导读:本次分享题目为字节跳动大数据平台安全与权限治理实践,文章会围绕下面四点展开:
字节大数据安全体系现状和难点
细粒度权限管控和治理
资产保护能力
数据删除能力
分享嘉宾|许从余 火山引擎 数据平台产品经理
编辑整理|杨佳慧
出品社区|DataFun
01字节大数据安全体系现状和难点
第一部分首先分享字节跳动大数据平台安全与权限治理平台的完整体系以及目前的现状和面临的难点。
1. 字节跳动大数据安全产品体系

数据分类分级:根据字节内部数据既定的分类分级标准进行管理,并形成自动识别及确认落标的完整闭环。
权限管理:涵盖了从申请数据使用授权到库表行列权限的管控,其中包括数据拥有权限、数据权限有效期、数据权限主动交还以及冗余权限回收治理等。
风控审计:主要包括 6 部分其中可根据对象不同分为用户风控审计和数据风控审计。风控审计能够主动识别用户是否为风险用户、用户行为的定级、用户高危行为识别以及人员异动监控识别等,比如人员转岗和离职时对数据的处置。数据审计:数据审计主要分为三部分,数据的访问行为审计、数据授权的审计以及聚焦于数据安全产品本身可操作行为的审计。
资产保护:主要包含三部分,数据加密存储、数据解密使用以及数据脱敏。
数据销毁:作为全数据生命周期最终阶段,也是字节跳动大数据平台的最后一部分。由于数据删除所对应法律法规的要求,字节内部应合规管控衍生出处理数据删除的专项产品从而使数据删除工作满足法律法规的要求。
2. 治理原则:保证合规兼顾效率

(1)数据安全治理的压力=外部压力+内部压力
外部压力:数据安全外部压力主要来自于安全合规的风险压力。数据作为业务的驱动力如果不能够在使用时提供足够的灵活筛选、保留和删除等操作就会使业务处于巨大的风险境地。
内部压力:数据作为内部核心业务流转的血液,提供首要数据效率作用的同时要兼顾外部刚性的要求和合规机制。
(2)数据治理原则=保证合规+兼顾效率
根据数据安全治理内外部压力的分布,其实可以清晰的得知数据治理原则会主要围绕着《保证合规、兼顾效率》这八个字展开。
