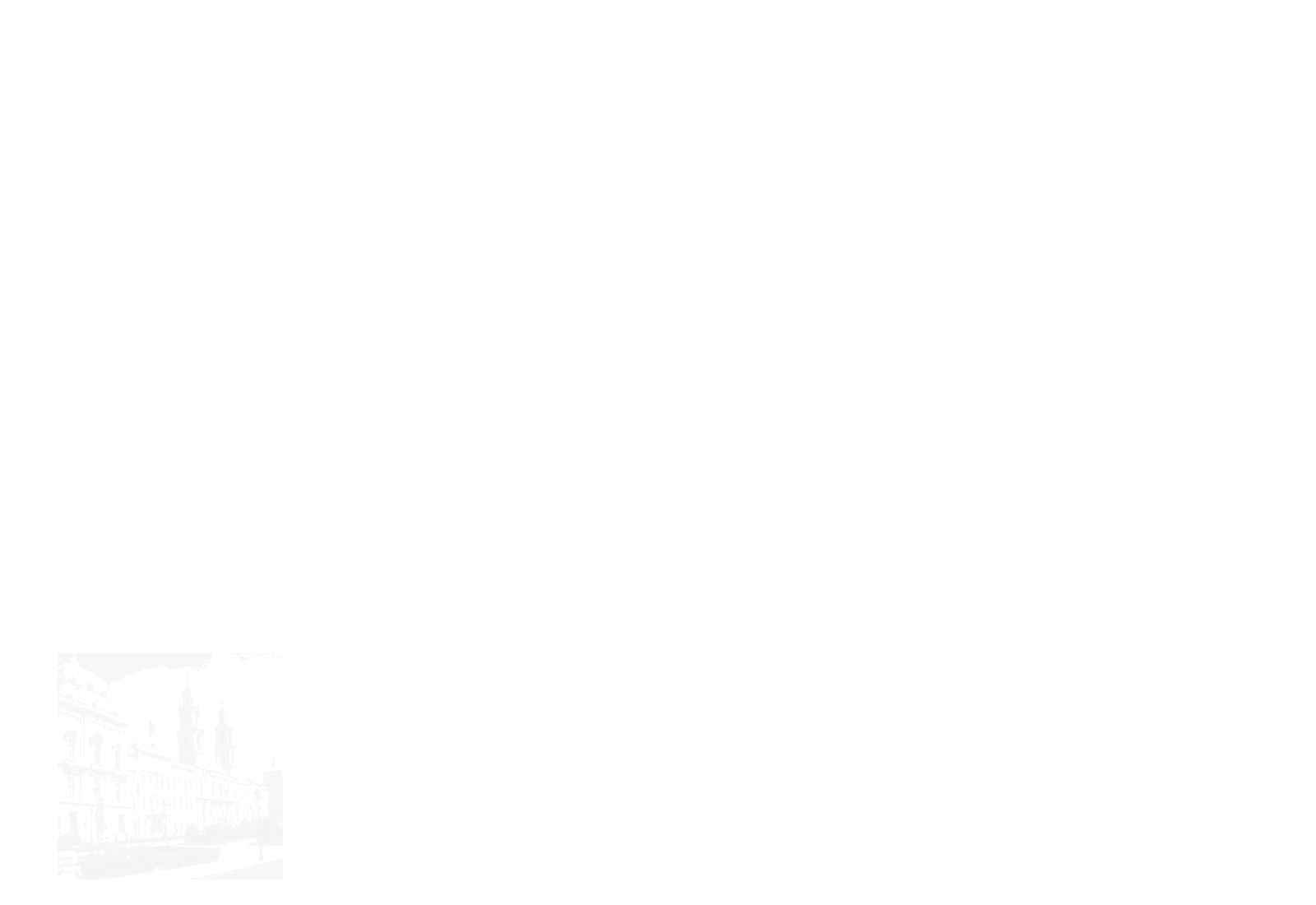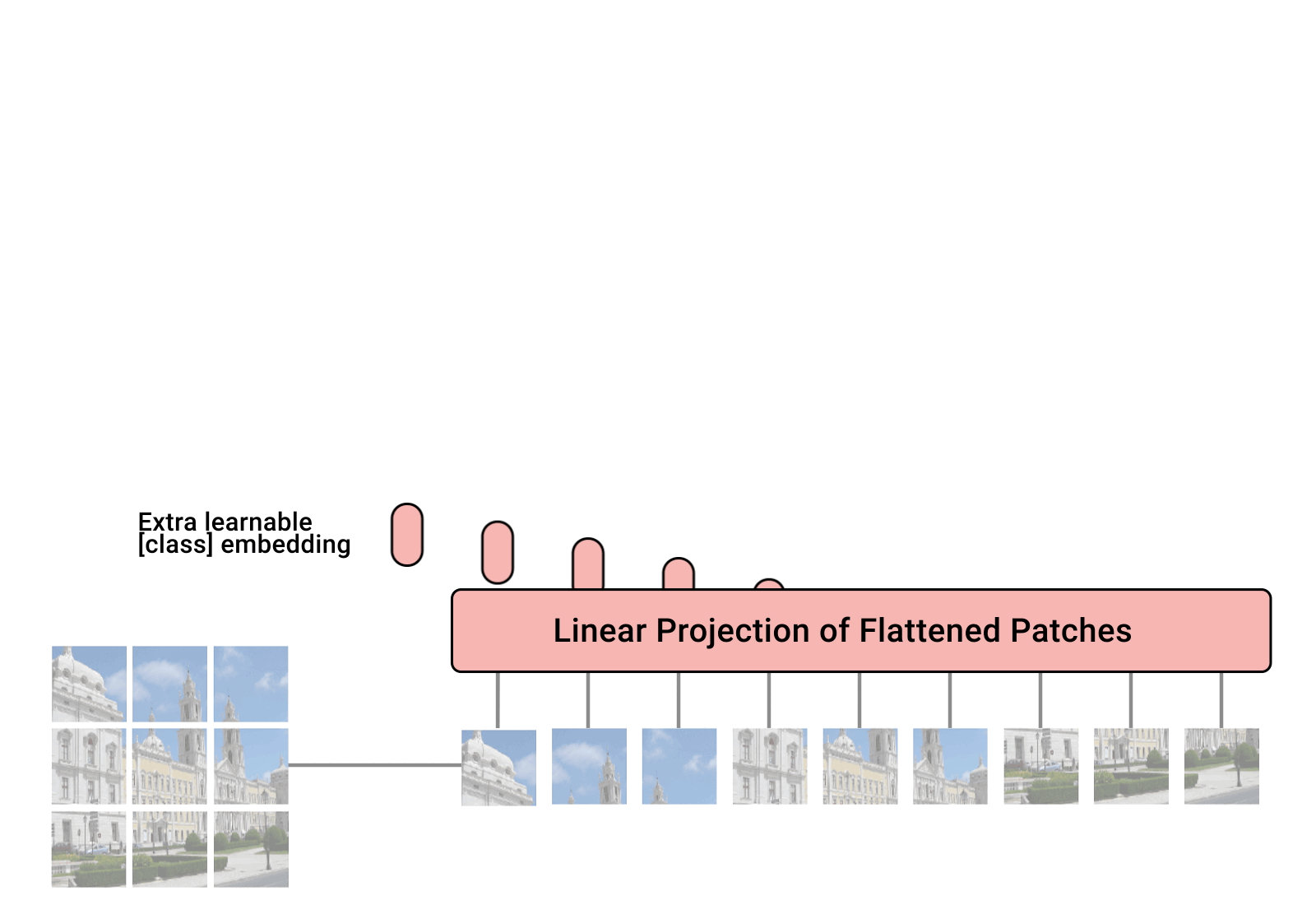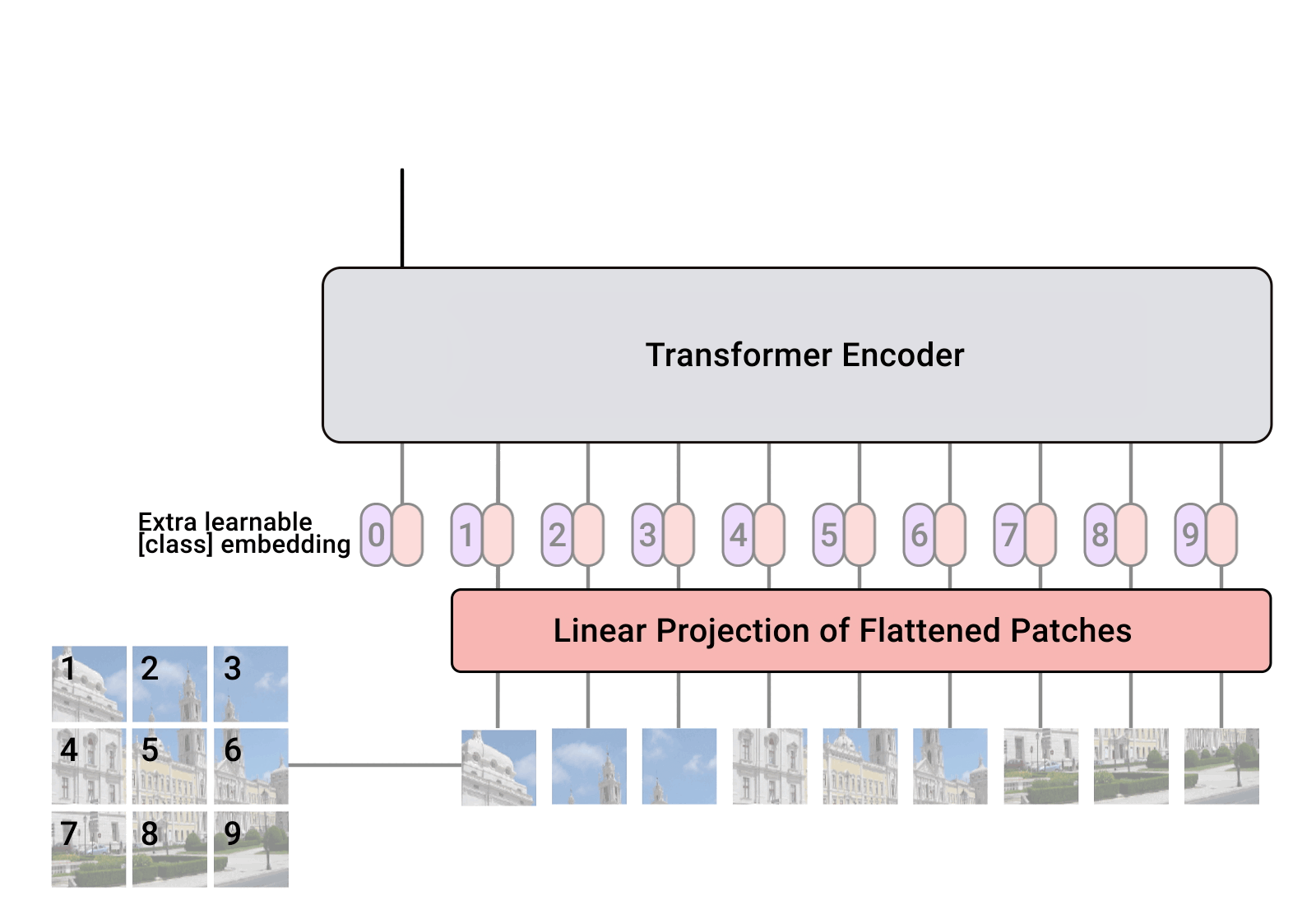