在上一篇文章中,介绍了sentinel的使用,在这一篇文章中,会对sentinel的原理通过源码进行进一步的分析。源码下载地址:sentinel源码下载地址
目录
一 核心概念
在了解源码之前,我们需要先对一些核心概念进行了解,有助于我们了解源码。我们先看一张sentinel官网的框架图:
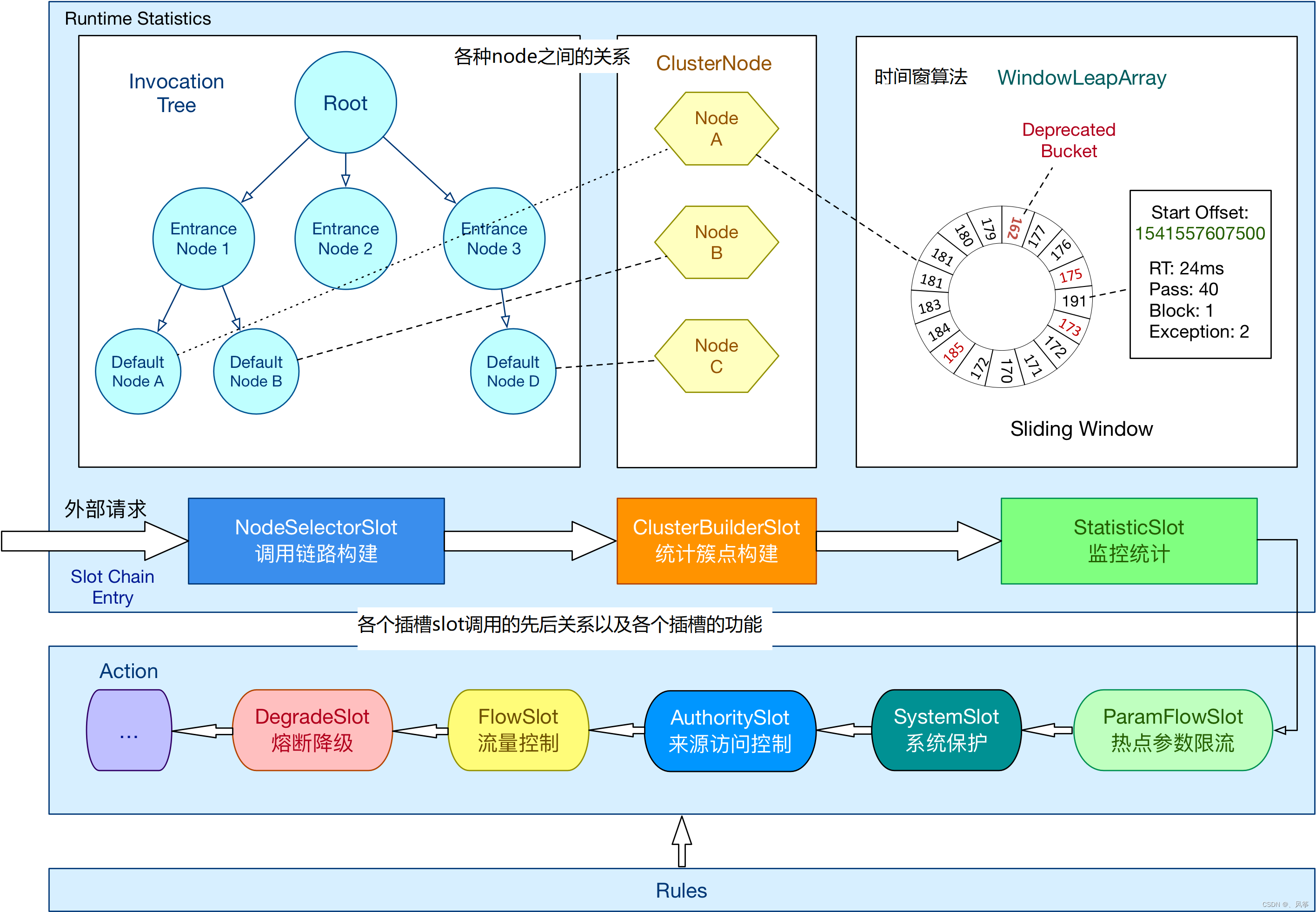
slot chain:功能插槽,不同的插槽有不同的功能,有七种系统定义的插槽,当然也可以自定义插槽,自定义功能插槽,它的执行顺序是在FlowSlot之前。七种系统定义的插槽分别为(资料来源为sentinel官网):
NodeSelectorSlot:主要用于收集资源的路径,并将这些资源的调用路径用树桩结构存储下来,这个树形结构的各个节点会在下面介绍到;
ClusterBuilderSlot:用于存储资源的统计信息以及调用者信息,例如资源的qps(每秒钟访问数量),rt(接口的响应时间),线程数量等信息,这些信息将作为多维度限流以及降级的依据,对应簇点链路。构建ClusterNode节点信息。
StaticSlot:用于记录、统计不同维度的runtime指标监控信息,是实时监控,底层采用滑动时间窗口算法(会在本章节的后续内容中介绍)。
后面的ParamFlowSlot,SystemSlot,AuthoritySlot,FlowSlot,DegradeSlot是对应限流熔断中的各个校验的插槽,用于判断对应限流降级类型的是否满足规则,如果满足,则进行限流降级;否则,正常通过。
Node:存储节点信息,用于存储资源不同维度的信息,node有以下几种分类,分别是:
StatisticNode:统计节点,用于完成数据统计;
EntranceNode:属于入口节点,用于统计一个Context的总体流量数据,它的统计维度是context;
DefaultNode:用于统计一个Resource在当前context中的流量数据,它的统计维度为context+resource;
ClusterNode:用于保存一个Resource在不同context中的流量数据,它的统计维度为resource;
咱们将上面架构图中的node节点的架构信息重新整理一下,方便我们进行了解,如下图:
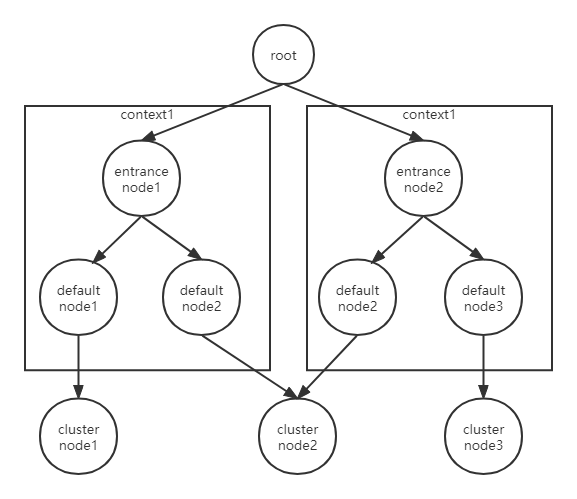
Context:对资源操作时的上下文环境,每个资源操作必须属于一个Context,如果程序中未指定Context,会创建name为"sentinel_default_context"的Context。一个Context生命周期内可能有多个资源操作,Context生命周期的最后一个资源exit时会清理Context,这也预示着这个Context生命周期结束;
