
01
背景
继OPPO大数据平台开源基于Spark诊断产品Compass(代号“罗盘”)之后,我们又持续迭代开发集成了实时Flink引擎诊断,可用于诊断Flink作业的资源使用情况以及异常问题。在资源诊断方面,Compass给出Flink作业的建议资源参数, 可以缩容或扩容,让作业达到合理的资源使用状态;在异常问题诊断方面,定位Flink作业的运行异常问题,给出改善建议。Compass Flink版本不仅集成DolphinScheduler调度器,即可诊断DolphinScheduler上运行的Flink实时作业,还可以用于可自定义诊断自动上报Flink作业。我们希望通过Compass回馈开源社区,也希望更多人参与进来,共同解决任务诊断的痛点和难题。
02
Compass Flink版本支持以下功能和特性:
非侵入式,即时诊断,无需修改已有的调度平台,即可体验诊断效果。
支持任意调度平台,例如 DolphinScheduler、自研平台等。
-
支持异常诊断和资源诊断,能够给出合理的资源配置建议值。
Compass Flink版已支持诊断类型概述:

03
技术架构
Compass主要由同步调度器任务元数据模块、同步Yarn/Spark/Flink元数据模块、关联调度器/引擎元数据模块、调度器任务异常检测模块,引擎层异常检测模块,Portal 展示模块组成。
▎3.1 整体架构图
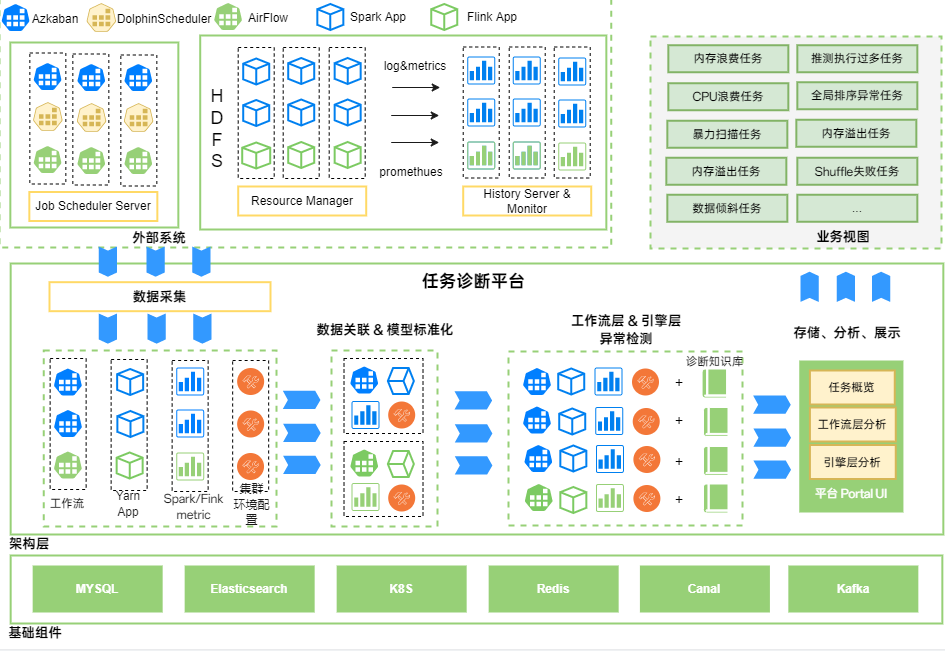
整体架构分 3 层:
-
第一层为对接外部系统,包括调度器、Yarn、HistoryServer、HDFS 等系统,同步元数据、集群状态、运行环境状态、监控指标、日志等到诊断系统分析; -
第二层为架构层,包括数据采集、元数据关联&模型标准化、异常检测、诊断 Portal 模块; 第三层为基础组件层,包括 MySQL、Elasticsearch、Kafka、Redis 等组件。
▎3.2 Flink作业诊断流程
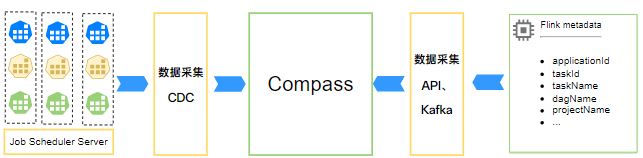
(1)元数据采集
采用CDC技术从调度器实时同步元数据到Compass系统,实时同步Flink Application元数据,另外用户也可通过系统接口或者Kafka消息队列渠道自主上报元数据到Compass系统;
