图像处理系列文章目录
前言
记录图像处理中效率优化的一些过程
一些参考链接:
https://blog.csdn.net/libaineu2004/article/details/104129127
https://blog.csdn.net/qq_27278957/article/details/84646948
一、遍历图像像素的方法比对
以遍历所有像素对图像进行反转为例
#include "ImageProcess.h"
void PrintCostTime(double& t1, double& t2)
{
double t = ((t2 - t1) / getTickFrequency()) * 1000;
cout << "time: " << t << endl;
}
void method_at(Mat& _src)
{
Mat src = _src.clone();
double t1 = getTickCount();
int w = src.cols;
int h = src.rows;
int dim = src.channels();
for (int row = 0; row < h; row++)
{
for (int col = 0; col < w; col++)
{
if (dim == 3) {
Vec3b bgr = src.at<Vec3b>(row, col);
bgr[0] = 255 - bgr[0];
bgr[1] = 255 - bgr[1];
bgr[2] = 255 - bgr[2];
src.at<Vec3b>(row, col) = bgr;
}
else if (dim == 1) {
float pixel = src.at<uchar>(row, col);
src.at<uchar>(row, col) =saturate_cast<uchar>(255 - pixel);
}
}
}
double t2 = getTickCount();
PrintCostTime(t1, t2);
imshow("result", src);
waitKey(0);
}
void method_Matptr(Mat& _src)
{
Mat src = _src.clone();
double t1 = getTickCount();
int w = src.cols;
int h = src.rows;
int dim = src.channels();
if (dim == 3) {
for (int row = 0; row < h; row++)
{
//uchar* pixel = src.ptr<uchar>(row);
Vec3b* pixel = src.ptr<cv::Vec3b>(row);
for (int col = 0; col < w; col++)
{
//pixel[0] = 255 - pixel[0];
//pixel[1] = 255 - pixel[1];
//pixel[2] = 255 - pixel[2];
//pixel += 3;
//Vec3b bgr = pixel[col];
pixel[col][0] = 255 - pixel[col][0];
pixel[col][1] = 255 - pixel[col][1];
pixel[col][2] = 255 - pixel[col][2];
}
}
}
else if (dim == 1) {
for (int row = 0; row < h; row++)
{
uchar* pixel = src.ptr<uchar>(row);
for (int col = 0; col < w; col++)
{
pixel[0] = 255 - pixel[0];
pixel ++;
//pixel[col] = 255 - pixel[col];
//*pixel++ = 255 - *pixel;
}
}
}
double t2 = getTickCount();
PrintCostTime(t1, t2);
imshow("result", src);
waitKey(0);
}
void method_Dataptr(Mat& _src)
{
Mat src = _src.clone();
double t1 = getTickCount();
int w = src.cols;
int h = src.rows;
int dim = src.channels();
if (dim == 3) {
for (int row = 0; row < h; row++)
{
uchar* pixel = src.data + row*src.step;
for (int col = 0; col < w; col++)
{
pixel[0] = 255 - pixel[0];
pixel[1] = 255 - pixel[1];
pixel[2] = 255 - pixel[2];
pixel += 3;
}
}
}
else if (dim == 1) {
for (int row = 0; row < h; row++)
{
uchar* pixel = src.data + row * src.step;
for (int col = 0; col < w; col++)
{
pixel[0] = 255 - pixel[0];
pixel++;
//pixel[col] = 255 - pixel[col];
//*pixel++ = 255 - *pixel;
}
}
}
double t2 = getTickCount();
PrintCostTime(t1, t2);
imshow("result", src);
waitKey(0);
}
void method_iterator(Mat& _src)
{
Mat src = _src.clone();
double t1 = getTickCount();
int w = src.cols;
int h = src.rows;
int dim = src.channels();
if (dim == 3) {
Mat_<Vec3b>::iterator it = src.begin<Vec3b>();
Mat_<Vec3b>::iterator itend = src.end<Vec3b>();
for (; it != itend; ++it)
{
(*it)[0] = 255 - (*it)[0];
(*it)[1] = 255 - (*it)[1];
(*it)[2] = 255 - (*it)[2];
}
}
if (dim == 1) {
Mat_<uchar>::iterator it = src.begin<uchar>();
Mat_<uchar>::iterator itend = src.end<uchar>();
for (; it != itend; ++it)
{
(*it) = 255 - (*it);
}
}
double t2 = getTickCount();
PrintCostTime(t1, t2);
imshow("result", src);
waitKey(0);
}
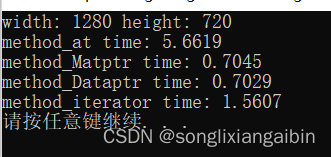
可以看到,使用指针的方法最快
二、使用OpenMP加速