Entry:表示一次资源操作,内部会保存当前调用信息。在一个Context生命周期中多次资源操作,也就会对应多个Entry,这些Entry行程parent/child结构报错在Entry实例中。
二 源码分析
1 源码入口
接下来,我们进入限流降级的源码分析。通过我们对sentinel的使用,会发现他其实是使用的aop,也就是切面编程。他没有侵入到我们编写的业务代码中,但是再每次请求的时候,都会触发限流降级的校验。再加上我们在使用自定义的时候,使用到了@SentinelResource注解,我可以以此为依据,能够从源码中发现其对应的切面:SentinelResourceAspect,在这里定义了切点,通知等信息
// 切面
@Aspect
public class SentinelResourceAspect extends AbstractSentinelAspectSupport {
// 切点
@Pointcut("@annotation(com.alibaba.csp.sentinel.annotation.SentinelResource)")
public void sentinelResourceAnnotationPointcut() {
}
// 环绕通知
@Around("sentinelResourceAnnotationPointcut()")
public Object invokeResourceWithSentinel(ProceedingJoinPoint pjp) throws Throwable {
....
String resourceName = getResourceName(annotation.value(), originMethod);
EntryType entryType = annotation.entryType();
int resourceType = annotation.resourceType();
Entry entry = null;
try {
// 这里就对应我们所说的资源对象entry
entry = SphU.entry(resourceName, resourceType, entryType, pjp.getArgs());
// 调用原方法,通过限流降级规则
return pjp.proceed();
} catch (BlockException ex) {
// 限流或者降级
return handleBlockException(pjp, annotation, ex);
} catch (Throwable ex) {
...
