ChatGPT 的表现令世人震惊。
但不少同学发现,自己在使用的时候并没有 “别人家” 的惊艳效果。
先别着急放弃,由于 ChatGPT 的表现性能与 prompt 有着很大的关系,
模型不达预期有可能是你给的 “提示” 不够明确。
最近,AI 大佬吴恩达联合 OpenAI 发布视频,手把手教你怎样如何写好 prompt,
这篇文章将对视频中的关键信息进行总结,如果你发现你的 LLM 不 work,希望这篇文章可以对你有所帮助。
一. 编写 Prompt 的原则
1.1 用特殊符号进行「区域划分」
我们应当尽量提供一个「明确」的指令,以帮助模型理解我们究竟想要模型输出一个怎样的答案。
明确(Clear)是指,我们需要让模型明白它应该对输入中的「哪一部分文本」进行「怎样的操作」
举例来讲:
text = """
近日,一份爆料圆明园五一假期门票售罄的微信聊天截图在朋友圈里疯传。
截图中说,圆明园门票被哄抢一空,“这是自1860年圆明园被毁以来圆明园门票第一次售罄。163年来第一次。”
南都记者查询得知,五一期间,圆明园实行限流政策,每日限流40000人,上下午各20000人。
登录圆明园官方预约号查询可知,4月29日至5月2日上午圆明园门票几乎全部售罄。
对于圆明园遗址公园来说,果真是百年难遇之盛况。
事实上,2023五一小长假,博物馆、美术馆已成热门打卡地,除了圆明园以外,
许多博物馆、美术馆和艺术机构也出现了一票难求的情况。
截至南都记者发稿,中国国家博物馆、北京故宫博物院、北京首都博物馆、雍和宫、恭王府等4月29日至5月3日的门票均已售罄。
中国国家博物馆工作人员告诉南都记者,自2023年3月以来,国博参观的预约名额几乎日日爆满,五一期间的预约更是火爆,
出票即“秒空”。
故宫博物院日前亦发布公告称,为提升广大观众的参观体验,缓解故宫午门外观众检票压力,维护参观秩序,
