1.通用设计方法
高并发系统通用的设计方法为拓展、缓存及异步。
- Scale-out(横向扩展):分而治之是一种常见的高并发系统设计方法,采用分布式部署的方式把流量分流开,让每个服务器都承担一部分并发和流量。
- 缓存:使用缓存来提高系统的性能,就好比用“拓宽河道”的方式抵抗高并发大流量的冲击。
- 异步:在某些场景下,未处理完成之前我们可以让请求先返回,在数据准备好之后再通知请求方,这样可以在单位时间内处理更多的请求。
1.1.水平拓展
- 垂直拓展通过购买性能更好的硬件来提升系统的并发处理能力,比方说目前系统 4 核 4G 每秒可以处理 200 次请求,那么如果要处理 400 次请求呢?很简单,我们把机器的硬件提升到 8 核 8G(硬件资源的提升可能不是线性的,这里仅为参考)。
- 水平拓展则是另外一个思路,它通过将多个低性能的机器组成一个分布式集群来共同抵御高并发流量的冲击。沿用刚才的例子,我们可以使用两台 4 核 4G 的机器来处理那 400 次请求。
一般来讲,在我们系统设计初期会考虑使用 Scale-up 的方式,因为这种方案足够简单,所谓能用堆砌硬件解决的问题就用硬件来解决,但是当系统并发超过了单机的极限时,我们就要使用 Scale-out 的方式。
1.2.缓存
Web 2.0 是缓存的时代,这一点毋庸置疑。缓存遍布在系统设计的每个角落,从操作系统到浏览器,从数据库到消息队列,任何略微复杂的服务和组件中你都可以看到缓存的影子。我们使用缓存的主要作用是提升系统的访问性能,在高并发的场景下就可以支撑更多用户的同时访问。
Web 2.0 是缓存的时代,这一点毋庸置疑。缓存遍布在系统设计的每个角落,从操作系统到浏览器,从数据库到消息队列,任何略微复杂的服务和组件中你都可以看到缓存的影子。我们使用缓存的主要作用是提升系统的访问性能,在高并发的场景下就可以支撑更多用户的同时访问。
普通磁盘的寻道时间是 10ms 左右,而相比于磁盘寻道花费的时间,CPU 执行指令和内存寻址的时间都是在 ns(纳秒)级别,从千兆网卡上读取数据的时间是在μs(微秒)级别。所以在整个计算机体系中磁盘是最慢的一环,甚至比其它的组件要慢几个数量级。因此我们通常使用以内存作为存储介质的缓存,以此提升性能。当然,缓存的语义已经丰富了很多,我们可以将任何降低响应时间的中间存储都称为缓存。缓存的思想遍布很多设计领域,比如在操作系统中 CPU 有多级缓存,文件有 Page Cache 缓存,你应该有所了解。
1.3.异步
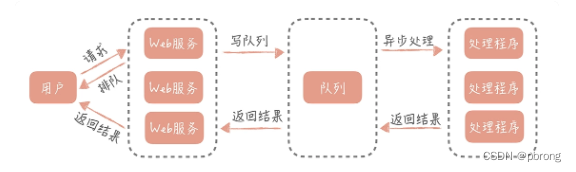
异步也是一种常见的高并发设计方法,与之共同出现的还有它的反义词:同步。比如分布式服务框架 Dubbo 中有同步方法调用和异步方法调用,IO 模型中有同步 IO 和异步 IO。
以方法调用为例,同步调用代表调用方要阻塞等待被调用方法中的逻辑执行完成。这种方式下,当被调用方法响应时间较长时,会造成调用方长久的阻塞,在高并发下会造成整体系统性能下降甚至发生雪崩。
异步调用恰恰相反,调用方不需要等待方法逻辑执行完成就可以返回执行其他的逻辑,在被调用方法执行完毕后再通过回调、事件通知等方式将结果反馈给调用方。