} finally {
if (entry != null) {
entry.exit(1, pjp.getArgs());
}
}
}
}通过上面我们可以知道,其实主要的方法就是Entry对象的创建,里面包含了sentinel工作原理的所有处理,接下来我们继续跟进,跳过其中一系列的重载方法,我们直接跟进到以下代码:
@Override
public Entry entryWithType(String name, int resourceType, EntryType entryType, int count, boolean prioritized,
Object[] args) throws BlockException {
// 第一步,分装资源对象,是根据资源名称以及@SentinelResource注解中的相关信息
StringResourceWrapper resource = new StringResourceWrapper(name, entryType, resourceType);
// 第二步,进入sentinel具体的工作流程,prioritized这个字段默认是false,标识不按照优先级的方式执行接下来的流程
return entryWithPriority(resource, count, prioritized, args);
}接下来我们就进入到entryWithPriority的流程中,在这里,主要做了三件事情,1.获取context;2.构建责任链,使用的spi接口扩展;3.执行责任链。
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args)
throws BlockException {
// 第一步,获取context
// 通过跟进代码,发现这里是通过从ThreadLocal中获取
Context context = ContextUtil.getContext();
// 如果获取的是NullContext类型,则为当前context的数量超多阈值,然后只进行Entry的初始化
if (context instanceof NullContext) {
return new CtEntry(resourceWrapper, null, context);
}
// 如果context为空,则进行context的初始化操作
if (context == null) {
// 初始化时,默认的context的名称为sentinel_default_context,和上面介绍核心概念时的介绍匹配上了
context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
}
// 如果全局的限流规则为关闭,只进行Entry资源的初始化
if (!Constants.ON) {
return new CtEntry(resourceWrapper, null, context);
}
/**第二步 构建责任链
*这里进行一下重点说明,这里采用了spi的接口扩展方式构建处理链,处理链的数据结构为单向链表
*之所以构建这个单向链表,目的为了与业务进行解耦,因为限流降级规则很多,如果写在一起,耦合会
*很严重,为了遵循oop的设计思想,因此进行解耦,各司其职
* /
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
if (chain == null) {
return new CtEntry(resourceWrapper, null, context);
}
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
// 第三步,责任链的执行,针对上下文和资源进行操作
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) {
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}2 context获取
接下来,首先梳理一下context的获取,1.从当前线程中的缓存中获取context;2.如果当前线程还未创建context,则进行context的初始化。接下来我们主要看一下context的初始化流程,在该流程中用到了我们单例模式中的一种方式,双重检查,保证线程安全,通过双重检查的方式创建entranceNode。通过代码的跟进,我们直接定位到trueEnter方法。我们直接来看代码
protected static Context trueEnter(String name, String origin) {
// 从当前线程中再次获取,进行线程安全保证
Context context = contextHolder.get();
if (context == null) {
// 如果当前线程中context为空,则从缓存中获取node信息
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
DefaultNode node = localCacheNameMap.get(name);
if (node == null) {
// 如果node信息为空,判断当前context的容量是否超过限制,如果是,则直接返回,不进行流控校验
if (localCacheNameMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
// 这里相信大家非常熟悉,采用了双重检查的方式,保证线程安全
LOCK.lock();
try {
node = contextNameNodeMap.get(name);
if (node == null) {
if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
// 进行节点创建,这里创建的是EntranceNode,在上面介绍核心概念的时候,我们知道,它的统计维度为context
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
// 在上面介绍核心概念的时候,我们说过,node的存储结构是树状结构,这里就是树的构建
Constants.ROOT.addChild(node);
Map<String, DefaultNode> newMap = new HashMap<>(contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
}
} finally {
LOCK.unlock();
}
}
}
// 根据node以及contextName创建context
context = new Context(node, name);
context.setOrigin(origin);
contextHolder.set(context);
}
return context;
}3 责任链的构建以及执行
构建完context以后,接下来是就是责任链的构建,在这里我们我们会看淡slot链的初始化,大家还记得架构图中的插槽的调用顺序吗,在这里会进行体现,接下来我们直接看代码:
// CtSph.lookProcessChain获取责任链
ProcessorSlot<Object> lookProcessChain(ResourceWrapper resourceWrapper) {
// 通过资源信息,从缓存中获取责任链信息
ProcessorSlotChain chain = chainMap.get(resourceWrapper);
if (chain == null) {
// 通过创冲检查的方式获取责任链信息,保证线程安全,也保证值加载一次
synchronized (LOCK) {
chain = chainMap.get(resourceWrapper);
if (chain == null) {
// 责任链缓存的长度超过最大值,则返回null
if (chainMap.size() >= Constants.MAX_SLOT_CHAIN_SIZE) {
return null;
}
// 进行责任链的初始化,初始化完成后,将责任链信息放入缓存中
chain = SlotChainProvider.newSlotChain();
Map<ResourceWrapper, ProcessorSlotChain> newMap = new HashMap<ResourceWrapper, ProcessorSlotChain>(
chainMap.size() + 1);
newMap.putAll(chainMap);
newMap.put(resourceWrapper, chain);
chainMap = newMap;
}
}
}
return chain;
}
// SlotChainProvider.newSlotChain 初始化责任链
public static ProcessorSlotChain newSlotChain() {
if (slotChainBuilder != null) {
return slotChainBuilder.build();
}