于2023年4月25日开始,将午门外东侧的“综合服务窗口”移至端门西侧“票务服务窗口”。
通过调整票务服务窗口位置,有利于疏导客流,为广大观众提供更安全、便利的票务服务和入院参观体验。
"""
prompt = f"""
将下面用三个反引号括起来的句子总结成一句话。
```{text}```
"""
上述例子中,我们在 prompt 中分成 2 个部分:
- 指令(Instruction):将下面用三个反引号括起来的句子总结成一句话。
- **处理内容(Content):**近日,一份爆料圆明园五一假期门票售罄的微信聊天截图在朋友圈里疯传…
多使用特殊的分隔符来标识任务需要处理的句子,能够让模型更清楚的知道自己需要处理的内容是什么。

在视频中一共推荐了 5 种特殊标记:
Triple quotes(三引号):"""
Triple backticks(三个反引号):```
Triple dashed(类似于 markdown 里的分割线):---
Angle brackets(尖括号):< >
XML tags(XML 中的特殊记号):<tag> </tag>
当然,在这个例子中,不用分隔符好像效果也不差:
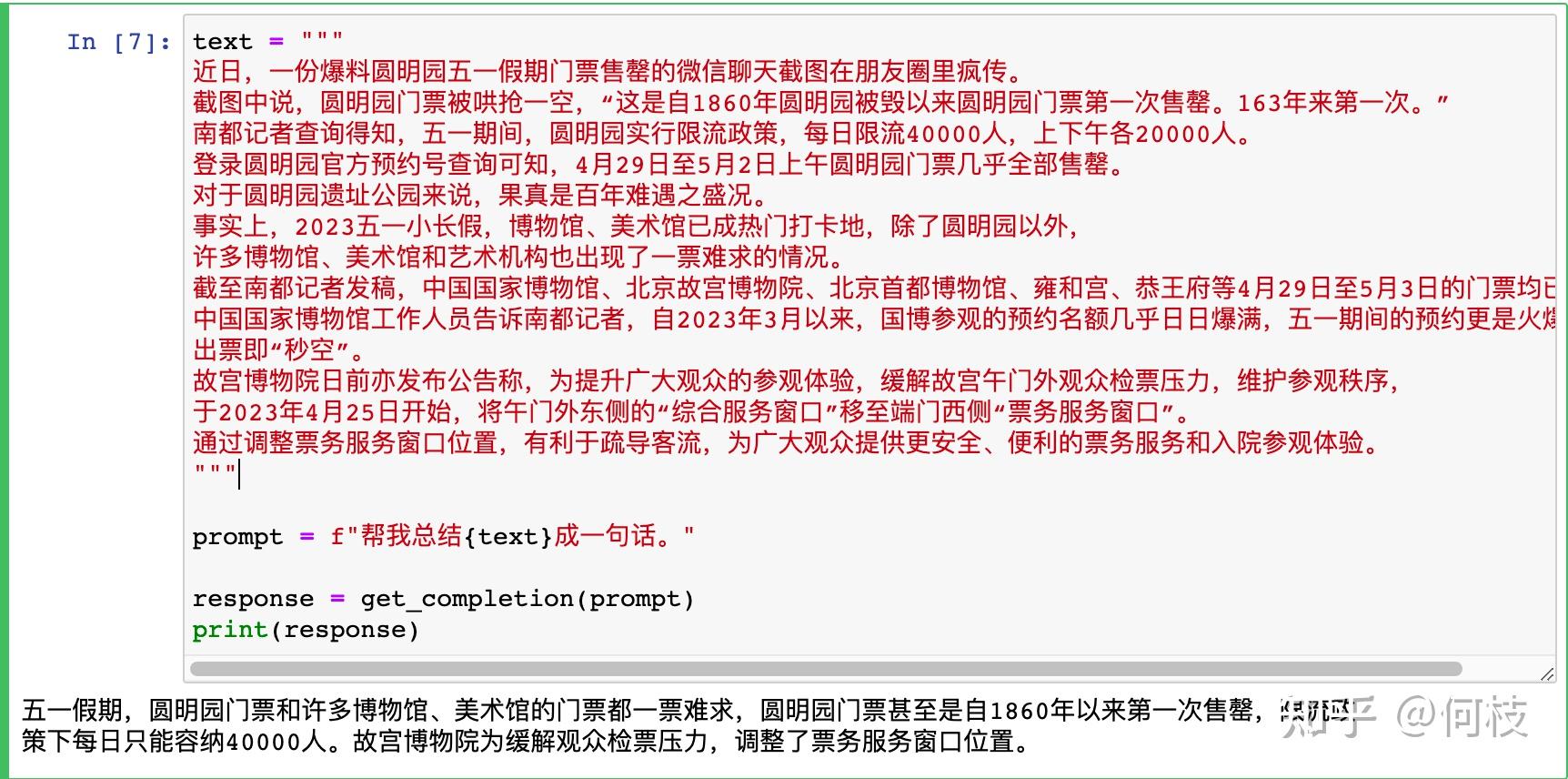
不过,这极大可能是因为摘要任务的 Instruction 并不复杂,
对于一些更难以理解的任务场景,能多使用明确的分隔符区分「指令」和「处理内容」对模型而言一定是有益的。
比如,当用户的指令与我们最初设定的指令相违背时,
如果不使用特殊符号对「用户输入」进行标识,模型可能会输出错误的结果:

如果限定了「用户输入」只存在于「特殊符号」内,模型则能避开用户的恶意请求:

1.2 明确模型的输出格式
为了便于解析,我们通常希望模型输出「结构化」的数据。
例如:
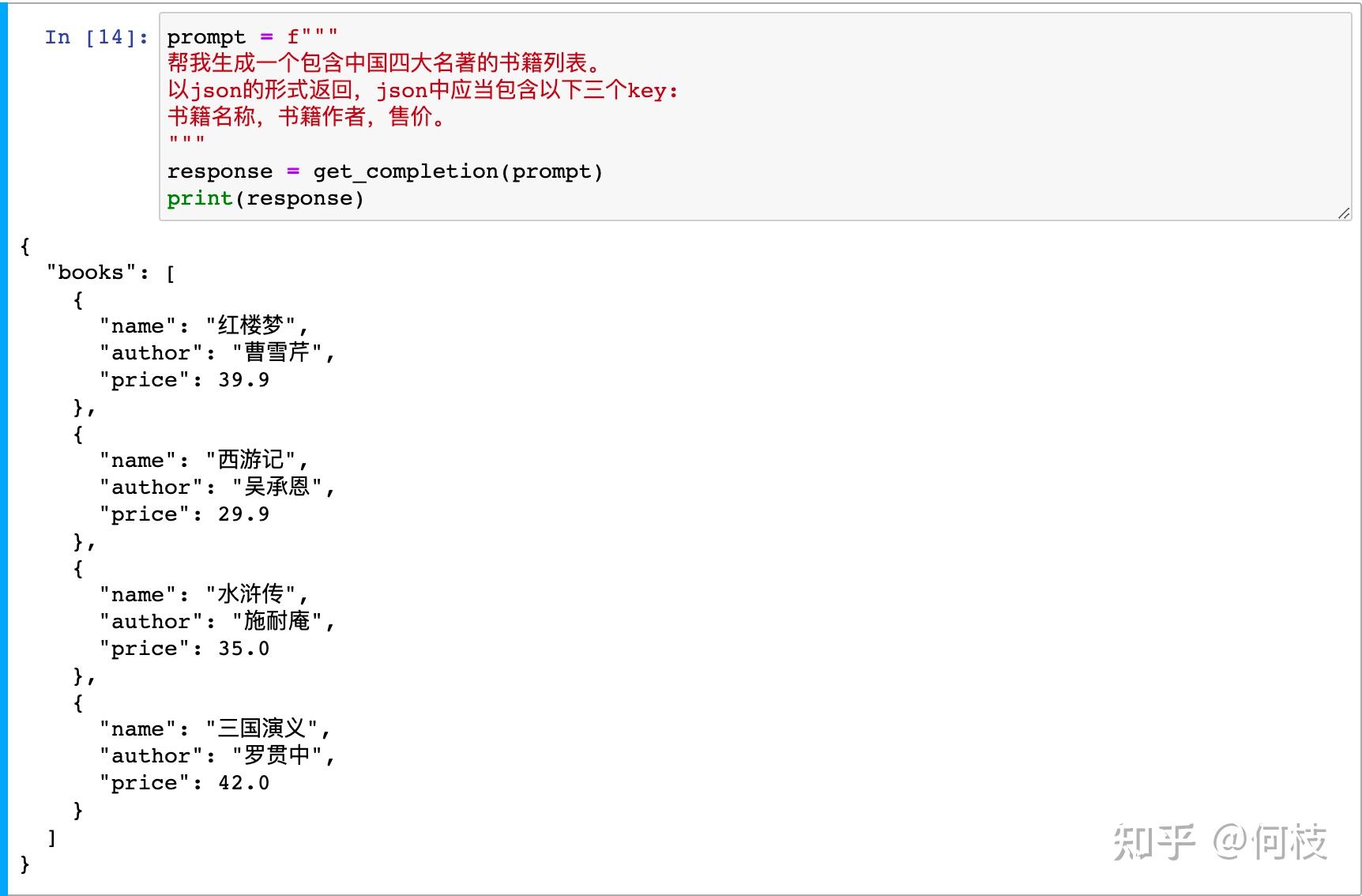
