这里有一张图像img_t
彩色图像可以看作一个矩阵,只是矩阵中的每一个点不是一个值,而是包含3个值的数组,这3个值就是RGB值
我们给它随机化为一个形状为 [3, 5, 5] 的三维张量img_t
img_t = torch.randn(3, 5, 5) # shape [channels, rows, columns]
RGB(Red, Green, Blue)图像是一种彩色图像表示方式,其中图像的颜色信息由红、绿、蓝三个颜色通道构成。每个像素点都由红色通道(R)、绿色通道(G)和蓝色通道(B)的亮度值组成,这三个通道的亮度值可以取从 0 到 255 的整数值。
在 RGB 图像中,通过调整不同通道的亮度值和组合方式,可以呈现出丰富的颜色和色彩变化。例如,纯红色的像素点在红色通道的亮度值最大(255),而绿色通道和蓝色通道的亮度值为 0,从而呈现出纯红色。

1.RGB转灰度:加权求和

我们希望将其转换为灰度图像,假设转换所需权重值:
weights = torch.tensor([0.2126, 0.7152, 0.0722])

这里包含了将 RGB 图像转换为灰度图像时使用的权重值,红色通道的权重为 0.2126,绿色通道的权重为 0.7152,蓝色通道的权重为 0.0722。在实际应用中,可以根据具体需求和应用场景进行调整。不同的权重值可能会产生不同的灰度图像效果,适用于不同的视觉感知或图像处理任务。
灰度图像是一种仅包含灰度信息的图像,每个像素只有一个亮度值。灰度图像可以看作是对彩色图像进行灰度化处理得到的结果。灰度值通常在 0 到 255 的范围内表示像素的亮度,其中 0 表示黑色(最暗),255 表示白色(最亮),中间的值表示不同灰度级别。在灰度图像中,每个像素只有一个通道,通常用于表示图像中的亮度、灰度或强度信息。相比于 RGB 图像,灰度图像更加简化,更适合于某些应用场景,例如图像处理算法的前处理步骤、黑白摄影等。
将 RGB 图像转换为灰度图像时,常常使用加权求和的方式
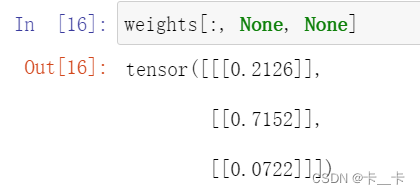
img_gray = torch.sum(img_t * weights[:, None, None], dim=0)
weights[:, None, None] 的操作是为了将 weights 张量的形状从 [3] 扩展为 [3, 1, 1],以便与 img_t 进行相乘

使用 torch.sum 函数在第 0 维度上对加权的张量进行求和,得到一个形状为 [5, 5] 的灰度图像张量 img_gray,其中每个像素的值是通过加权求和计算得到的