// 获取责任链的构建器,读取的是配置文件
// META-INF/services/com.alibaba.csp.sentinel.slotchain.SlotChainBuilder
slotChainBuilder = SpiLoader.of(SlotChainBuilder.class).loadFirstInstanceOrDefault();
if (slotChainBuilder == null) {
RecordLog.warn("[SlotChainProvider] Wrong state when resolving slot chain builder, using default");
slotChainBuilder = new DefaultSlotChainBuilder();
} else {
RecordLog.info("[SlotChainProvider] Global slot chain builder resolved: {}",
slotChainBuilder.getClass().getCanonicalName());
}
// 通过责任链构建器,初始化责任链
return slotChainBuilder.build();
}
// DefaultSlotChainBuilder.build真正进行责任链,也就是slot插槽的构建
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
// 读取配置文件
// META-INF/services/com.alibaba.csp.sentinel.slotchain.ProcessorSlot
List<ProcessorSlot> sortedSlotList = SpiLoader.of(ProcessorSlot.class).loadInstanceListSorted();
// 对获取的slot进行校验,排除类型不是AbstractLinkedProcessorSlot的slot
for (ProcessorSlot slot : sortedSlotList) {
if (!(slot instanceof AbstractLinkedProcessorSlot)) {
RecordLog.warn("The ProcessorSlot(" + slot.getClass().getCanonicalName() + ") is not an instance of AbstractLinkedProcessorSlot, can't be added into ProcessorSlotChain");
continue;
}
chain.addLast((AbstractLinkedProcessorSlot<?>) slot);
}
return chain;
}在创建责任链的时候,通过上面的源码分析,我们可以知道,它是通过spi扩展接口的方式读取配置文件,注意上面的注释中的配置文件位置是相对位置,这两个配置文件是在sentinel-core子模块中,我们看一下这两个配置文件中的内容。
SlotChainBuilder:
com.alibaba.csp.sentinel.slots.DefaultSlotChainBuilderProcessorSlot:
com.alibaba.csp.sentinel.slots.nodeselector.NodeSelectorSlot
com.alibaba.csp.sentinel.slots.clusterbuilder.ClusterBuilderSlot
com.alibaba.csp.sentinel.slots.logger.LogSlot
com.alibaba.csp.sentinel.slots.statistic.StatisticSlot
com.alibaba.csp.sentinel.slots.block.authority.AuthoritySlot
com.alibaba.csp.sentinel.slots.system.SystemSlot
com.alibaba.csp.sentinel.slots.block.flow.FlowSlot
com.alibaba.csp.sentinel.slots.block.degrade.DegradeSlot看一下上面这个配置文件中的类名,大家有没有感觉到很熟悉,正好对应架构图中的slot信息,从上到下的这个顺序也正好是slot的调用顺序。这个顺序也是我们接下来的要记住的,在进行责任链的业务功能执行时,就是按照这个顺序执行的,即责任链的单向链表就根据这个配置文件,从上到下进行构建的。
最后,我们就进入到责任链针对资源的操作,包含资源统计,限流降级等,接下来,我们进入到具体的代码中进行分析。根据上面配置文件中的配置内容,我们知道责任链的第一个slot为NodeSelectNode。
NodeSelectNode.entry是责任链开始的起点,从这里开始责任链的调用,并且在这里会创建DefaultNode。
public void entry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, boolean prioritized, Object... args)
// 根据context的name获取DefaultNode信息
// 从核心概念中我们可以这道,DefaultNode统计信息的维度为context+resource
DefaultNode node = map.get(context.getName());
if (node == null) {
// 如果defaultNodez还没被撞见,则通过双重检查的方式进行创建
synchronized (this) {
node = map.get(context.getName());
node = new DefaultNode(resourceWrapper, null);
HashMap<String, DefaultNode> cacheMap = new HashMap<String, DefaultNode>(map.size());
cacheMap.putAll(map);
// 将创建的node放入缓存中
cacheMap.put(context.getName(), node);
map = cacheMap;
// 将新建的node放入到node树中
((DefaultNode) context.getLastNode()).addChild(node);
}
}
}
context.setCurNode(node);
// 触发下一个节点
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
// 这里使用了模板的设计模式,所有的slot都是AbstractLinkedProcessorSlot的子类,在父类中定义了触发下一个slot的方法
public void fireEntry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, boolean prioritized, Object... args)
throws Throwable {
// 如果责任链中slot还没执行结束,则执行下一个slot,这里的next根据上一个的slot,根据配置文件中由上到下的顺序,
// 在后面slot的执行中,我们会经常的调用到这个方法,要根据上一个调用者来确定下一个slot
if (next != null) {
next.transformEntry(context, resourceWrapper, obj, count, prioritized, args);
}
}
// 进入到下一个slot中的处理中
void transformEntry(Context context, ResourceWrapper resourceWrapper, Object o, int count, boolean prioritized, Object... args)
throws Throwable {
T t = (T)o;
entry(context, resourceWrapper, t, count, prioritized, args);
}
由配置文件中的slot顺序,我们可以知道,接下来应该是调用ClusterBuilderSlot.entry方法,在该方法中,这个方法的作用是ClusterNode的初始化以及与DefaultNode建立关系,该node存储资源的调用信息以及调用者信息,例如资源的RT,QPS等,这些数据是作为限流,降级的依据。
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args)
throws Throwable {
// 通过双重检查的方式创建ClusterNode,
// 在核心概念中我们知道,ClusterNode统计数据的维度是Resource
if (clusterNode == null) {
synchronized (lock) {
if (clusterNode == null) {
// Create the cluster node.