那如何能够保证合规的同时兼顾效率实现和谐共处,以下部分会从字节跳动大数据平台的数据权限模型的升级:权限模型三大特性和原子层级的权限管控和治理来讨论。
02细粒度权限管控和治理
1. 列级权限控制
情况一:数据权限管理升级新特性,权限申请可以按照数据列来提交,同时也体现了字节大数据平台升级后的最小化数据维度为列。

2. 表/列权限附带行限制
情况一:行数据最小原则,表权限+行限制
用户在拥有访问表权限的同时对行进行数据权限的限制。例如E部分数据限制的情况为拥有表权限的同时附带行限制,此部分限制为性别为男且国家为美国和加拿大。
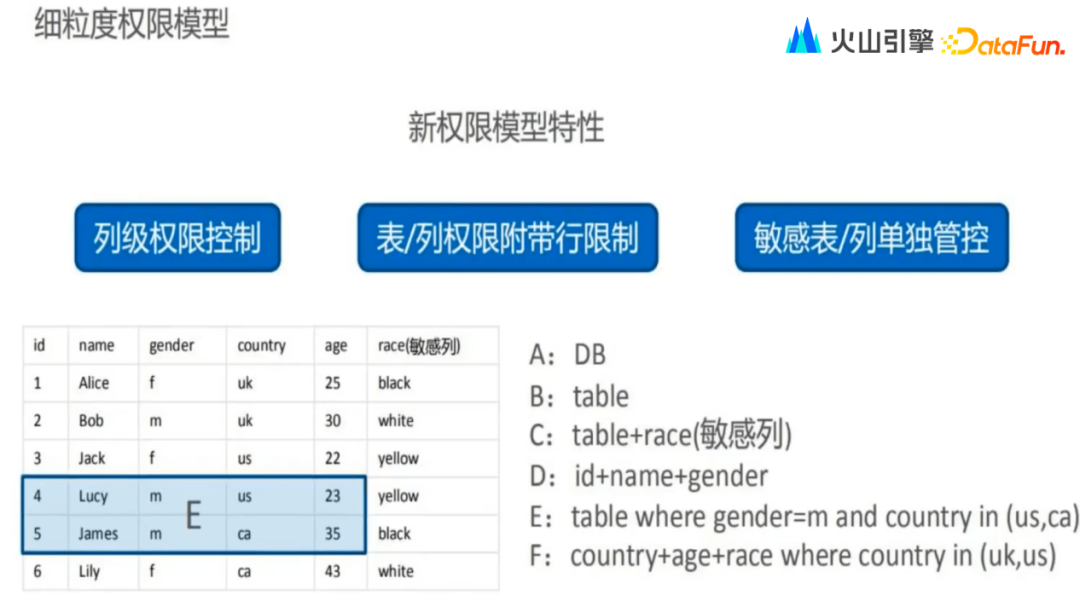
情况二:行数据最小原则,列权限+行限制
用户在拥有访问敏感列权限和 Country、Age 列权限的同时对行进行数据权限的限制。例如F部分,此部分数据限制为敏感列权限和 Country、Age 列且行限制为国家,且国家必须为英国和美国。

3. 敏感表/列单独管控
情况一:用户权限为可访问全数据库
此时用户能够访问到除敏感列(敏感列权限是独立单独管控的)之外的所有列,即 A 区域内的数据部分。

情况二:用户权限为可访问数据表
此时用户能够访问的数据权限与情况一一致,可以访问到除敏感列(敏感列权限是独立单独管控的)之外的所有列,即B区域内的数据部分。

情况三:用户权限为访问数据表权限+访问 Race(敏感列)权限
此时用户拥有访问数据表和访问敏感列的权限此时用户能够访问到完整的数据,即 C 区域内的数据部分。

4. 灵活的权限授权机制
授权机制主要分为两部分:数据资源和授权主体
数据资源可以将数据库表和行列的权限进行打包形成资源包,资源包可以通过授权账号进行权限的统一管理。
授权主体对象可以使个人、具体的部门、应用账号或是用户组。
个人授权:部门内的所有员工都拥有数据权限;应用账户:将账号进行授权从而对外提供数据服务;用户组:将个人或部门生成新的用户组,以用户组为单位统一管理此部分用户的数据权限。