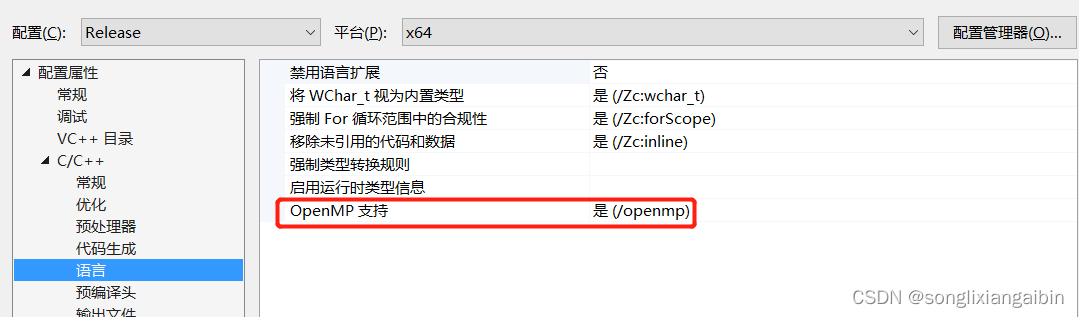
如果是Windows Visual Studio在属性里面设置开启openmp,如果是Linux的话, CMakeLists.txt加上配置:
find_package(OpenMP REQUIRED)
if (OPENMP_FOUND)
message("OPENMP FOUND")
set (CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
set (CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
set (CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
endif()
修改代码,在for循环处加上#pragma omp parallel for num_threads(4) 这一句
#include "ImageProcess.h"
void PrintCostTime(double& t1, double& t2)
{
double t = ((t2 - t1) / getTickFrequency()) * 1000;
cout << "time: " << t << endl;
}
void method_at(Mat& _src)
{
Mat src = _src.clone();
double t1 = getTickCount();
int w = src.cols;
int h = src.rows;
int dim = src.channels();
#pragma omp parallel for num_threads(4) //指定4个线程
for (int row = 0; row < h; row++)
{
for (int col = 0; col < w; col++)
{
if (dim == 3) {
Vec3b bgr = src.at<Vec3b>(row, col);
bgr[0] = 255 - bgr[0];
bgr[1] = 255 - bgr[1];
bgr[2] = 255 - bgr[2];
src.at<Vec3b>(row, col) = bgr;
}
else if (dim == 1) {
float pixel = src.at<uchar>(row, col);
src.at<uchar>(row, col) =saturate_cast<uchar>(255 - pixel);
}
}
}
double t2 = getTickCount();
cout << "method_at ";
PrintCostTime(t1, t2);
imshow("result", src);
waitKey(0);
}
void method_Matptr(Mat& _src)
{
Mat src = _src.clone();
double t1 = getTickCount();
int w = src.cols;
int h = src.rows;
int dim = src.channels();
if (dim == 3) {
#pragma omp parallel for num_threads(4) //指定4个线程
for (int row = 0; row < h; row++)
{
//uchar* pixel = src.ptr<uchar>(row);
Vec3b* pixel = src.ptr<cv::Vec3b>(row);
for (int col = 0; col < w; col++)
{
//pixel[0] = 255 - pixel[0];
//pixel[1] = 255 - pixel[1];
//pixel[2] = 255 - pixel[2];
//pixel += 3;
//Vec3b bgr = pixel[col];
pixel[col][0] = 255 - pixel[col][0];
pixel[col][1] = 255 - pixel[col][1];
pixel[col][2] = 255 - pixel[col][2];
}
}
}
else if (dim == 1) {
#pragma omp parallel for num_threads(4) //指定4个线程
for (int row = 0; row < h; row++)
{
uchar* pixel = src.ptr<uchar>(row);
for (int col = 0; col < w; col++)
{
pixel[0] = 255 - pixel[0];
pixel ++;
//pixel[col] = 255 - pixel[col];
//*pixel++ = 255 - *pixel;
}
}
}
double t2 = getTickCount();
cout << "method_Matptr ";
PrintCostTime(t1, t2);
imshow("result", src);
waitKey(0);
}
void method_Dataptr(Mat& _src)
{
Mat src = _src.clone();
double t1 = getTickCount();
int w = src.cols;
int h = src.rows;
int dim = src.channels();
if (dim == 3) {
#pragma omp parallel for num_threads(4) //指定4个线程
for (int row = 0; row < h; row++)
{
uchar* pixel = src.data + row*src.step;
for (int col = 0; col < w; col++)
{
pixel[0] = 255 - pixel[0];
pixel[1] = 255 - pixel[1];
pixel[2] = 255 - pixel[2];
pixel += 3;
}
}
}
else if (dim == 1) {
#pragma omp parallel for num_threads(4) //指定4个线程
for (int row = 0; row < h; row++)
{
uchar* pixel = src.data + row * src.step;
for (int col = 0; col < w; col++)
{
pixel[0] = 255 - pixel[0];
pixel++;
//pixel[col] = 255 - pixel[col];
//*pixel++ = 255 - *pixel;
}
}
}
double t2 = getTickCount();
cout << "method_Dataptr ";
PrintCostTime(t1, t2);
imshow("result", src);
waitKey(0);
}
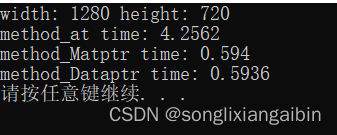
再次测试速度,可以看到速度变快了一点,是y因为for循环处耗时本身很短,如果换成自己的算法的话,速度还是可以提升非常多的,我自己的项目中优化后从700多ms到现在120ms提升效果非常nice。
总结
图像处理过程的简单记录