clusterNode = new ClusterNode(resourceWrapper.getName(), resourceWrapper.getResourceType());
HashMap<ResourceWrapper, ClusterNode> newMap = new HashMap<>(Math.max(clusterNodeMap.size(), 16));
newMap.putAll(clusterNodeMap);
newMap.put(node.getId(), clusterNode);
clusterNodeMap = newMap;
}
}
}
// 将clusterNode和DefaultNode进行关联
node.setClusterNode(clusterNode);
// 确认资源来源
if (!"".equals(context.getOrigin())) {
Node originNode = node.getClusterNode().getOrCreateOriginNode(context.getOrigin());
context.getCurEntry().setOriginNode(originNode);
}
// 进入下一个slot的执行
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}接下来就进入到StaticSlot,这个slot属于一个很关键的slot,这个slot也是sentinel中一个关键算法的入口,也就是滑动时间窗算法,在这里会进行数据的统计,就是通过这个算法进行数据统计,那接下来我们就看一下源码中的数据。时间窗算法会在后面进行详细讲解,这里就不进行拆解了。
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
try {
// 会调用slotchain后续的所有slot,进行规则统计
fireEntry(context, resourceWrapper, node, count, prioritized, args);
// 增加线程数,这里是使用的原子类LongAddr,感性的同学可以去看我以前的文章,有对它的讲解
node.increaseThreadNum();
// 增加通过请求的数量(滑动时间窗算法)
node.addPassRequest(count);
......
}上面这三个slot是为了进行限流降级的准备以及善后工作,接下来就进入到具体的流控规则slot,由于篇幅的原因,我们只介绍FlowSlot以及DegradeSlot这两个slot进行源码介绍,其余的slot感兴趣的同学可以自己去看一下。
FlowSlot就是我们说的限流规则的slot,根据预设的资源统计信息,进行流控规则的校验,在这里也会补充到上一篇文章中关于流控规则持久化的配置字段信息,我们可以在这里找到对应的资源信息以及枚举信息。
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
// 监测并且应用流量规则
checkFlow(resourceWrapper, context, node, count, prioritized);
// 触发下一个slot
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
// 我们根据代码的调用,定位到下面的这个方法
public void checkFlow(Function<String, Collection<FlowRule>> ruleProvider, ResourceWrapper resource,
Context context, DefaultNode node, int count, boolean prioritized) throws BlockException {
// 判断资源和规则不能为空
if (ruleProvider == null || resource == null) {
return;
}
// 根据资源名获取所有流控规则,我们跟进去以后会发现,他是通过FlowRuleManager来进行FlowRule的管理
Collection<FlowRule> rules = ruleProvider.apply(resource.getName());
if (rules != null) {
// 每一个规则进行校验,如果校验失败,则抛出异常,抛出的异常是FlowException
// sentinel触发流控的规则时会抛出BlockException,我们查看FlowException会发现它是BlockException的子类
for (FlowRule rule : rules) {
if (!canPassCheck(rule, context, node, count, prioritized)) {
throw new FlowException(rule.getLimitApp(), rule);
}
}
}
}这里我们看一下FlowRule的源码,这里面就是对应流控规则持久化时的相关字段。这里的各个字段对应的就是我们上篇文章中配置的限流规则,进行持久化时,就可以按照下面字段以及对应枚举进行配置。
// 阈值类型,默认为1-qps,还有0-并发线程数
private int grade = RuleConstant.FLOW_GRADE_QPS;
// 单机阈值
private double count;
// 流控模式,0-直接,1-关联,2-链路
private int strategy = RuleConstant.STRATEGY_DIRECT;
// 流控模式为关联时,设置的关联资源
private String refResource;
// 流控效果,0-快速失败,1-预热(warm up),2-排队等待
private int controlBehavior = RuleConstant.CONTROL_BEHAVIOR_DEFAULT;
// 预热时长
private int warmUpPeriodSec = 10;
// 排队超时时长
private int maxQueueingTimeMs = 500;
// 集群模式