异步调用在大规模高并发系统中被大量使用,比如我们熟知的 12306 网站。当我们订票时,页面会显示系统正在排队,这个提示就代表着系统在异步处理我们的订票请求。在 12306 系统中查询余票、下单和更改余票状态都是比较耗时的操作,可能涉及多个内部系统的互相调用,如果是同步调用就会像 12306 刚刚上线时那样,高峰期永远不可能下单成功。
而采用异步的方式,后端处理时会把请求丢到消息队列中,同时快速响应用户,告诉用户我们正在排队处理,然后释放出资源来处理更多的请求。订票请求处理完之后,再通知用户订票成功或者失败。处理逻辑后移到异步处理程序中,Web 服务的压力小了,资源占用的少了,自然就能接收更多的用户订票请求,系统承受高并发的能力也就提升了。
2.架构分层
在系统从 0 到 1 的阶段,为了让系统快速上线,我们通常是不考虑分层的。但是随着业务越来越复杂,大量的代码纠缠在一起,会出现逻辑不清晰、各模块相互依赖、代码扩展性差、改动一处就牵一发而动全身等问题。
软件架构分层在软件工程中是一种常见的设计方式,它是将整体系统拆分成 N 个层次,每个层次有独立的职责,多个层次协同提供完整的功能。
2.1.经典的分层
一种常见的分层方式是将整体架构分为表现层、逻辑层和数据访问层:表现层,顾名思义嘛,就是展示数据结果和接受用户指令的,是最靠近用户的一层;逻辑层里面有复杂业务的具体实现;数据访问层则是主要处理和存储之间的交互。
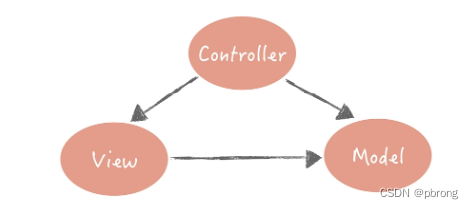
这是在架构上最简单的一种分层方式。其实,我们在不经意间已经按照三层架构来做系统分层设计了,比如在构建项目的时候,我们通常会建立三个目录:Web、Service 和 Dao,它们分别对应了表现层、逻辑层还有数据访问层。
工作中经常能用到 TCP/IP 协议,它把网络简化成了四层,即链路层、网络层、传输层和应用层。每一层各司其职又互相帮助,网络层负责端到端的寻址和建立连接,传输层负责端到端的数据传输等,同时相邻两层还会有数据的交互。这样可以隔离关注点,让不同的层专注做不同的事情。
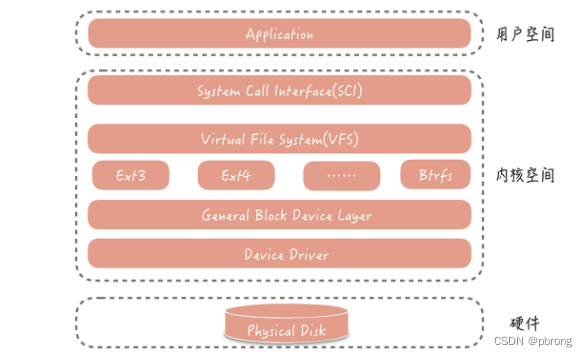
Linux 文件系统也是分层设计的,从下图你可以清晰地看出文件系统的层次。在文件系统的最上层是虚拟文件系统(VFS),用来屏蔽不同的文件系统之间的差异,提供统一的系统调用接口。虚拟文件系统的下层是 Ext3、Ext4 等各种文件系统,再向下是为了屏蔽不同硬件设备的实现细节,我们抽象出来的单独的一层——通用块设备层,然后就是不同类型的磁盘了。
2.2.为什么要分层
分层的设计可以简化系统设计,让不同的人专注做某一层次的事情。
- 分层之后可以做到很高的复用。比如,我们在设计系统 A 的时候,发现某一层具有一定的通用性,那么我们可以把它抽取独立出来,在设计系统 B 的时候使用起来,这样可以减少研发周期,提升研发的效率。
- 分层架构可以让我们更容易做横向扩展。如果系统没有分层,当流量增加时我们需要针对整体系统来做扩展。但是,如果我们按照上面提到的三层架构将系统分层后,就可以针对具体的问题来做细致的扩展。