功能介绍
▎4.1 作业列表
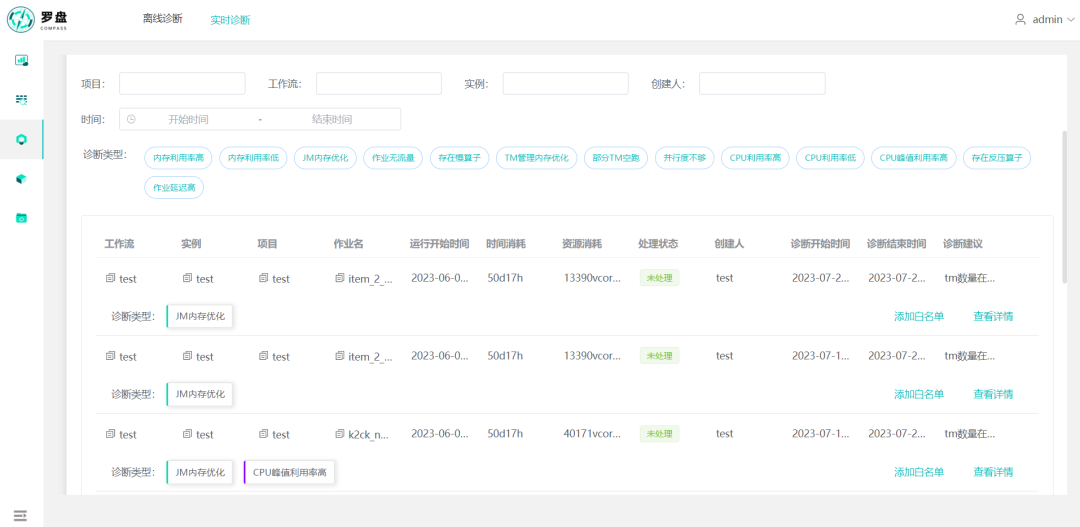
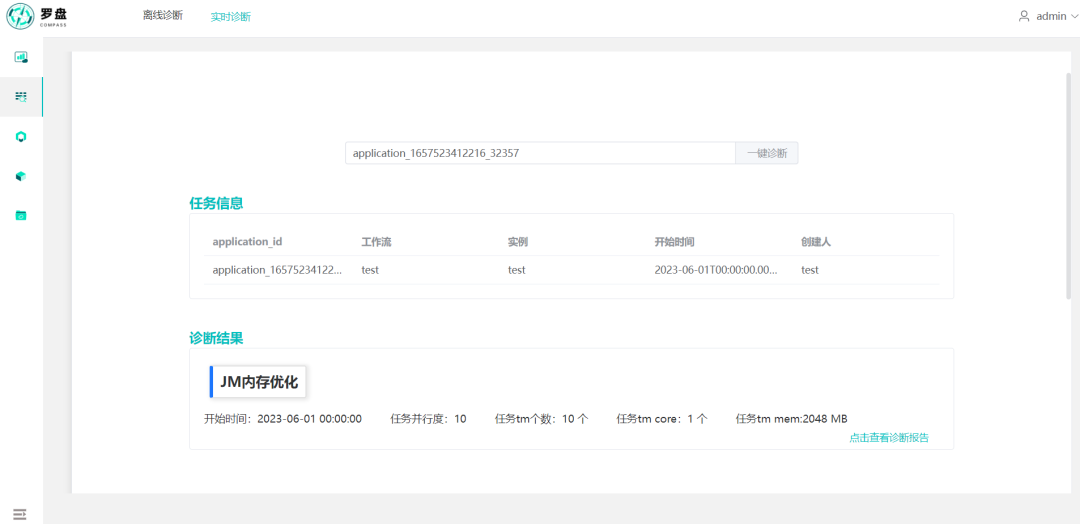
作业列表显示Flink作业诊断结果列表,记录包含作业的工作流、实例、项目名称、作业名、诊断类型等元数据,同时给出作业的诊断建议,作业可以根据建议进行改善,例如(TaskManager数量在100以内,降低JobManager内存到1024MB, 作业JobManager的内存变化:2048MB->1024MB);作业的诊断类型是多维度的,例如“JM内存优化“、“CPU利用率高”可同时存在,源于作业有多个诊断问题。点击“查看详情”可以跳转到作业的诊断报告。
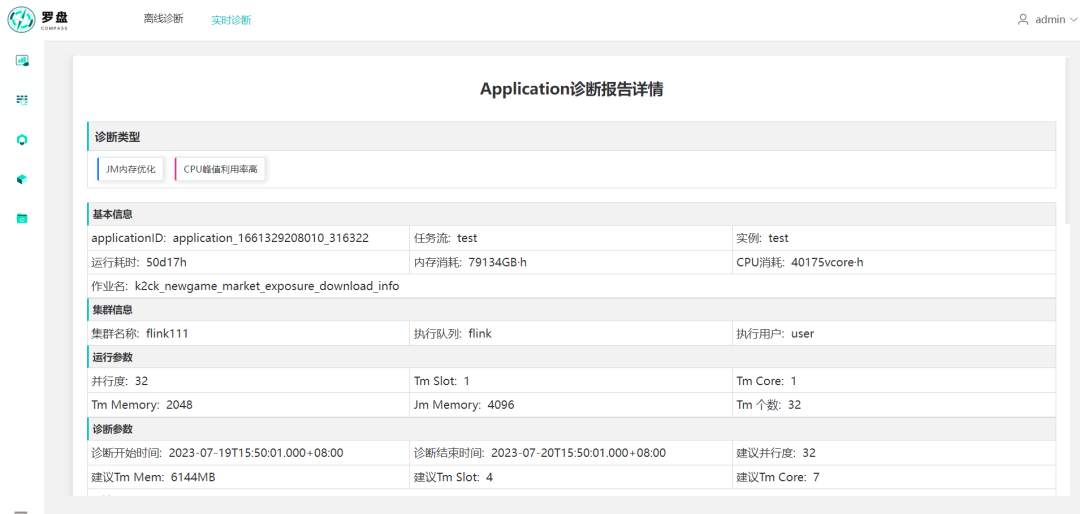
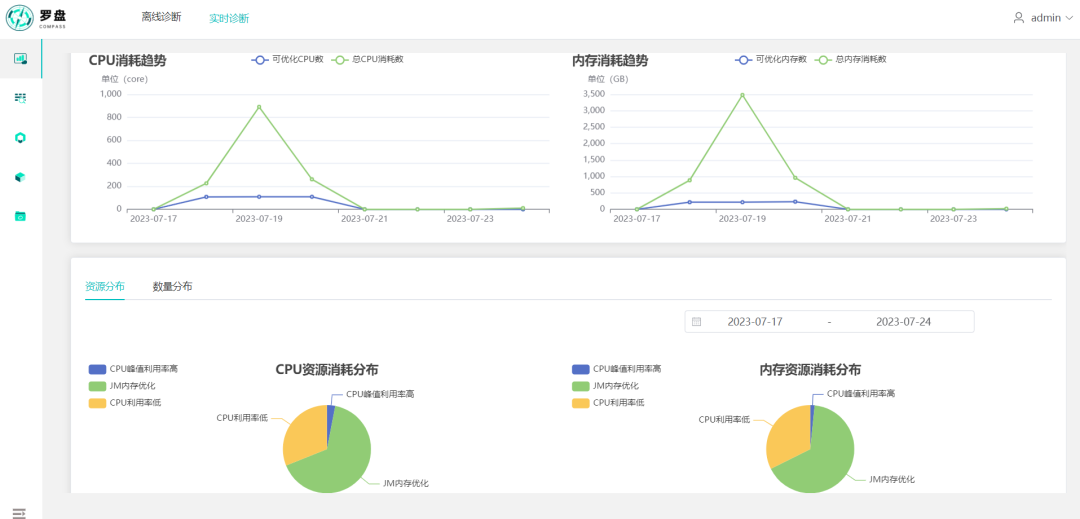
▎4.3 报告总览
▎4.5 白名单
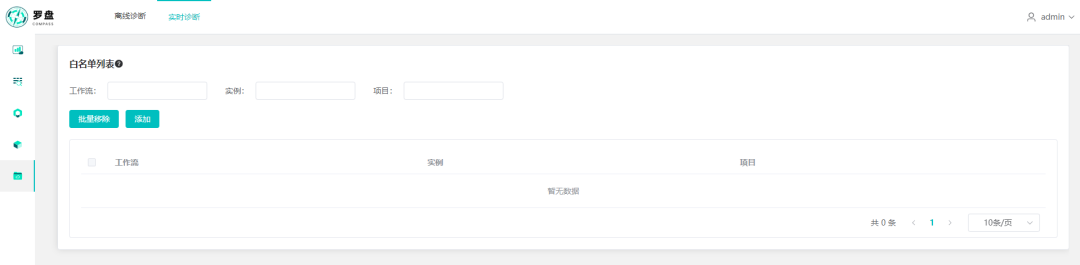
白名单功能可以根据作业的工作流,实例,项目,只要作业添加入白名单,作业将不进行诊断。
