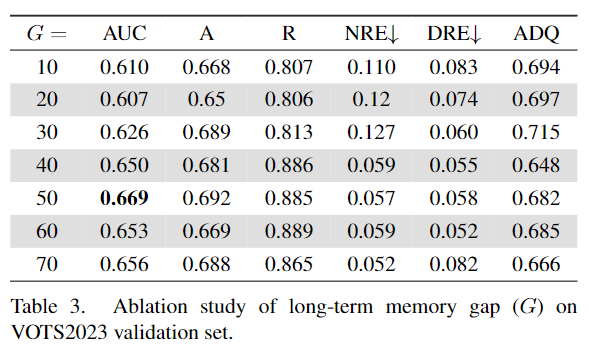
在HQTrack的VMOS中,使用InternImage-T作为图像编码器的主干网络,以在准确性和效率之间进行权衡。对于16×和8×比例的GMP层的数量分别设置为3和1。4×比例的传播特征经过上采样和来自8×比例的投影特征处理。HQTrack的分割器使用长期和短期记忆来处理长期视频序列中的目标外观变化。为了节省内存使用,作者使用长度为8的固定长期记忆,不包括初始帧,前期的记忆将被丢弃。
模型训练
训练过程包括两个阶段,在第一阶段,先由静态图像数据集生成的合成视频序列上对VMOS进行预训练;在第二阶段,VMOS使用多目标分割数据集进行训练,以更好地理解多个目标之间的关系。并选择了DAVIS、YoutubeVOS、VIPSeg、BURST、MOTS和OVIS的训练数据集来训练VMOS,其中OVIS被用来提高跟踪器处理遮挡目标的鲁棒性。
推理
推理过程如上图1流程所示。本文没有使用任何测试时数据增强(TTA),如翻转、多尺度测试和模型集成。
实验结果


结论
本文提出了一种高质量视频多目标跟踪(HQTrack)方法。HQTrack主要由视频多目标分割器(VMOS)和蒙版优化器(MR)组成。VMOS负责在视频帧中传播多个目标,而MR是一个大规模预训练的分割模型,负责优化分割蒙版。HQTrack展现出强大的目标跟踪和分割能力,并在视觉目标跟踪和分割(VOTS2023)挑战中,斩获亚军。