数据资源与授权主体可以进行自定义组合形成灵活且互斥留痕的权限审批流,在此基础上可以通过智能风险判断辅助从而达成自动审批。
在自动审批流中可增加审批节点,增加的审批节点可以自定义附带触发审批的条件。
5. 智能审批
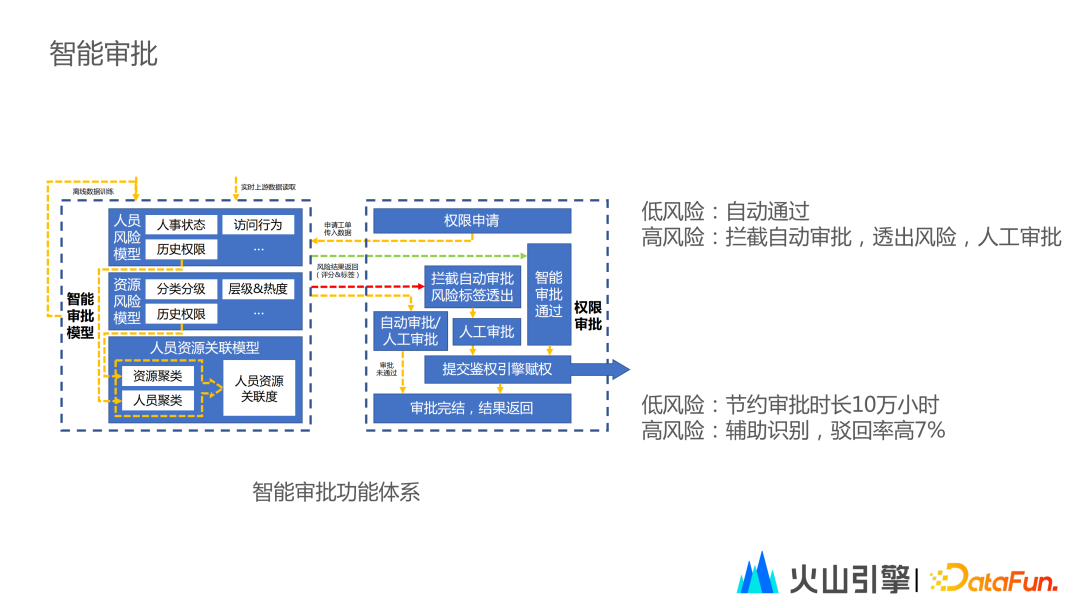
智能审批模型主要包括三个子模型,通过子模型综合识别判断所提交数据工单的风险。
人员风险模型
资源风险模型
人员资源关联模型
风险等级分为高中低三种,每一个风险等级都会产出相应的风险标签。低风险等级的工单会自动审批。高风险等级的工单会进行数据拦截流转至人工审批并输出数据风险标签。通过一年的打磨,智能审批模型取得了令人骄傲的成效。
低风险工单节省审批时长十万小时。
高风险工单的驳回率相较于其他人工审批工单高7%。
6. 冗余权限治理回收
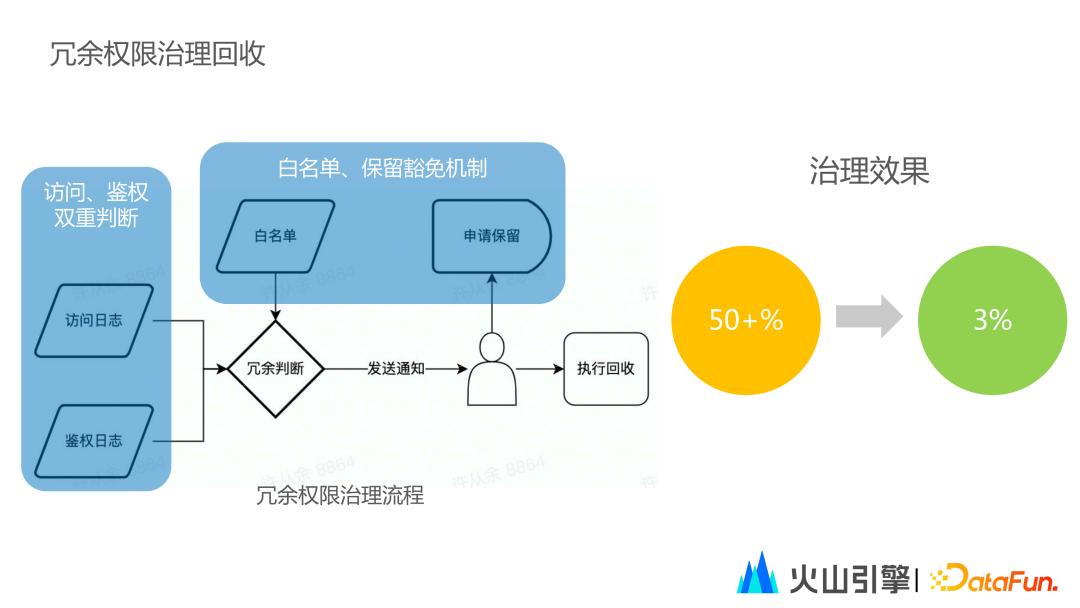
数据权限的使用应满足时间最小化原则
冗余权限的治理原则建立在数据权限时间最小化原则,数据权限的有效期取决于具体的业务周期。
冗余权限的判断
冗余权限的判断由访问日志和鉴权日志双重界定。双重界定的原因主要源于两种不同的使用场景。
第一种情况:系统为双鉴权机制,包括用户鉴权和账户鉴权,系统识别机制为账户权限,实际访问日志也为账户权限。此情况下需通过鉴权日志匹配出账户的权限。
第二种情况:豁免权限的开放使部分用户无需鉴权即可访问数据。此情况下只能通过访问日志来确定账户的权限。
白名单:白名单为账户和权限资源的组合,在白名单中的资源不会被判断为冗余且可长期保留。
03资产保护能力
1. 资产保护应用场景

资产保护场景贯穿数据从在线数据的落库到使用整个生命周期。
数据集成过程中会将数据进行静态脱敏或加密存储,而数据的实际使用中会通过按需加解密或脱敏的 API 网关的形式进行对外数据服务的提供。员工访问数据时会识别其是否有解密权限进行鉴权识别处理。
2. 加密方案介绍
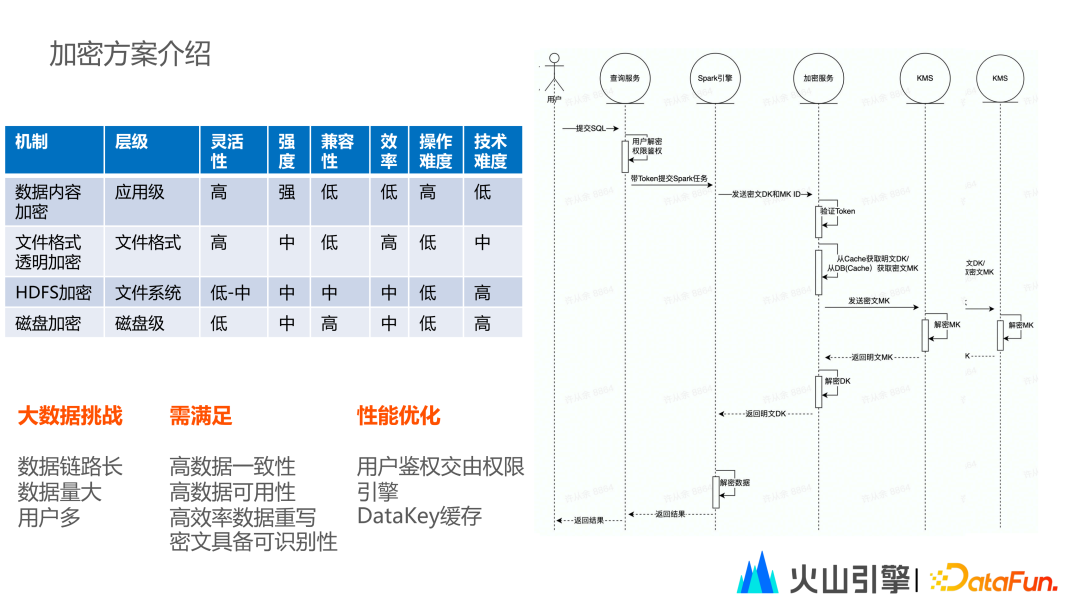
大数据平台加密方案主要分为四种:数据内容加密、文件格式透明加密、HDFS加密以及磁盘加密。