private boolean clusterMode;流控效果中的预热和排队等待涉及到了两种算法,分别是令牌桶算法和漏斗算法,在后续算法的相关文章中,会进行详细介绍,这里就简单的说明一下。
令牌桶算法:系统会以恒定的速度往桶里放入令牌,当请求需要被处理时,需要先从桶中获取一个令牌,当桶里没有令牌时,拒绝服务。
漏斗算法:请求会先进入到漏桶里面,漏桶里面会以固定的速度放出请求,进行处理;但是当漏桶中的请求数量超出桶的容量时,直接拒绝。
接下来我们看一下canPass方法,在这个方法中,我们会选择是集群流控校验,还是单机流控校验,代码就不放出来了,我们这边会去分析单机流控校验,也就是passLocalCheck方法,在这个方法中做了两件事情:1.根据限流规则,上下文以获取node信息,也就是存储统计信息的节点;2.根据在rule中配置的流控效果来选择具体的controller执行canPass方法。
private static boolean passLocalCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
// 根据请求获取节点,我们去跟进代码,在这个方法中会根据context和rule的信息,来返回不同的node节点
// 我们以流控模式为直接时为例,它返回的就是ClusterNode
Node selectedNode = selectNodeByRequesterAndStrategy(rule, context, node);
if (selectedNode == null) {
return true;
}
// 根据rule中配置的流控效果选择对应的类进行处理,我们会发现这里会有四个controller
// DefaultController 流控效果为快速失败
// WarmUpController 流控效果为预热(warm up)
// RateLimiterController 流控效果为排队等待
// WarmUpRateLimiterController 预热+排队等待,需要注意的是,这种方式在dashbord中是无法直接配置的
return rule.getRater().canPass(selectedNode, acquireCount, prioritized);
}我们以快速失败为例,来继续往下分析,在这里说一点题外话,在进行源码分析的时候,我们可以以简单的分支进行分析,也就是DefaultController.canPass方法。在这个方法中主要做了两件事情:1.进行当前数据的计算;2.进行限流规则的校验。
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
// 获取当前node节点的线程数或者qps总数,在这里就涉及到了滑动窗口算法
int curCount = avgUsedTokens(node);
// 当前请求数+申请的请求数量 > 阈值
if (curCount + acquireCount > count) {
if (prioritized && grade == RuleConstant.FLOW_GRADE_QPS) {
long currentTime;
long waitInMs;
currentTime = TimeUtil.currentTimeMillis();
waitInMs = node.tryOccupyNext(currentTime, acquireCount, count);
if (waitInMs < OccupyTimeoutProperty.getOccupyTimeout()) {
node.addWaitingRequest(currentTime + waitInMs, acquireCount);
node.addOccupiedPass(acquireCount);
sleep(waitInMs);
throw new PriorityWaitException(waitInMs);
}
}
return false;
}
return true;
}最后我们再分析一下DegradeSlot,它的代码和其它的规则slot有些不同,DegradeSlot代表的是熔断器的slot,我们知道熔断器的熔断规则:平均响应时间,异常数和异常比例,这些数据必须是在接口调用完毕以后才能得到,因此DegradeSlot再entry里面只是进行熔断规则的获取,熔断规则的校验则是在exit中执行的。我们先看一下熔断规则的获取,顺带看一下熔断规则的实体类,用于实体化的配置。
void performChecking(Context context, ResourceWrapper r) throws BlockException {
// 获取所有资源的熔断器
List<CircuitBreaker> circuitBreakers = DegradeRuleManager.getCircuitBreakers(r.getName());
if (circuitBreakers == null || circuitBreakers.isEmpty()) {
return;
}
for (CircuitBreaker cb : circuitBreakers) {
// 对当前熔断状态进行判断,我们在上一章中也说过有关熔断状态的判断
if (!cb.tryPass(context)) {
throw new DegradeException(cb.getRule().getLimitApp(), cb.getRule());
}
}
}
public class DegradeRule extends AbstractRule {
// 熔断策略,0-慢调用比例,1-异常比例,2-异常数量
private int grade = RuleConstant.DEGRADE_GRADE_RT;
// 阈值
private double count;
// 熔断时长
private int timeWindow;
// 最小请求数量
private int minRequestAmount = RuleConstant.DEGRADE_DEFAULT_MIN_REQUEST_AMOUNT;
// 慢调用比例
private double slowRatioThreshold = 1.0d;