▎案例一:JM内存分析

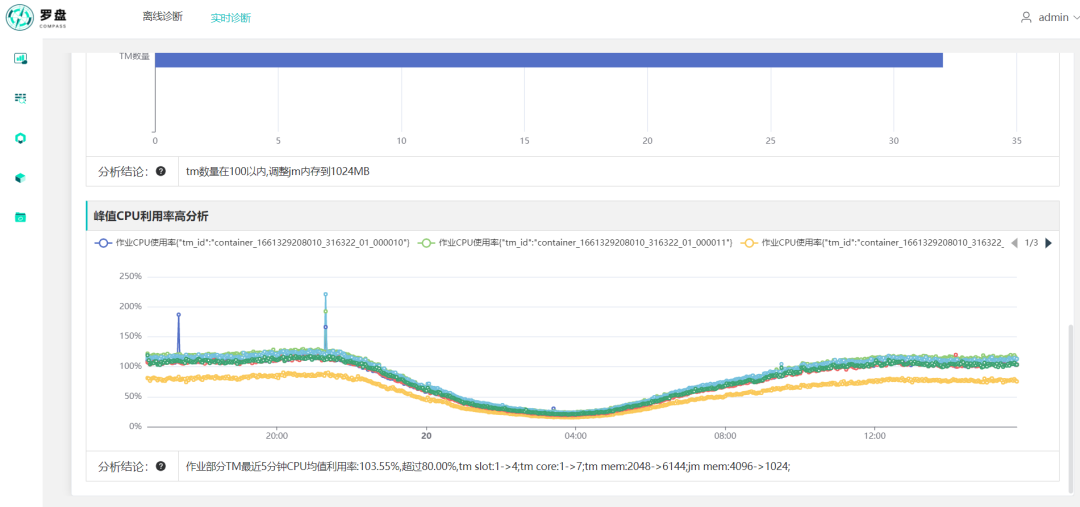
▎案例二:CPU峰值利用率
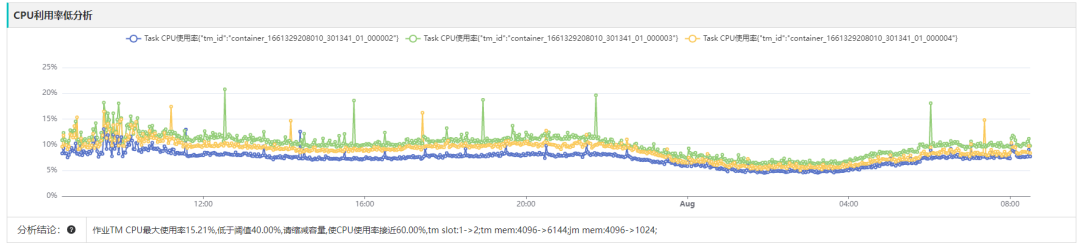
▎案例三:CPU利用率低
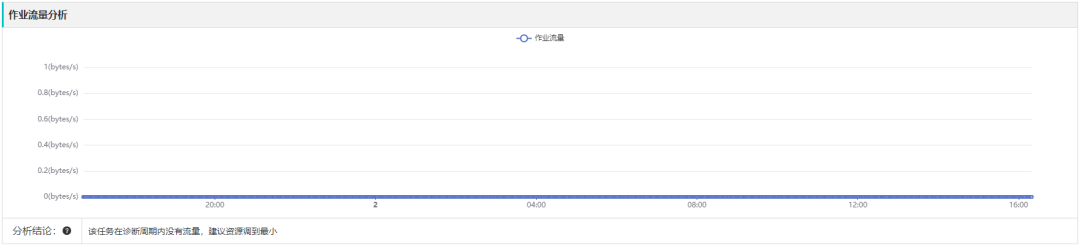
▎案例四:作业无流量
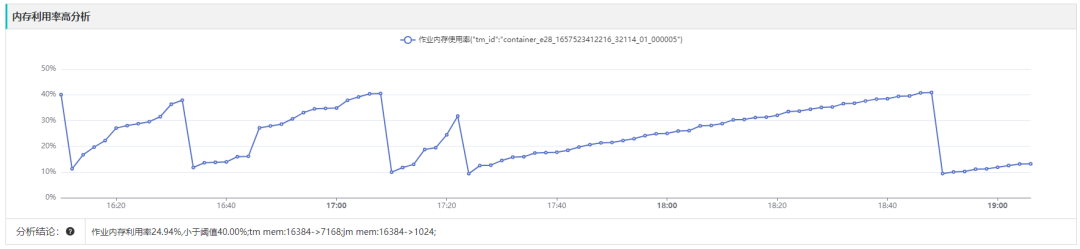
▎案例五:内存利用率低
【Github 地址】:https://github.com/cubefs/compass
欢迎参与贡献,如果您有需求或建议可以提 issue 到 Github,我们将及时为您解答。
Apache Committer,10年大数据相关方向开发经验,毕业于电子科技大学。
Bob Zhuang OPPO高级研发工程师
专注大数据分布式系统研发。
本文分享自微信公众号 - 安第斯智能云(OPPO_tech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。