反之,从表示为具有高度和宽度维度的二维张量的灰度图像到添加第三个通道维度即可成为彩色图像(如RGB)。
例如,我们在batch_t中引入了一个额外的批处理维度
第一个维度 2 表示批量大小,表示批量中包含 2 张图像。
第二个维度 3 表示通道数,通常对应于彩色图像的 RGB 通道(红色、绿色、蓝色)。
第三个维度 5 表示每个图像的行数或高度。
第四个维度 5 表示每个图像的列数或宽度。
batch_t = torch.randn(2, 3, 5, 5) # shape [batch, channels, rows, columns]
2.另一种加权求和方式
有时RGB通道在0维,有时在1维,但它总是在-3维(从最后开始的第三维)
(1)未加权均值(默认平均)
这里会按平均权值的方式进行,例如下面这个简单的例子
结果=(R+G+B)/3
例如(0.1+0.2+0.7)/3=0.3333
(0.2+0.4+0.5)/3=0.3667
img_t = torch.tensor([ [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.6, 0.7, 0.8, 0.9, 1.0],
[0.2, 0.4, 0.6, 0.8, 1.0],
[0.3, 0.6, 0.9, 0.2, 0.5],
[0.7, 0.5, 0.3, 0.1, 0.9]],
[[0.2, 0.4, 0.6, 0.8, 1.0],
[0.3, 0.6, 0.9, 0.2, 0.5],
[0.7, 0.5, 0.3, 0.1, 0.9],
[0.4, 0.8, 0.2, 0.6, 0.4],
[0.9, 0.7, 0.5, 0.3, 0.1]],
[[0.7, 0.5, 0.3, 0.1, 0.9],
[0.4, 0.8, 0.2, 0.6, 0.4],
[0.9, 0.7, 0.5, 0.3, 0.1],
[0.2, 0.4, 0.6, 0.8, 1.0],
[0.3, 0.6, 0.9, 0.2, 0.5]]
])
img_gray_naive = img_t.mean(-3)
img_gray_naive
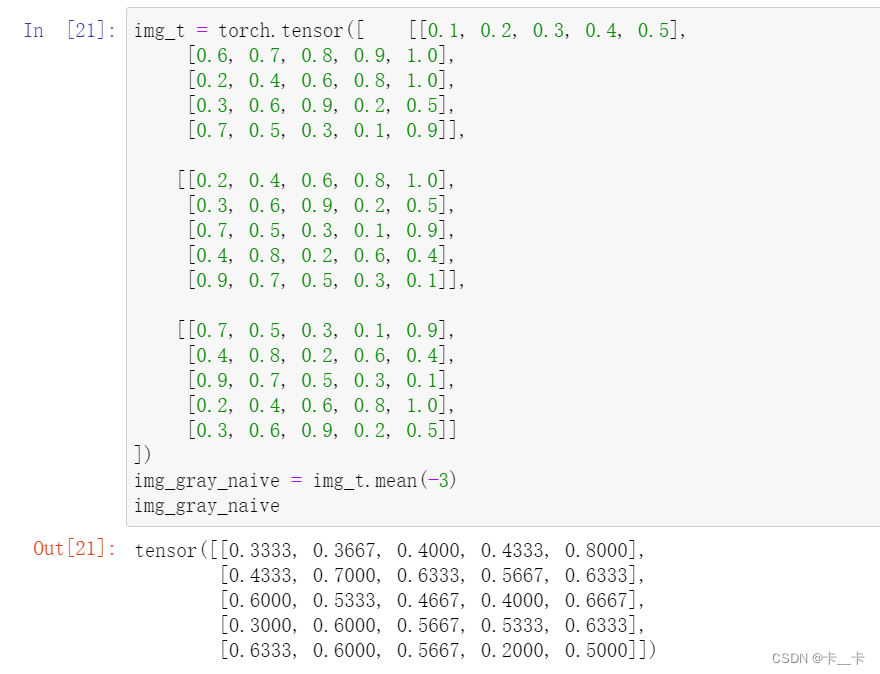
可以看出,我们得到了一个torch.Size([5, 5])的张量
下面的代码计算了在维度 -3 上的平均值,即 RGB 通道的平均值。结果是一个形状为 [5, 5] 的张量,表示转换后的灰度图像。
img_gray_naive = img_t.mean(-3)

对于 batch_t,我们得到一个形状为 [2, 5, 5] 的张量

(2)加权均值
我们先处理weights的维度,进行了两次 unsqueeze 操作,将其形状从 (3,) 扩展为 (3, 1, 1)。这样做是为了与形状为 (2, 3, 5, 5) 的 batch_t 张量进行乘法运算
unsqueezed_weights = weights.unsqueeze(-1).unsqueeze_(-1)
img_t 和 batch_t 分别与 unsqueezed_weights 进行逐元素相乘,得到 img_weights 和 batch_weights。这两个张量的形状都是 (2, 3, 5, 5)
img_weights = (img_t * unsqueezed_weights)
batch_weights = (batch_t * unsqueezed_weights)
此处相乘时自动进行了广播
例如下面的例子
img_t = torch.tensor([ [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.6, 0.7, 0.8, 0.9, 1.0],
[0.2, 0.4, 0.6, 0.8, 1.0],
[0.3, 0.6, 0.9, 0.2, 0.5],
[0.7, 0.5, 0.3, 0.1, 0.9]],
[[0.2, 0.4, 0.6, 0.8, 1.0],
[0.3, 0.6, 0.9, 0.2, 0.5],
[0.7, 0.5, 0.3, 0.1, 0.9],
[0.4, 0.8, 0.2, 0.6, 0.4],
[0.9, 0.7, 0.5, 0.3, 0.1]],
[[0.7, 0.5, 0.3, 0.1, 0.9],
[0.4, 0.8, 0.2, 0.6, 0.4],
[0.9, 0.7, 0.5, 0.3, 0.1],
[0.2, 0.4, 0.6, 0.8, 1.0],
[0.3, 0.6, 0.9, 0.2, 0.5]]
])
weights = torch.tensor([1,2,3])
unsqueezed_weights = weights.unsqueeze(-1).unsqueeze_(-1)
img_weights = (img_t * unsqueezed_weights)
img_weights