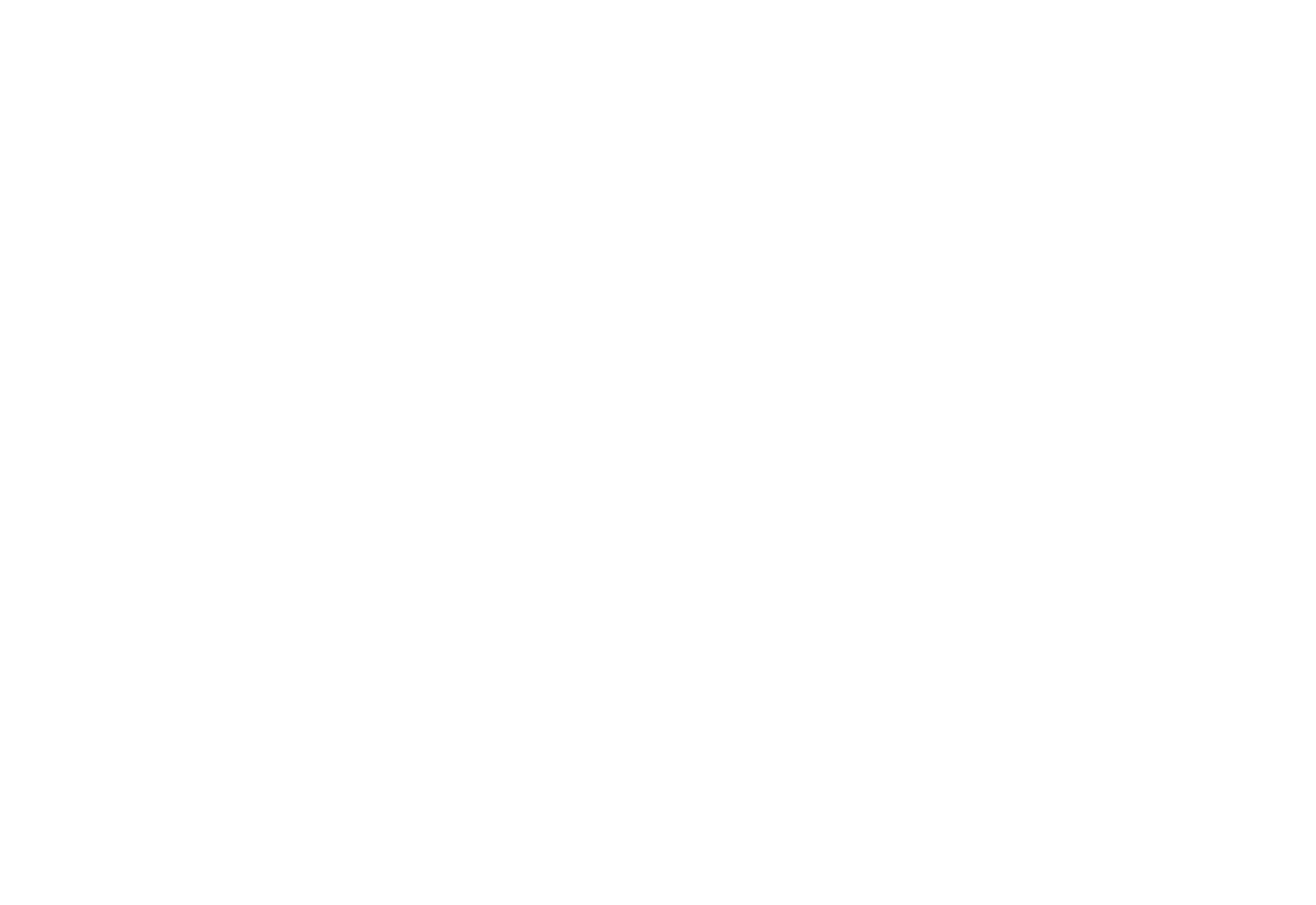2022 年,视觉变换器(ViT) 成为卷积神经网络(CNN) 的有力竞争对手,后者现已成为计算机视觉领域的最先进技术,并广泛应用于许多图像识别应用中。在计算效率和准确性方面,ViT 模型超过了当前最先进的 (CNN) 几乎四倍。
一、视觉转换器 (ViT) 如何工作?
视觉转换器模型的性能由优化器、网络深度和数据集特定的超参数等决策决定。CNN 比 ViT 更容易优化。纯 Transformer 和 CNN 前端之间的区别在于将 Transformer 与 CNN 前端结合起来。标准 ViT 词干采用 16*16 卷积,步幅为 16。相比之下,步长为 2 的 3*3 卷积提高了稳定性和精度。