NLP入门教程系列
第二章 基于计数方法的改进版
前言
上章简单介绍了一下表示单词含义的方法,其中重点介绍了基于计数的方法,但是这个方法依旧存在问题,下面就来详细讲述一下其改进方法
一、点互信息
上一章说到,共现矩阵展示了两个单词同时出现的次数,但是这会存在问题。比如说同时出现的次数高,但是不一定意味着相关性强,比如大量the、a的出现,这些词并不具有实际的意义。所以接下来需要一个新的概念就叫点互信息(PMI):对于随机变量x,y
P M I ( x , y ) = l o g 2 P ( x , y ) P ( x ) P ( y ) PMI(x,y)= log_2\frac{P(x,y)}{P(x)P(y)} PMI(x,y)=log2P(x)P(y)P(x,y)
P代表事件发生概率,值越大,代表相关性越强。在NLP中,P(x)代表x在语料库中出现的的概率。现在我们现在使用上一章中的共现矩阵来改重写这个公式,共现矩阵记作C,单词共现次数记作C(x,y),x和y的出现次数记作C(x),C(y),语料库单词总数N,那么就有
P M I ( x , y ) = l o g 2 C ( x , y ) N C ( x ) n C ( y ) n = l o g 2 C ( x , y ) N C ( x ) C ( y ) PMI(x,y)= log_2\frac{\frac{C(x,y)}{N}}{\frac{C(x)}{n}\frac{C(y)}{n}}=log_2\frac{C(x,y)N}{C(x)C(y)} PMI(x,y)=log2nC(x)nC(y)NC(x,y)=log2C(x)C(y)C(x,y)N
举个例子,假设N=1000,the出现100次,car出现20次,drive出现10次,the和car共现10次,car和drive共现5次,
求得
PMI(“the”,“car”) = 2.32
PMI(“the”,“drive”) = 7.97
显然,car和drive相关性更高。不过PMI依旧存在问题,就是当单词共现次数为0的时候,log会变为负无穷,所以使用正点互信息(PPMI)
P P M I = m a x ( 0 , P M I ) PPMI = max(0,PMI) PPMI=max(0,PMI)
二、降维
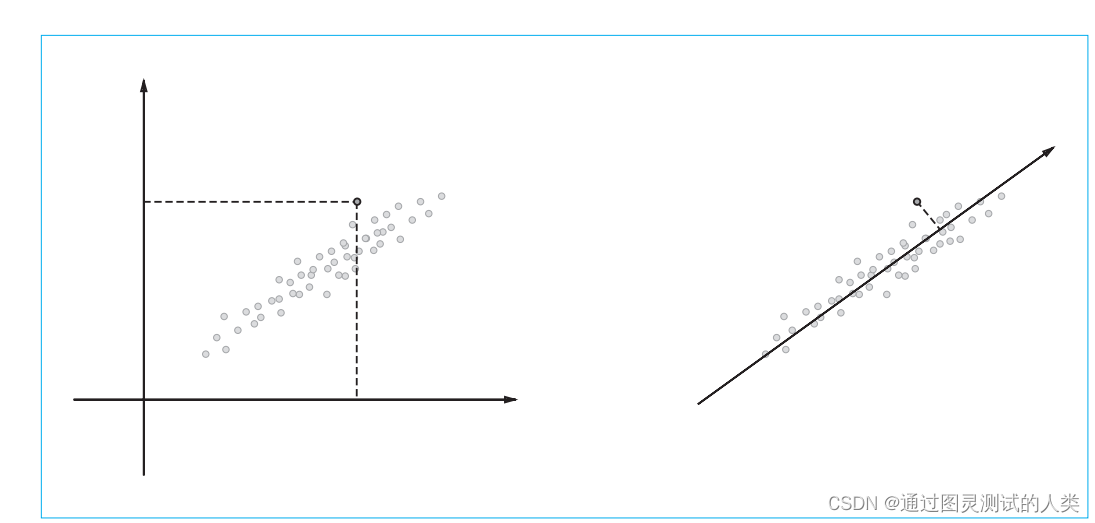
有了PPMI,可以方便地算出各个单词的关联性,但是也会出现的新的问题,当语料库越来越的时,点互信息矩阵也会越来越大,并且矩阵中会出现大量的0(稀疏矩阵),这样的矩阵不稳定,易受噪声干扰,所以接下来需要解决这个问题。降维的目的是,在尽量保留原始信息的基础上,尽可能减少维度。比如,将二维数据表示为一维数据,如下图所示
1.奇异值分解(SVD)
降维方法很对,这里介绍一下SVD,它将任意矩阵分解为三个矩阵乘积:
X = U S V T X=USV^T X=USVT
U、V为列向量正交的正交矩阵,S为除对角线以外其余元素均为0的对角矩阵。U 是正交矩阵。这个正交矩阵构成了一些空间中的基轴(基向量),我们可以将矩阵 U 作为“单词空间”。S 是对角矩阵,奇异值在对角线上降序排列。简单地说,我们可以将奇异值视为“对应的基轴”的重要性。这样一来,减少非重要元素就成为可能。具体实现在这里就不多写了,或者可以直接使用numpy包中linalg模块里的svd方法。
总结
以上就是本章要讲的内容,本文仅仅简单介绍了改进的方法以及降维,下面一章将会介绍基于推理的方法——word2vec