// 慢调用统计时长
private int statIntervalMs = 1000;
}
enum State {
// 开启状态,服务熔断
OPEN,
// 半开启状态,超出熔断时间后,如果下次请求正常,则服务恢复正常;否则,继续熔断
HALF_OPEN,
// 关闭状态,服务正常
CLOSED
}
接下来我们就去看熔断规则校验的流程,在exit方法中主要做了两件事情:1.判断其它slot是否出现异常,如果出现,则直接结束,无需继续校验;2.根据资源名获取熔断规则,并进行熔断规则校验。
熔断规则校验有两个方法,一个是ExceptionCircuitBreaker,异常熔断规则;一个是ResponseTimeCircuitBreaker响应时间熔断规则,在这里我们先只关注ExceptionCircuitBreaker异常熔断规则
public void onRequestComplete(Context context) {
Entry entry = context.getCurEntry();
if (entry == null) {
return;
}
Throwable error = entry.getError();
// 异常事件窗口计数器
SimpleErrorCounter counter = stat.currentWindow().value();
// 本次请求是否抛异常,如果是,则异常数加一
if (error != null) {
counter.getErrorCount().add(1);
}
// 请求总数加一
counter.getTotalCount().add(1);
// 熔断规则校验
handleStateChangeWhenThresholdExceeded(error);
}
private void handleStateChangeWhenThresholdExceeded(Throwable error) {
// 如果熔断器为开启状态,则直接返回
if (currentState.get() == State.OPEN) {
return;
}
// 如果熔断状态为半开启
if (currentState.get() == State.HALF_OPEN) {
// 如果本次请求为正常请求,则将熔断状态置为关闭,通过cas的方式
if (error == null) {
fromHalfOpenToClose();
} else {
// 将熔断状态置为开启状态,在修改状态时需要计算下次半开启状态的起始时间
fromHalfOpenToOpen(1.0d);
}
return;
}
List<SimpleErrorCounter> counters = stat.values();
long errCount = 0;
long totalCount = 0;
// 统计总的异常请求数以及总请求数
for (SimpleErrorCounter counter : counters) {
errCount += counter.errorCount.sum();
totalCount += counter.totalCount.sum();
}
// 如果总请求数没有超过最小请求数量,则直接返回
if (totalCount < minRequestAmount) {
return;
}
double curCount = errCount;
// 如果熔断策略为异常比例,则计算异常比例
if (strategy == DEGRADE_GRADE_EXCEPTION_RATIO) {
curCount = errCount * 1.0d / totalCount;
}
// 如果异常数量/异常比例达到了熔断标砖,则将熔断器置为开启状态
if (curCount > threshold) {
transformToOpen(curCount);
}
}三 滑动时间窗算法
滑动时间窗算法,是sentinel内部进行数据统计的核心算法,在上面的架构图中我们会发现,整个时间窗为一个环形数据组,在环形数组里面的每一个元素为一个时间样本窗口,样本窗口都有自己的长度,它的长度是固定的,因此每个时间窗的长度也是固定的,在进行数据统计的时候,它会计算出当前时间所在的时间样本窗口,然后计算出该样本窗口的统计数据,然后再计算出该时间窗口中其它的样本窗口的统计总数量,两个统计数量进行相加,这样就得出该时间窗口的总值。当然这种计算方式会存在一定的误差,当前时间可能还没达到其所属时间窗口的结束位置,这种误差是规则内允许的,无需去纠结。
1 滑动时间窗算法存储数据
接下来,我们看一下滑动时间窗算法的源码,进行进一步了解。在上一部分的源码讲解中,时间窗的数据统计是在StatisticSlot中node.addPassRequest,我们以此为入口,进入源码分析。通过代码分析,我们进入到StatisticSlot的addPassRequest方法,在这里进行滑动计数器进行本次数据的添加。我们继续进行代码跟进,进入到ArrayMetric.addPass方法中。
public void addPass(int count) {
// 获取当前时间点所在的样本窗口
WindowWrap<MetricBucket> wrap = data.currentWindow();
// 在当前样本窗口中加入本次请求
wrap.value().addPass(count);
}我们先看第一行代码,跟进到LeapArray.currentWindow()方法,我们先看LeapArray这个类,这个类就是架构图中的那个环形数组,我们先看一下这里面的元素
ublic abstract class LeapArray<T> {
// 样本窗口长度
protected int windowLengthInMs;
// 一个时间窗口中包含的样本窗口量
protected int sampleCount;
// 时间窗的长度
protected int intervalInMs;
private double intervalInSecond;
// 元素为样本窗口类型,这里的泛型实际为MetricBucket
protected final AtomicReferenceArray<WindowWrap<T>> array;
......