由于加密会使数据链路变变长数据量变大,同时使用数据的用户增多因此数据平台应满足高数据一致性,高数据可用性,高效率的数据重写以及密文需要具备可识别性。同样基于以上原因数据平台一般使用数据内容加密和文件格式加密两种方案。
04数据删除能力
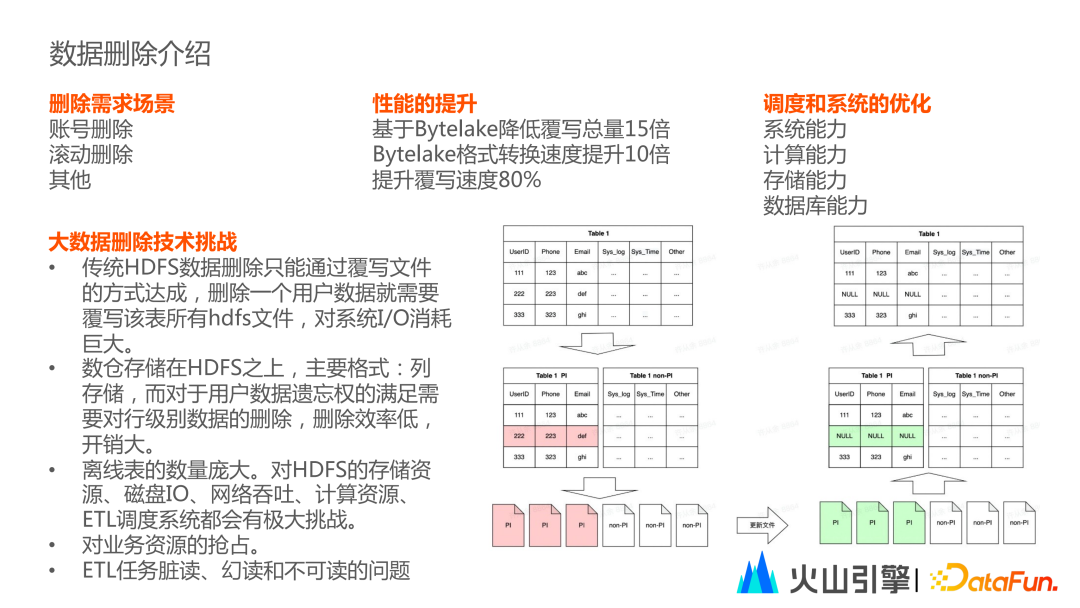
1. 数据删除应用场景
数据删除主要目的为响应隐私合规政策,需要在规定的时间期限内将用户某些个人信息删除。删除操作包括滚动删除和账户删除。一般情况下账户删除的触发方为用户主动删除,滚动删除会将数据分门别类进行时间期限的判断后进行删除操作。
2. 大数据删除技术面临的挑战
大数据删除相较于在线数据删除会面临以下几点挑战:
第一:传统 HDFS 数据删除采取覆写文件的方式,会对系统I/O消耗造成负担;
第二:HDFS 的存储方式为列存储,但用户数据是以行为单位,会造成数据删除效率较低;
第三:离线数据量较大,在海量数据中进行删除会对磁盘 IO、网络吞吐、计算资源和 ETL 任务调度造成极大的挑战;
第四:删除服务无法单独资源隔离,在资源使用高峰期时就会造成资源抢占的问题;
第五:由于删除服务需重写文件,当读取数据任务和删除任务同时被调度执行时会出现 ETL 任务脏读、幻读或不可读的问题。
3. 性能提升和调度系统的优化
针对以上挑战,对数据删除性能包括任务调度和系统上做了一定程度的优化。
性能提升:降低覆写总量。对 HDFS 进行改造自主研发 Bytelake,其原理为将数据存储格式拆分为用户数据和非用户数据的分部存储,那么在删除过程中只将用户数据进行删除即可,Bytelake 可将删除速度提升 15 倍。
调度系统能力:自研数据删除平台支持字节内部百万量级的数据任务的调度,解决了海量 ETL 任务的并发问题;支持错峰调度,大大降低了删除服务对线上任务造成的影响。
计算能力:利用调度能力强制使用 Spark 的微批处理模式,优化了 Join 算子的物理执行计划,节省了 Shuffle 的过程消耗,提升了 50%+ 的计算速度,缓解了磁 盘IO、网络吞吐的性能问题。