prompt = f"""
帮我生成一个包含中国四大名著的书籍列表。
以 json 的形式返回,json 中应当包含以下三个 key: 书籍名称,书籍作者,售价。
"""
response = get_completion(prompt)
print(response)
上述例子中,我们明确了模型需要输出的形式为 json,并且还要明确指定包含哪些 key:
1.3 设定检测条件
除了指定输出格式以外,我们还能进一步利用 ChatGPT 的强大理解能力,
我们可以设定一些条件,当句子满足我们的条件时我们才让模型输出我们想要的内容。
例如:
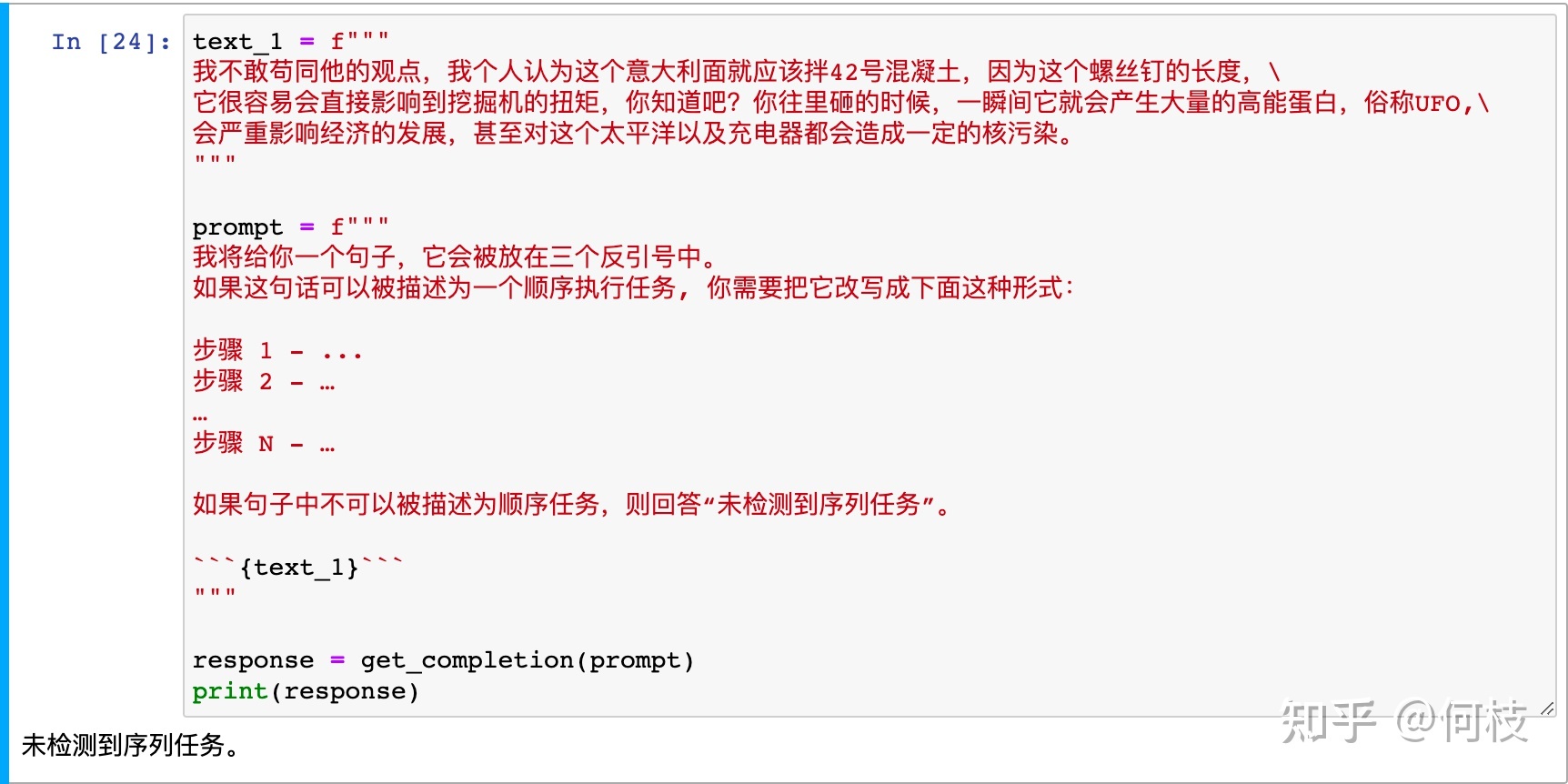
text_1 = f"""
泡一杯茶很容易!
首先,你需要把一些水烧开,拿起一个杯子,放一个茶包。
将开水倒在茶包上,让它静置一会儿,这样泡出来的茶能更入味。
几分钟后,取出茶包。你可以根据自己的口味加一些糖或牛奶调味。
完成以上步骤后,你就可以有一杯美味的茶可以享用啦。
"""
prompt = f"""
我将给你一个句子,它会被放在三个反引号中。
如果这句话可以被描述为一个顺序执行任务, 你需要把它改写成下面这种形式:
步骤 1 - ...
步骤 2 - …
…
步骤 N - …
如果句子中不可以被描述为顺序任务,则回答“未检测到序列任务”。
```{text_1}```
"""
response = get_completion(prompt)
print(response)
上述例子中,我们让 ChatGPT 帮我们去检测:句子中是否存在一个顺序序列的任务。
如果存在,则改写成我们指定的格式:

如果我们将句子换成一个不包含任务序列的句子,则会得到以下输出:
1.4 提供一些示例(Few Shot)
如果你是一个社恐,不善交际,你很难描述清楚你到底想要什么。
不要怕!
