Faiss
业务流框架
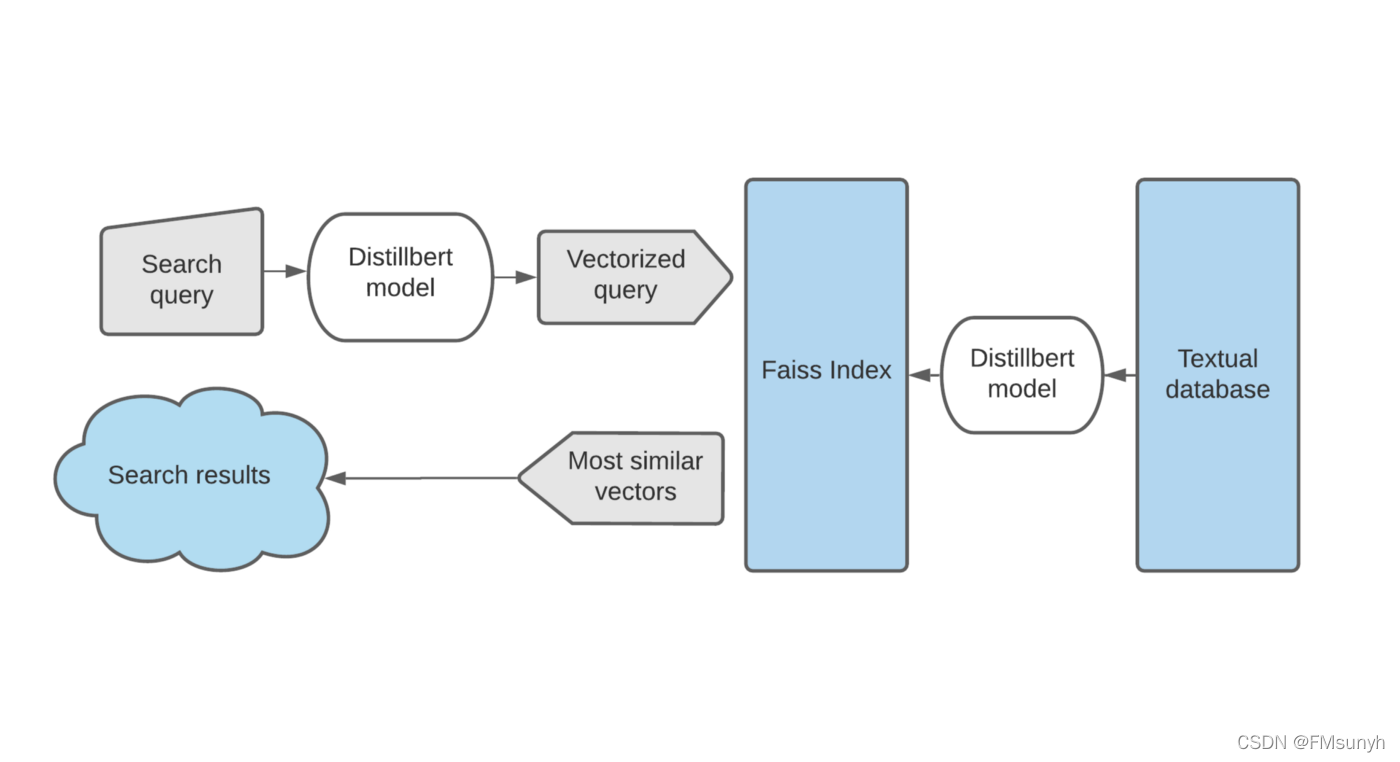
图来自Billion-scale semantic similarity search with FAISS+SBERT
代码结构
- 没有public和private,即成员可以直接访问
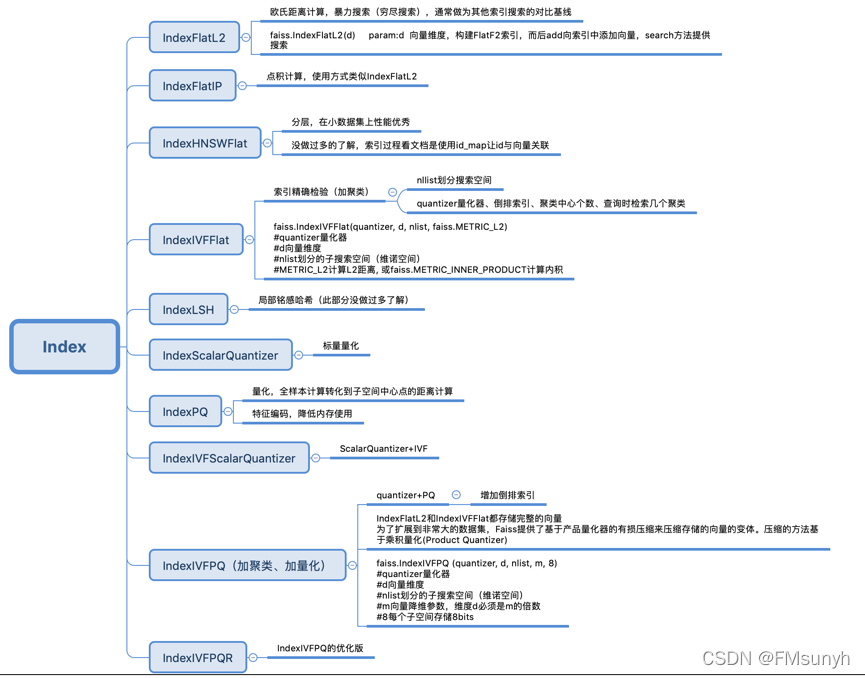
两个思考点
为了提高召回率,精度和速度,内存使用,有2个思考维度入手:
- 向量处理技术
- 索引技术( IVF, PQ, or HNSW)
先看向量处理技术
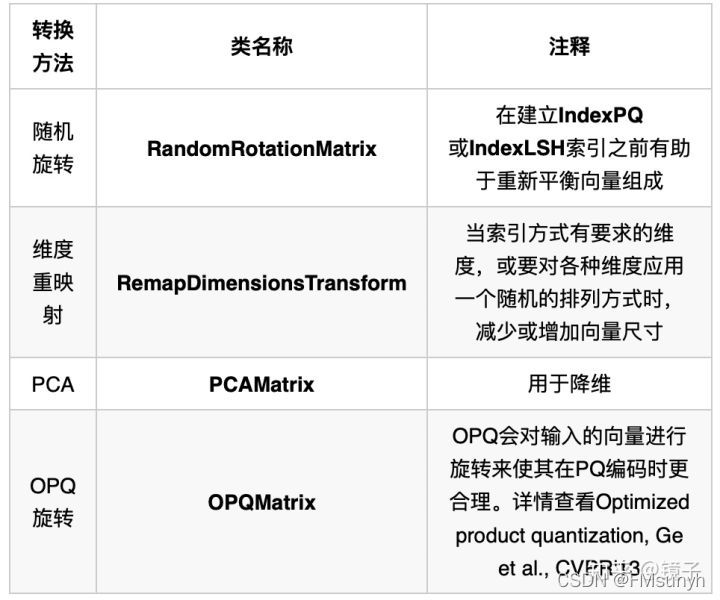
距离(度量标准)
PAC降维
PQ量化
Faiss中使用的乘积量化是Faiss的作者在2011年发表的论文,参考:《Product Quantization for Nearest Neighbor Search》
Index类型
倒排索引
Run on GPU
Tips
关于cosine距离:Faiss中的PQ目前还都是基于L2距离(欧式距离),并不支持cosine距离;
关于源代码阅读:可以从AutoTone.cpp这个文件开始阅读;
关于矩阵计算框架:Faiss外部依赖只有一个矩阵计算框架,这个框架可以用OpenBlas也可以用Intel的MKL,使用MKL编译的话性能会比OpenBlas稳定提升30%,在发布Faiss的时候MKL还是商用License,所以官方并没有直接使用,但是现在MKL已经免费了,所以建议使用MKL;
关于OpenMP:Faiss内部实现使用了大量的OpenMP来提高计算效率,其默认的向量检索也是batch,如果应用场景是单条向量查询,建议把环境变量OMP_NUM_THREADS设为1,避免使用OpenMP带来的多余性能开销,这样可以将单条查询的latency减少至原本的20%;
默认返回的结果是有可能重复的:要想保证结果不重复就在IndexPQ.cpp:927中MinSumK <float, SemiSortedArray, false>中把第三个参数改成true。