单一职责原则规定每个类只有单一的功能,在这里可以引申为每一层拥有单一职责,且层与层之间边界清晰;迪米特法则原意是一个对象应当对其它对象有尽可能少的了解,在分层架构的体现是数据的交互不能跨层,只能在相邻层之间进行;而开闭原则要求软件对扩展开放,对修改关闭。它的含义其实就是将抽象层和实现层分离,抽象层是对实现层共有特征的归纳总结,不可以修改,但是具体的实现是可以无限扩展,随意替换的。
2.3.如何分层
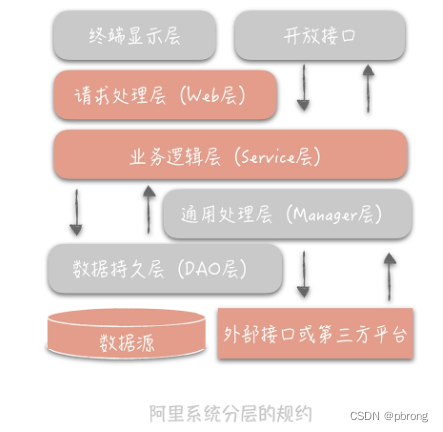
- 终端显示层:各端模板渲染并执行显示的层。当前主要是 Velocity 渲染,JS 渲染, JSP 渲染,移动端展示等。
- 开放接口层:将 Service 层方法封装成开放接口,同时进行网关安全控制和流量控制等。Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
- Service 层:业务逻辑层。
- Manager 层:通用业务处理层。这一层主要有两个作用,其一,你可以将原先 Service 层的一些通用能力下沉到这一层,比如与缓存和存储交互策略,中间件的接入;其二,你也可以在这一层封装对第三方接口的调用,比如调用支付服务,调用审核服务等。
- DAO 层:数据访问层,与底层 MySQL、Oracle、HBase 等进行数据交互。
- 外部接口或第三方平台:包括其它部门 RPC 开放接口,基础平台,其它公司的 HTTP 接口。
在这个分层架构中主要增加了 Manager 层,它与 Service 层的关系是:Manager 层提供原子的服务接口,Service 层负责依据业务逻辑来编排原子接口。
3.小结
关于系统的设计,罗马不是一天建成的,系统的设计也是如此。不同量级的系统有不同的痛点,也就有不同的架构设计的侧重点。如果都按照百万、千万并发来设计系统,电商一律向淘宝看齐,IM 全都学习微信和 QQ,那么这些系统的命运一定是灭亡。
一般系统的演进过程应该遵循下面的思路:
- 最简单的系统设计满足业务需求和流量现状,选择最熟悉的技术体系。
- 随着流量的增加和业务的变化修正架构中存在问题的点,如单点问题、横向扩展问题、性能无法满足需求的组件。在这个过程中,选择社区成熟的、团队熟悉的组件帮助我们解决问题,在社区没有合适解决方案的前提下才会自己造轮子。
- 当对架构的小修小补无法满足需求时,考虑重构、重写等大的调整方式以解决现有的问题。
核心:高并发系统的演进应该是循序渐进,以解决系统中存在的问题为目的和驱动力的。
关于系统分层,任何事物都不可能是尽善尽美的,分层架构虽有优势也会有缺陷,它最主要的一个缺陷就是增加了代码的复杂度。另外一个可能的缺陷是,如果我们把每个层次独立部署,层次间通过网络来交互,那么多层的架构在性能上会有损耗。这也是为什么服务化架构性能要比单体架构略差的原因,也就是所谓的“多一跳”问题。
但是分层带来的好处也很多,在高并发系统中可以很好地对各个组成系统进行水平拓展,而不用牵一发而动全身。