我们可以提供一些示例,从而帮助模型去揣测你想要什么样的输出。

上述例子中,我们告诉模型:要保持下面的语言风格进行回答。
这样相当于我们提供了一个例子,以供模型揣测用户的意图,并明确告诉模型要按照这个例子的风格进行续写。
1.5 思维链(CoT):给模型一点 「思考」的时间
当我们希望模型解决一个复杂任务的时候,我们不妨让它「一步一步」地来解决,
这样能够更大程度上提高模型输出正确答案的成功率。
例如:
text = f"""
在一个小村庄里,杰克和吉尔两兄弟正在山顶的水井里取水。
当他们高兴地唱歌爬上山顶时,不幸降临了。
杰克被一块石头绊倒,从山上滚落下来,而吉尔为了救弟弟,也不慎滑落。
索性他俩并没有收到很大的伤害,安全回到了家中。
尽管遭遇了不幸,但他们兄弟俩的冒险精神仍然没有减弱,第二天他们依旧踏上了愉快的探索之旅。
"""
prompt_1 = f"""
执行以下操作:
1 -> 用1句话总结下面由三个反括号括起来的文本。
2 -> 将摘要翻译成法语。
3 -> 在法语摘要中列出每个名字。
4 -> 输出一个json对象,该对象包含以下key:french_summary、num_names。
每一个操作的答案单独输出为一行。
```{text}```
"""
我们希望模型输出一个 json 文件,json 中要包含一个童话故事的「法文摘要」、童话故事中的「角色数量」。
那么,我们可以拆分成 4 个子任务:总结、翻译、列出每个角色名、结构化输出。
并且,我们将每一个子任务的输出结果都进行了打印,
这样,模型在做后一个任务的时候就可以参考前一个任务的输出结果,从而提升了输出的准确性。

当然,你还可以进一步的约束每一个 step 的输出格式,以便于后续的解析:

二. 通过迭代来编写 Prompt
和训练出一个好的模型一样,
要想写出一个好的 prompt 同样也需要不断迭代和调整。
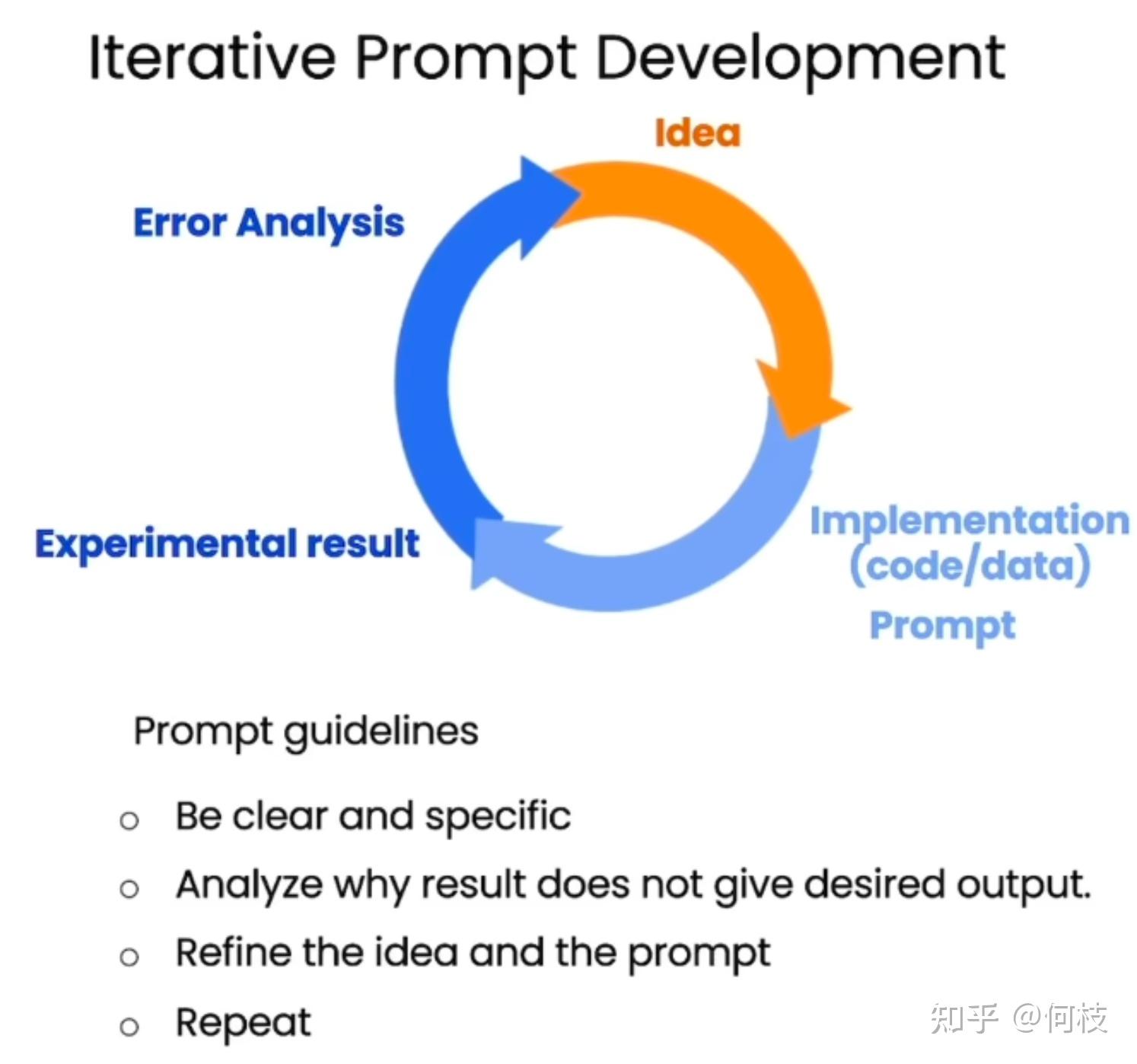
在这一个章节中,吴恩达亲自演示了如何根据模型的输出来添加 / 调整 prompt 指令。
这个章节主要在于展示如何对模型的输出进行一步一步的分析,
所以这个过程我就不再做总结了,感兴趣的同学可以直接看原视频:
https://learn.deeplearning.ai/chatgpt-prompt-eng/lesson/3/iterative
三. 摘要任务实战(Summarizing)
这一章节中我们将来具体讨论一下「摘要总结」这个任务。
我们先设定需要总结的文本,并编写相应的 prompt 指令:
prod_review = """