此处[3,1,1]自动广播为了[3,5,5],以便与img_t的[3,5,5]相乘,最终得到一个[3,5,5]的张量
注:三维张量的乘法规则要求后两维满足矩阵乘法规则
例如上面的weights不满足,必须使用unsqueeze增维

关于张量广播,要遵循以下规则
①如果两个张量的维度数不同,可以通过在维度较小的张量上添加尺寸为 1 的维度,使其维度数相同。
②如果两个张量在某个维度上的大小不同,但其中一个张量的大小为 1,则可以通过重复该维度来扩展其大小,使其与另一个张量的大小匹配。
③如果两个张量在某个维度上的大小既不相同也不为 1,则无法进行广播,此时会引发形状不匹配的错误。
例如
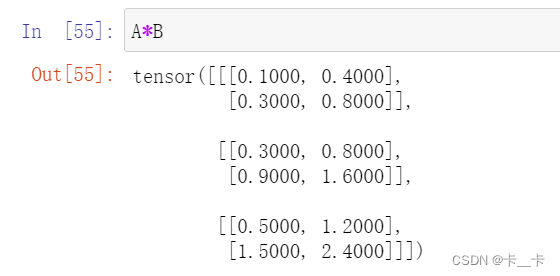
import torch
# 张量 A 形状为 (3, 1, 2)
A = torch.tensor([[[1, 2]],
[[3, 4]],
[[5, 6]]])
# 张量 B 形状为 (2, 2)
B = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
# 进行张量广播,使 A 和 B 形状相同
# A 形状扩展为 (3, 2, 2)
# B 形状扩展为 (3, 2, 2)
C = A * B
print(C)
A广播为

B广播为

相乘结果为
(3)求和
结果=R+G+B
我们通过在倒数第三个维度上求和来计算加权后的灰度图像,得到的形状分别是(5, 5)和(2,5,5)
img_gray_weighted = img_weights.sum(-3)
batch_gray_weighted = batch_weights.sum(-3)
例如
img_t = torch.tensor([ [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.6, 0.7, 0.8, 0.9, 1.0],
[0.2, 0.4, 0.6, 0.8, 1.0],
[0.3, 0.6, 0.9, 0.2, 0.5],
[0.7, 0.5, 0.3, 0.1, 0.9]],
[[0.2, 0.4, 0.6, 0.8, 1.0],
[0.3, 0.6, 0.9, 0.2, 0.5],
[0.7, 0.5, 0.3, 0.1, 0.9],
[0.4, 0.8, 0.2, 0.6, 0.4],
[0.9, 0.7, 0.5, 0.3, 0.1]],
[[0.7, 0.5, 0.3, 0.1, 0.9],
[0.4, 0.8, 0.2, 0.6, 0.4],
[0.9, 0.7, 0.5, 0.3, 0.1],
[0.2, 0.4, 0.6, 0.8, 1.0],
[0.3, 0.6, 0.9, 0.2, 0.5]]
])
weights = torch.tensor([1,2,3])
unsqueezed_weights = weights.unsqueeze(-1).unsqueeze_(-1)
img_weights = (img_t * unsqueezed_weights)
img_weights

img_gray_weighted = img_weights.sum(-3)
img_gray_weighted
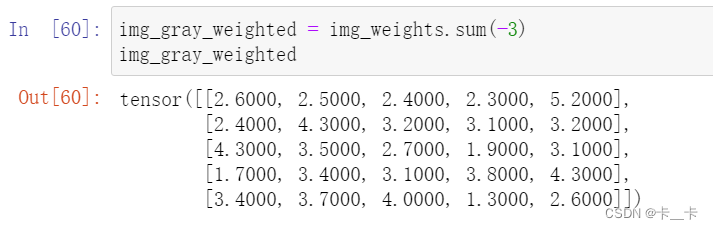
其中2.6=0.1+0.4+2.1
PyTorch 1.3添加了命名张量作为实验特性。
UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable.
I think you can ignore it for now and either install the nightly release or wait for the next stable release as the issue was tracked and fixed here.
Attention:Given the experimental nature of this feature at the time of writing, and to avoid mucking around with indexing and alignment, we will stick to unnamed in the remainder.
3.一种高效的方式——einsum函数
使用einsum函数和快速完成加权求和
img_gray_weighted_fancy = torch.einsum('...chw,c->...hw', img_t, weights) # c表示channels,h表示height,w表示weight