存储能力:提高 HDFS 的稳定性;通过删除场景自动捕捉存储瓶颈,提前扩增 HDFS NameNode 节点从而保证删除服务和业务的稳定运行。
数据库能力:推动了 ByteLake 支持 ACID 和 MVCC 特性,ACID 保障数据可见一致性,解决了脏读、幻读的问题,MVCC 保障了在读数据不丢失、可访问,解决了不可读问题。
以上介绍的大数据平台安全与权限管理是数据治理的重要组成部分,主要在字节跳动内部应用。
目前,字节跳动也将沉淀的数据治理经验,通过火山引擎大数据研发治理套件 DataLeap 对外提供服务。作为一站式数据中台套件,DataLeap 汇集了字节内部多年积累的数据集成、开发、运维、治理、资产、安全等全套数据中台建设的经验,助力 ToB 市场客户提升数据研发治理效率、降低管理成本,欢迎大家点击“阅读原文”来体验。
05问答环节
Q1:如何定义资源包,资源包会包含行列权限吗?
A1:资源包可以将特定的库表行列以及对应的读写权限打包成资源。资源包中会包含行列权限且会将其授权给用户。
Q2:如何计算治理前后权限冗余的提升比例?
A2:以单人来举例,一个用户在治理前拥有 100 个权限,其中 50 个长期不访问,那么他的权限冗余占比为50%,通过治理回收了长期不访问的 50 个权限中的 40 个,那么治理后的权限冗余占比为 10/60=16.67%。
Q3:冗余权限的回收是否会产生数据应用风险?
A3:答案是否定的。第一,正常情况下数据应用是经常性的,并且数据权限是全鉴权机制,若在用户数据同时出现在双日志中此部分数据权限不会被判定为冗余权限也不用影响到数据的应用。其次补充介绍一下权限回收除了冗余权限回收机制外,负责人可进行权限主动回收。在主动回收过程中会二次提醒,提醒内容为该权限目前应用在某些数据任务中以便负责人知晓。
原文: https://mp.weixin.qq.com/s/qzAS7vVn9YIbKcneOC1olA
如有侵权请联系删除