我给我女儿的生日买了这个熊猫毛绒玩具,她很喜欢这个玩具,走哪儿都带着它。\
这个熊猫非常柔软而且超级可爱,但是我觉得如果用同样的价格可能还有其他更多好的选择。 \
这个熊猫比预期提前了一天到达,所以在我把它给她之前,我自己玩了一下。
"""
prompt = f"""
你的任务是为淘宝用户生一个简短的摘要。
将下面用3个反括号括起来的内容总结成一句话,不能超过30个字。
```{prod_review}```
"""
在上面的示例中,我们设定:为「淘宝用户」生成一个短摘要。
我们可以看到生成结果如下,这很符合电商的标题:

如果我们将 prompt 进行修改:
prompt = f"""
你的任务是为物流部门生一个简短的摘要。
将下面用3个反括号括起来的内容总结成一句话,不能超过30个字。
```{prod_review}```
"""
仅仅只是修改了面向的用户群体(从淘宝用户 -> 物流部门),摘要总结的「重点」就发生了变化:

Amazing。
当然,你也可以具体去「指定」模型应该更关注文本中的「哪些方面」的信息:
prompt = f"""
你的任务是从文本中抽取关键信息用于给淘宝用户展示。
从下面用3个反括号括起来的内容中抽取出跟价格和物流相关的内容,不能超过30个字。
```{prod_review}```
"""
结果如下:

四. 推理任务实战(Inferring)
这一章我们将具体讨论「自然语言推理」任务,
我们将以「情感分类」、「信息抽取」和「话题分类」这 3 个任务作为例子。
同样,我们先设定文本,并写好对应的 prompt:
lamp_review = """
我的卧室需要一盏漂亮的灯,我希望这盏有额外的储物空间,而且价格不贵。
我很快就下单了,但是灯在运输过程中断了线。
卖家态度很好,很快送来了一个新的。
拼装过程中,我发现好像少了一个零件,所以我联系了卖家,他们很快就给我补发了缺失的部分!
在我看来,Lumina是一家关心客户的好公司!
"""
prompt = f"""
在下面用3个反括号括起来的句子中,表达了一种怎样的情感?
你只需要回答,“正向情感” 或是 “负向情感”。
```{lamp_review}```
"""
为了便于解析,我们要求模型只能输出给定选项里的答案:

现在,我们进一步的需要找出用户在这段话中表达出了哪些情绪:
prompt = f"""
找出在下面用 3 个反括号括起来的句子中,作者所表达的所有情绪。\
情绪不能超过 5 个,将你的答案格式化为用逗号分隔的列表形式。
```{lamp_review}```
"""
结果如下:

你甚至可以直接让 ChatGPT 帮你分析用户是否生气了(这对于卖家来讲至关重要):

如果我们今天想做的是信息抽取(Information Extraction)任务呢?
没关系!
只需要对 prompt 稍加调整即可:
prompt = f"""
从用户评论中找出以下信息:
- 用户所购买的商品
- 用户商品的生产公司
- 用户购买商品的时间
用户评论将放在下面,由3个反括号括起来。
你需要输出json格式,json中应当包含 “商品”,“生产公司”,“购买时间” 这3个key,\
如果评论中没有提到答案,则用 “无” 来填充值。
```{lamp_review}```
"""
结果如下:

只能说,6。
那如果今天你想做文本的「话题分类」任务呢?
遇事不决,就改 prompt:
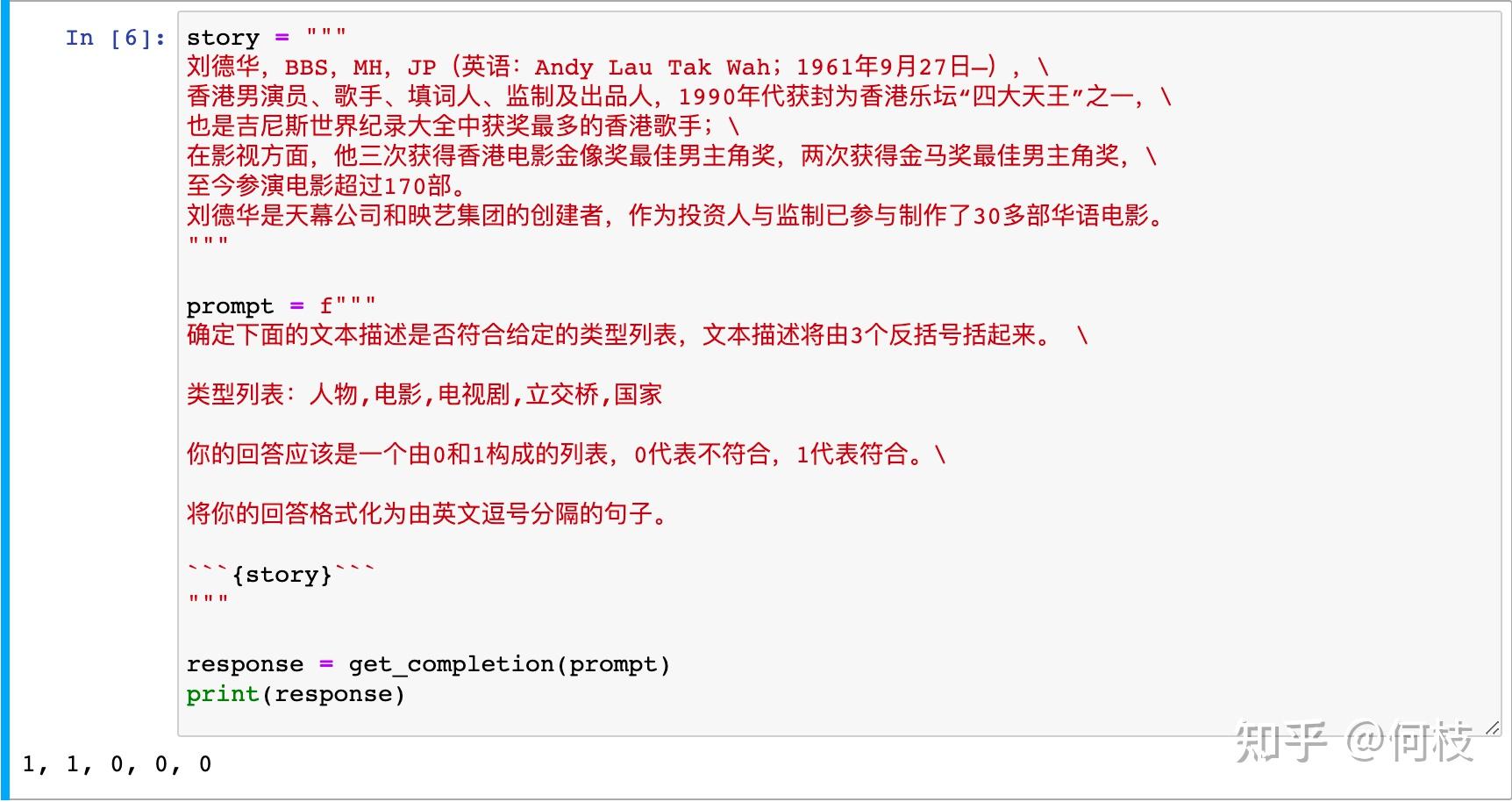
story = """
刘德华,BBS,MH,JP(英语:Andy Lau Tak Wah;1961年9月27日—),\
香港男演员、歌手、填词人、监制及出品人,1990年代获封为香港乐坛“四大天王”之一,\
也是吉尼斯世界纪录大全中获奖最多的香港歌手;\
在影视方面,他三次获得香港电影金像奖最佳男主角奖,两次获得金马奖最佳男主角奖,\
至今参演电影超过170部。
刘德华是天幕公司和映艺集团的创建者,作为投资人与监制已参与制作了30多部华语电影。
"""
prompt = f"""
确定下面的文本描述是否符合给定的类型列表,文本描述将由3个反括号括起来。 \
类型列表:人物,电影,电视剧,立交桥,国家
你的回答应该是一个由0和1构成的列表,0代表不符合,1代表符合。\
将你的回答格式化为由英文逗号分隔的句子。
```{story}```
"""
由于一个句子可能会对应多个类型,
因此,我们让模型对每一个类型都进行一次单独的判断(类似于多标签分类任务)。
不出意外,ChatGPT 依旧是这么的优雅:
五. 转换(翻译)任务实战(Transforming)
这一章中,我们将主要讨论文本转换任务,
包括但不局限于:翻译。
先来看翻译任务,生成多个多语言的句子和 prompt:
user_messages = [
"La performance du système est plus lente que d'habitude.", # System performance is slower than normal
"Mi monitor tiene píxeles que no se iluminan.", # My monitor has pixels that are not lighting