4.张量命名
张量工厂函数,如张量和rand,有一个名称参数。名称应该是一个字符串序列:
weights_named = torch.tensor([0.2126, 0.7152, 0.0722], names=['channels'])
weights_named

当我们已经有一个张量并想要添加名称(但不改变现有的名称)时,我们可以对其调用refine_names方法
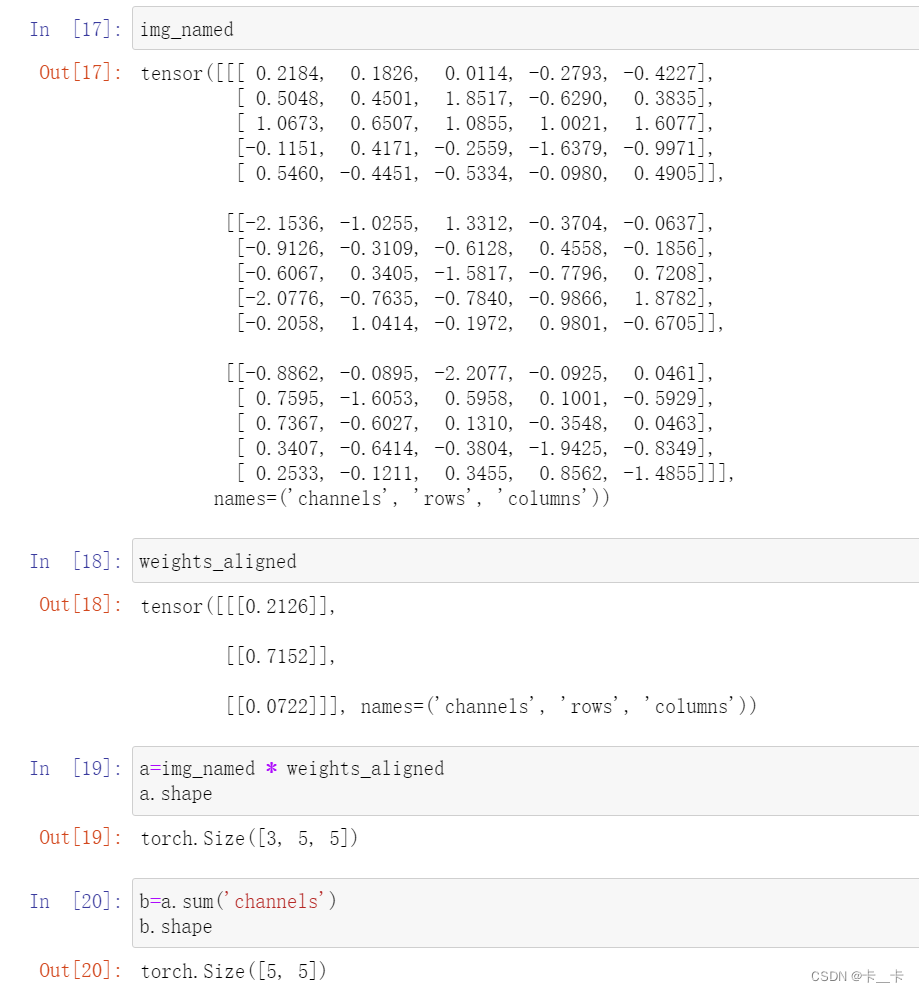
img_named = img_t.refine_names(..., 'channels', 'rows', 'columns') # 为倒数3个命名
batch_named = batch_t.refine_names(..., 'channels', 'rows', 'columns') # 省略号(…)允许省略任意数量的维度,未起名的默认为None


取消名字
a=batch_named.rename(None)
print(batch_named.names)
print(a.names)

5.显示对其维度
align_as方法返回一个张量,其中添加了缺失维数,并将现有维按正确顺序排列:
weights_aligned = weights_named.align_as(img_named)

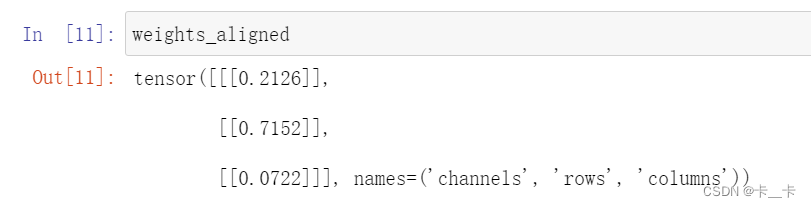
接受维度参数的函数,如sum,也接受命名维度
gray_named = (img_named * weights_aligned).sum('channels')

注意区分乘法和sum