}里面还有一个类型,即WindowWrp,我们看一下这个类,它里面有队样本的窗口的一些定义
public class WindowWrap<T> {
// 样本窗口长度
private final long windowLengthInMs;
// 样本窗口的起始时间戳
private long windowStart;
// 存储具体的统计数据,类型为MetricBucket,统计的多维数据存储在MetricEvent中
private T value;
......
}看完这两类以后,我们会到原来的方法调用中,通过代码跟进,我们会进入到LeapArray.currentWindow方法中。
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
// 计算当前时间所在的样本窗口所在的索引,计算方式为当前时间戳/样本的窗口长度,然后用计算出的值对样本数量取余
int idx = calculateTimeIdx(timeMillis);
// 计算当前样本窗口的开始时间点,计算方式为,当前时间-(当前时间%样本窗口长度)
long windowStart = calculateWindowStart(timeMillis);
while (true) {
// 根据计算得到的索引,获取当前时间窗中的样本窗口
WindowWrap<T> old = array.get(idx);
// 如果当前样本窗口不存在,则进行样本窗口的新建
if (old == null) {
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
if (array.compareAndSet(idx, null, window)) {
return window;
} else {
Thread.yield();
}
} else if (windowStart == old.windowStart()) {
// 如果当前时间所在样本窗口的开始时间等于计算得到的样本窗口的开始时间,证明这两个窗口是同一个,直接返回
return old;
} else if (windowStart > old.windowStart()) {
// 如果当前时间所在样本窗口的开始时间大于计算得到的样本窗口的开始时间,则证明原有样本窗口已经过期,需要进行替换
if (updateLock.tryLock()) {
try {
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
Thread.yield();
}
} else if (windowStart < old.windowStart()) {
// 这种情况再正常情况下是不会出现的,除非调整服务器时间,我们不做过多分析
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}我们得到当前的样本窗口以后,接下来就是将本次请求信息添加到样本窗口中
// 需要注意这里存储多维度数据使用的是LongAddr[],这里是在数组下标代表的是PASS的位置进行数据相加
public void addPass(int n) {
add(MetricEvent.PASS, n);
}
// 我们看一下MetricEvent
public enum MetricEvent {
PASS,
BLOCK,
EXCEPTION,
SUCCESS,
RT,
OCCUPIED_PASS
}2 滑动时间窗算法获取数据
到此为止,通过滑动时间窗算法往里面添加数据的流程就结束了,接下来我们在看一下通过滑动时间窗算法获取数据的源码部分。在上面介绍FlowSlot源码的时候,在代码中我们提到过滑动时间窗算法,是在DefaultController.pass方法中,大家还记得这个方法是做什么的吧,他是处理限流效果为直接失败的处理controller。我们注意这个方法中的
// int curCount = avgUsedTokens(node);获取当前node节点的线程数或者qps
private int avgUsedTokens(Node node) {
if (node == null) {
return DEFAULT_AVG_USED_TOKENS;
}
// 根据不同的数据类型湖区不同的值,这里我们以qps分支分析
return grade == RuleConstant.FLOW_GRADE_THREAD ? node.curThreadNum() : (int)(node.passQps());
}
// 进入到StatisticNode.passQps方法
public double passQps() {
// 获取qps的值,即当前时间窗中的通过的请求数/当前时间窗长度
return rollingCounterInSecond.pass() / rollingCounterInSecond.getWindowIntervalInSec();
}接下来我们需要关注的就是pass,这里就是从滑动时间窗中获取统计数据
public long pass() {
// 这个方法相信大家很熟悉,就是上面通过滑动时间窗算法增加数据时进行样本窗口数据更新的方法
data.currentWindow();
long pass = 0;
// 获取当前时间窗口中的所有样本窗口
List<MetricBucket> list = data.values();
// 将样本窗口中统计的多维数据中,状态为PASS的数据的总数量
for (MetricBucket window : list) {
pass += window.pass();
}
return pass;
}
// 我们通过跟进方法,跳过重载方法,来到以下方法,获取所有的有效样本窗口
public List<T> values(long timeMillis) {
if (timeMillis < 0) {
return new ArrayList<T>();
}
int size = array.length();
List<T> result = new ArrayList<T>(size);
// 遍历每一个样本窗口
for (int i = 0; i < size; i++) {
WindowWrap<T> windowWrap = array.get(i);
// 若当前数据为空,或者已经过时,则本条数据不处理
// 超时代表的是:当前时间节点-样本窗口的起始节点时间>时间窗口长度,代表不是同一个时间窗口
if (windowWrap == null || isWindowDeprecated(timeMillis, windowWrap)) {
continue;
}
result.add(windowWrap.value());
}
return result;
}