"Il mio mouse non funziona", # My mouse is not working
"Mój klawisz Ctrl jest zepsuty", # My keyboard has a broken control key
"我的屏幕在闪烁" # My screen is flashing
]
for issue in user_messages:
prompt = f"告诉我这是什么语言: ```{issue}```"
lang = get_completion(prompt)
print(f"原始文本 ({lang}): {issue}")
prompt = f"""
把下面这句话翻译成中文和韩语: ```{issue}```
"""
response = get_completion(prompt)
print(response, "\n")
得到每个句子的输出:

仅仅是翻译的话,这不够 Crazy。
我们尝试让模型帮我们做下面这个任务:
data_json = { "何枝工作室" :[
{"姓名":"何枝", "性别":"男", "简介": "爱好世界和平。"},
{"姓名":"何小枝", "性别":"男", "简介": "何枝的助手,迷你版的何枝。"},
{"姓名":"何大枝", "性别":"男", "简介": "何枝的助手,放大版的何枝。"}
]}
prompt = f"""
将下面的python字典从json转成一个html表格,表格的标题和json中的键名保持一致: {data_json}
"""
我们让模型根据我们输出的 json,生成一个 HTML 的表格:
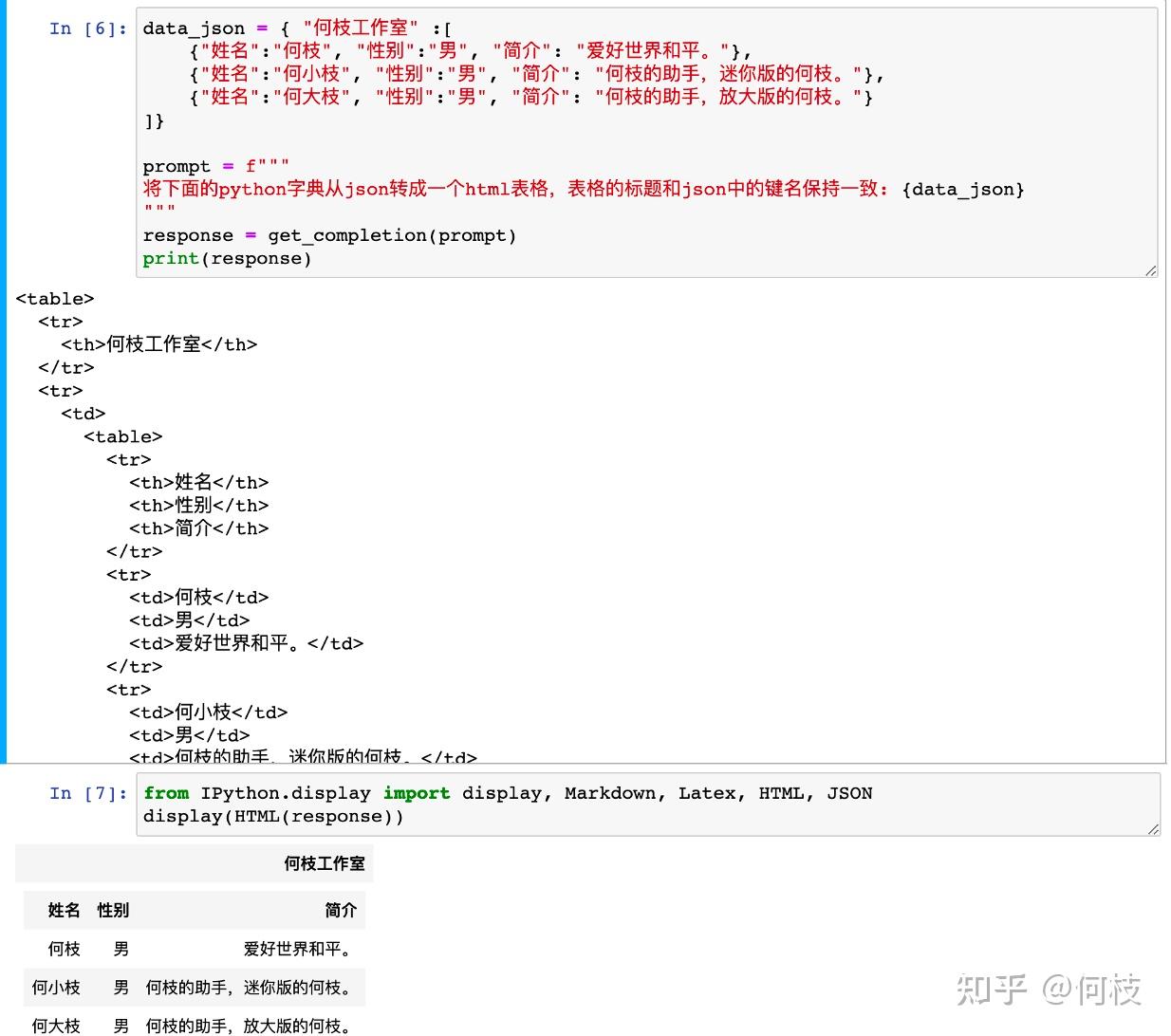
很好,这才是我映像中的 LLM。
五. 文本生成任务实战(Expanding)
这一章中,我们将通过一个「AI 客服」的案例来讲解文本生成。
我们需要让「AI 客服」根据「用户评论」和「用户情绪」来进行针对性的回复:
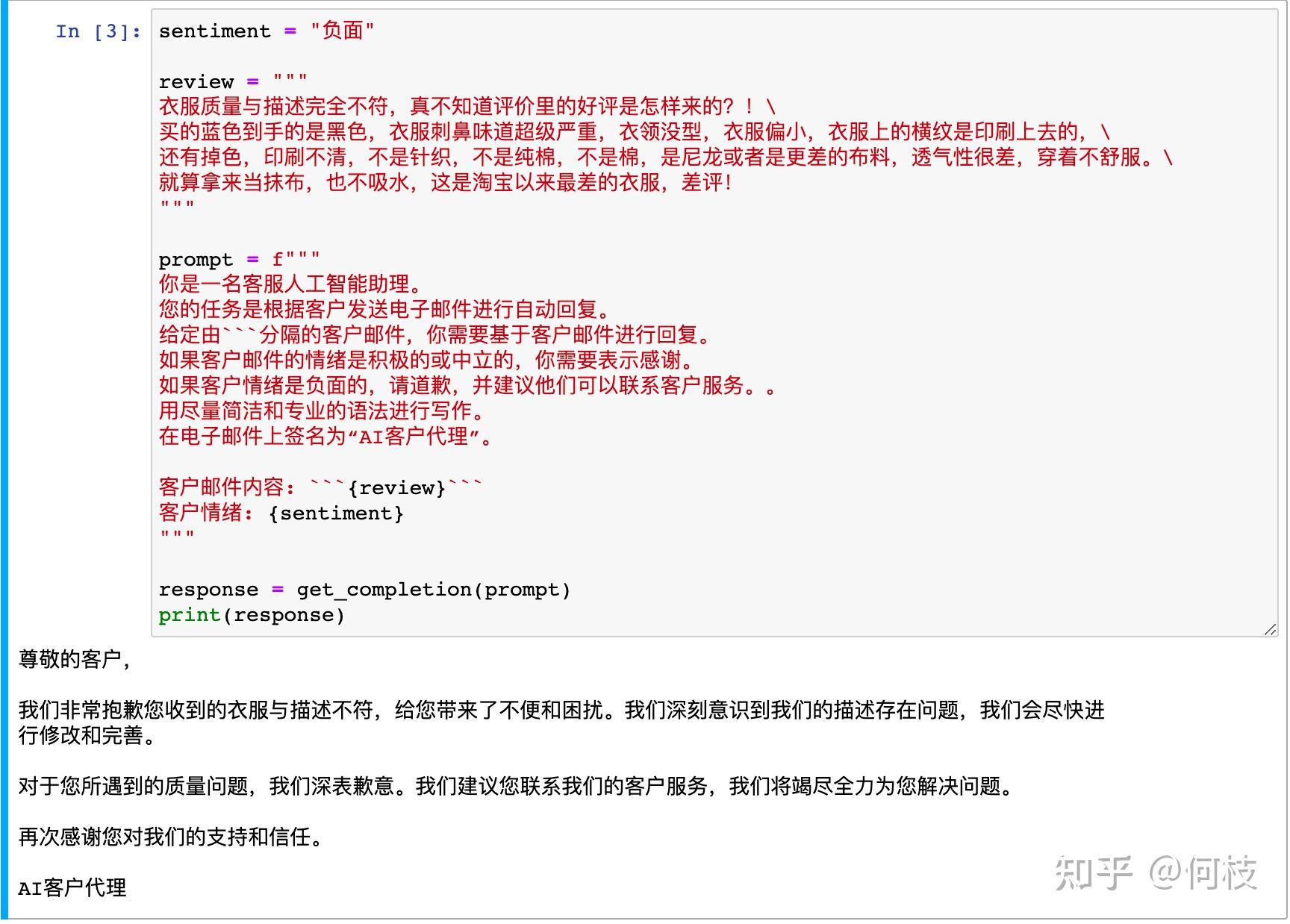
sentiment = "负面"
review = """
衣服质量与描述完全不符,真不知道评价里的好评是怎样来的?!\
买的蓝色到手的是黑色,衣服刺鼻味道超级严重,衣领没型,衣服偏小,衣服上的横纹是印刷上去的,\
还有掉色,印刷不清,不是针织,不是纯棉,不是棉,是尼龙或者是更差的布料,透气性很差,穿着不舒服。\
就算拿来当抹布,也不吸水,这是淘宝以来最差的衣服,差评!
"""
prompt = f"""
你是一名客服人工智能助理。
您的任务是根据客户发送电子邮件进行自动回复。
给定由```分隔的客户邮件,你需要基于客户邮件进行回复。
如果客户邮件的情绪是积极的或中立的,你需要表示感谢。
如果客户情绪是负面的,请道歉,并建议他们可以联系客户服务。。
用尽量简洁和专业的语法进行写作。
在电子邮件上签名为“AI客户代理”。
客户邮件内容: ```{review}```
客户情绪: {sentiment}
"""
上述内容中我们先识别出了用户的情绪,
并制定了如果用户是「正向情绪」,模型需要表示感谢,
如果是「负向情绪」,模型需要表达抱歉:
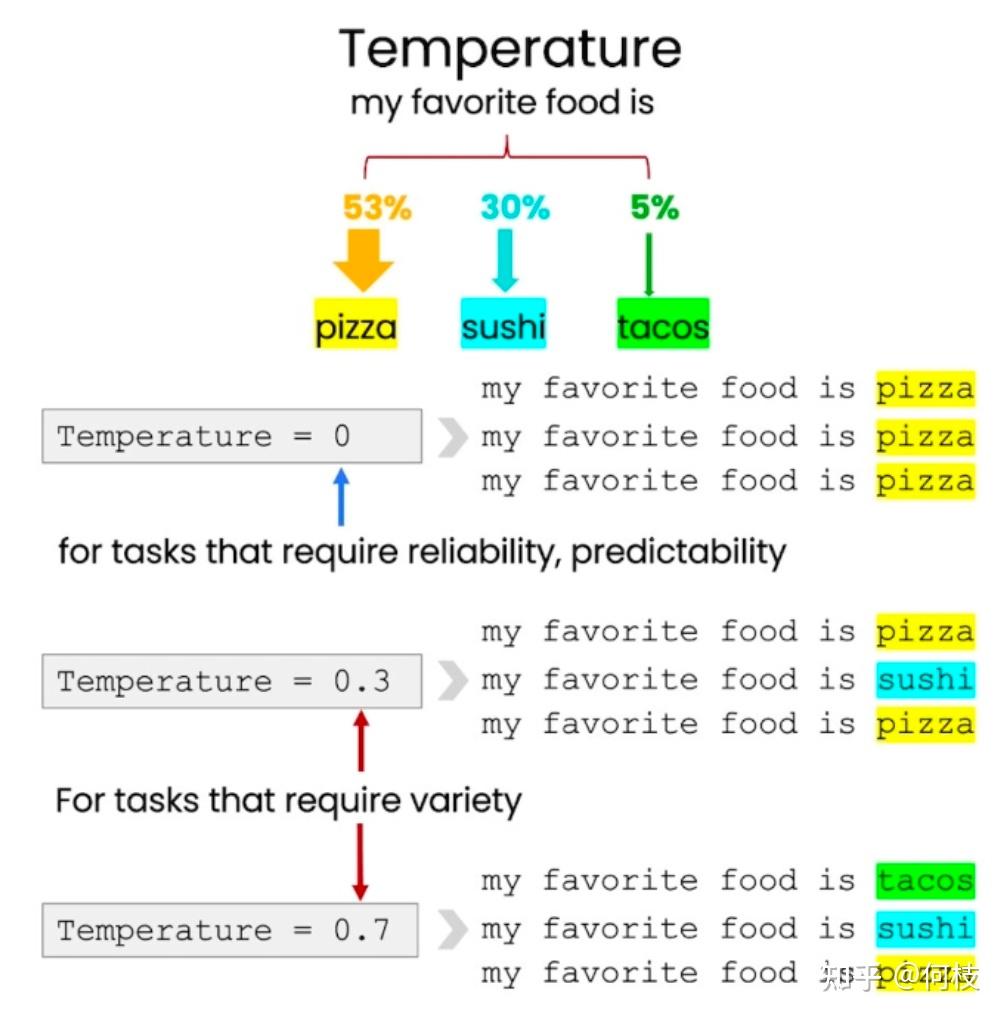
注意,这里提到了一个温度(Temperature)的概念。
简单来讲,温度越高,句子生成的越多样化,反之句子生成越固定。
六. 聊天机器人实战(ChatBot)
这一张主要讲如何通过 OpenAI 的 API 去构建一个多轮对话的机器人。
我们这里主要看一看 API 的接收内容就好:
messages = [
{'role':'system', 'content':'你是一个类似于Jarvis一样的人工智能助手。'},
{'role':'user', 'content':'帮我打造一套盔甲'},
{'role':'assistant', 'content':'好的,您需要一套什么样风格的盔甲呢,sir?'},
{'role':'user', 'content':'你的推荐呢?'}
]
上述列表中,每一行代表一轮对话信息。
每一行包括:「role」和「content」两个属性。
其中,role 用于指定说话者的身份,包含:system(系统指令)、user(用户)、assistant(ChatGPT)。
content 代表对应身份的人的历史回复内容。
上述输入的对应结果如下:
