2023年4月7日,由中国DBA联盟(ACDU)和墨天轮社区联合主办的第十二届『数据技术嘉年华』(DTC 2023) 在北京新云南皇冠假日酒店盛大开启。HashData资深解决方案架构师李俊在4月8号专题会场6-“融合应用:湖仓技术创新”上发表了《基于HashData的湖仓一体解决方案的探索与实践》的专题演讲。
本文根据演讲实录整理而成,演讲正文如下(全文阅读需要20分钟以上):

一、湖仓一体的演进

数据仓库的概念是比尔·恩门(Bill Inmon)在1991年出版的《Building the Data Warehouse》一书正式提出后被广泛接受。经过30年发展,在金融、通信、航空等各行各业都是有广泛应用。
数据仓库具有便于BI和报表系统接入,数据管控能力强的优势,但是随着大数据的兴起,表现出不支持非结构化数据、专有系统成本高,专有数据格式、灵活度低的劣势。
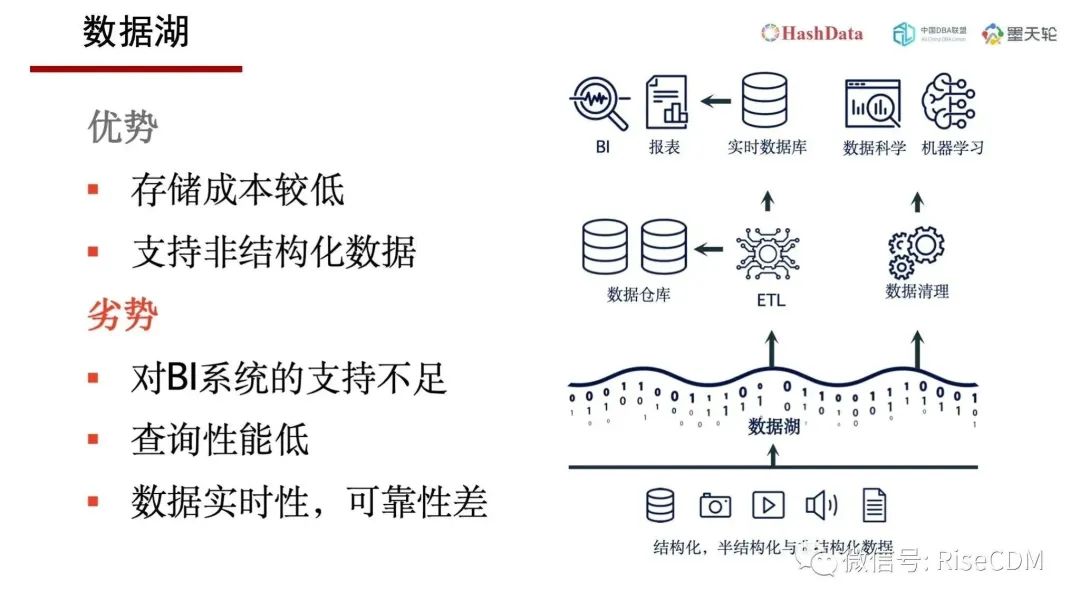
数据湖的概念兴起于大数据的出现,是在2010年左右,它具备存储成本较低、支持非结构化数据。数据湖一度被认为会取代数据仓库,但是随着数据湖投入实际应用中,人们逐步发现到它的一些劣势:对BI系统的支持不足、查询性能低、数据交互不实时、可靠性差等问题。
在数据湖与数据仓库之间学术界、工业界发生过激烈的争辩,最后基本达成共识:数据仓库与数据湖就像苹果与橙子,它们是完全不同的东西,不会相互取代。

数据仓库和数据湖不会相互取代,它们会共存,共同组成企业的数据平台。Gartner提出的逻辑数据仓库概念就包括了数据仓库和数据湖两个部分,这也是目前大多数企业的一个现状。
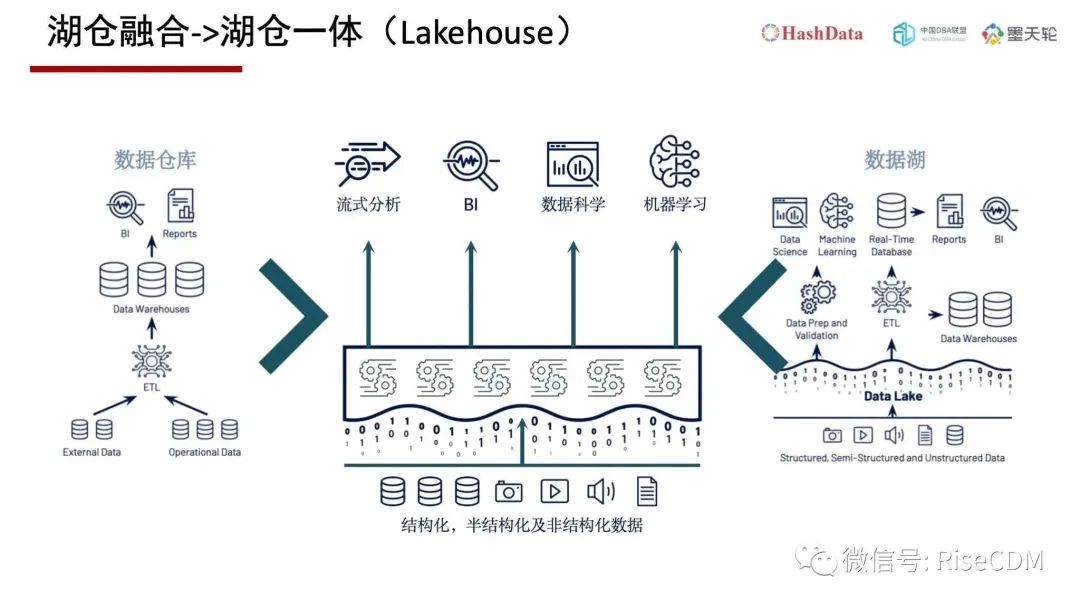
但是创新者并不满足于现状,在2020年左右由Databrick公司率先提出了Lakehouse的概念,在国内翻译成湖仓一体或者湖仓。
不难看出Lakehouse是前一半来源Data Lake,后一半是来源Data Warehouse。它的寓意是Lakehouse吸收数据湖和数据仓库的优势,创建一个新的平台。
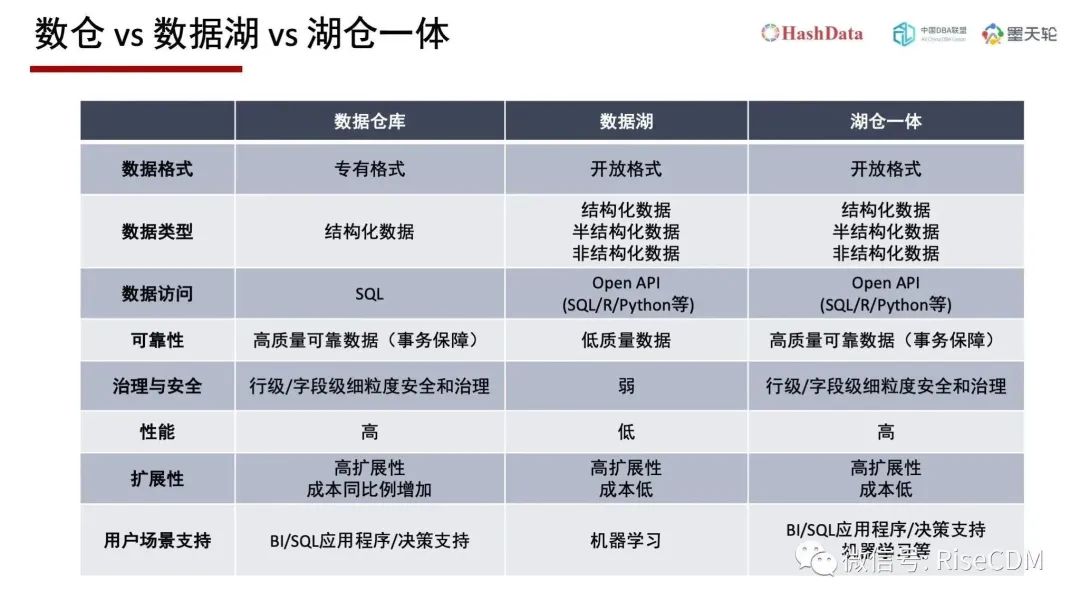
湖仓一体(Lakehouse)分别在数据格式、数据类型、数据访问、可靠性、治理与安全、性能、扩展性、用户场景支持提出新要求。
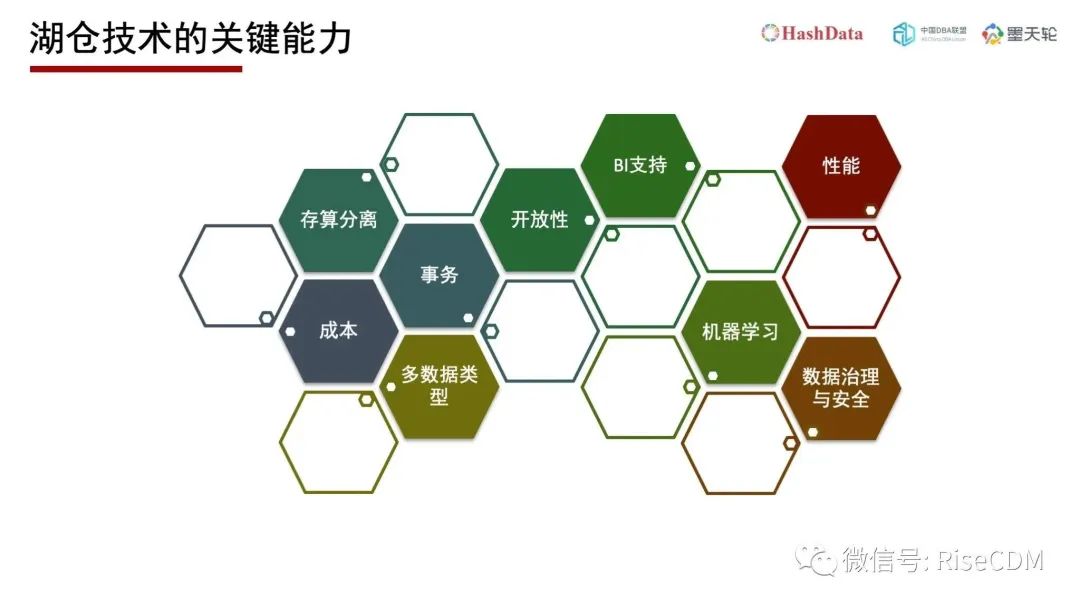
为了满足上述的新要求,湖仓一体(Lakehouse)必须具备如下的关键能力。
-
存算分离
数据湖需要提升的关键能力:
-
事务
-
BI支持
-
性能
-
数据治理与安全
数据仓库需要提升的关键能力:
-
多数据类型
-
机器学习
-
成本
二、国外湖仓技术发展简介

提到国外的湖仓技术,人们讨论最多的Databrick、Hudi、Iceberg这三家开源解决方案。Databrick家解决方案是DeltaLake,我有幸参加过DeltaLake的产品培训和试用,确实具备了事务、BI支持、性能等方面的关键能力,体验很好。
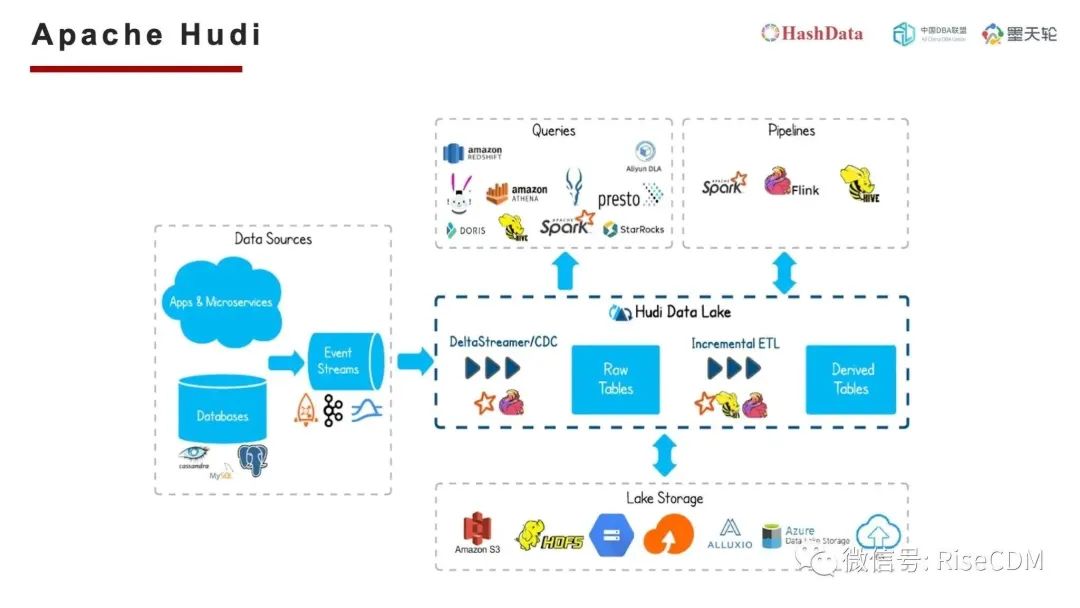
Apache Hudi是DeltaLake的竞争对手。

Apache Iceberg是DeltaLake的另一个竞争对手。正是由于开源Hudi、Iceberg快速的发展,逼迫DeltaLake由商用改为开源。
谈到Iceberg,我们需要重点介绍一个概念:Table Format(数据表格格式),Table Format是抽象层,帮助计算引擎处理底层的存储格式(ORC、Parquet等),而不是像以前那样需要直接操作底层存储。这个概念很重要,在后面的技术分享会用到。
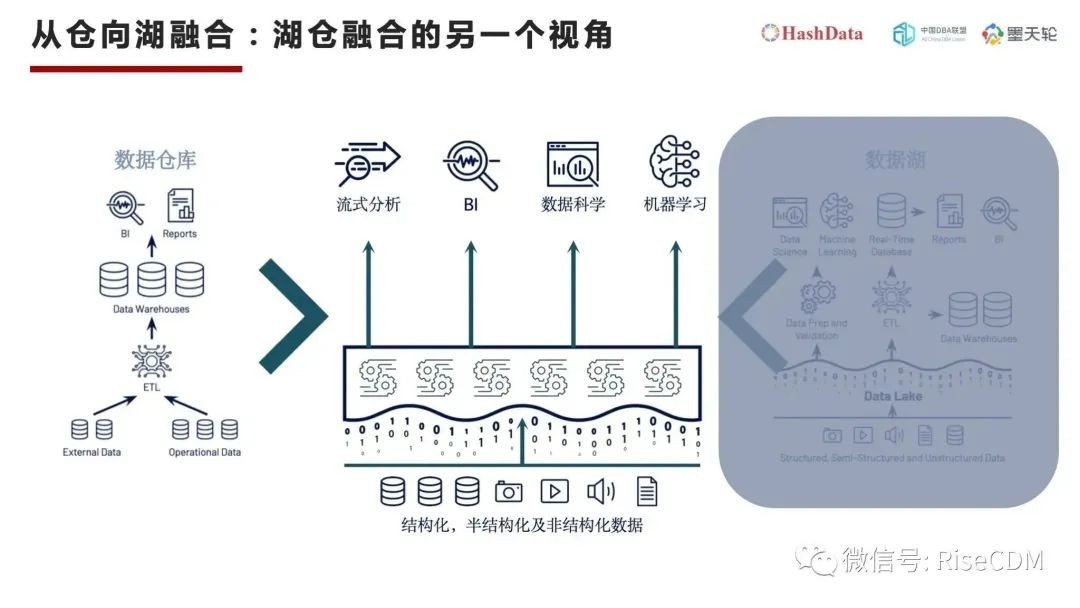
上面提到Apahce DeltaLake/Apache Hudi/Apache Icerberg三种开源解决方案都是数据湖向数据仓库融合的技术路线,HashData作为一个数据仓库解决方案将向大家展开一个数据仓库向数据湖融合的新视角。
三、HashData创新与探索实践
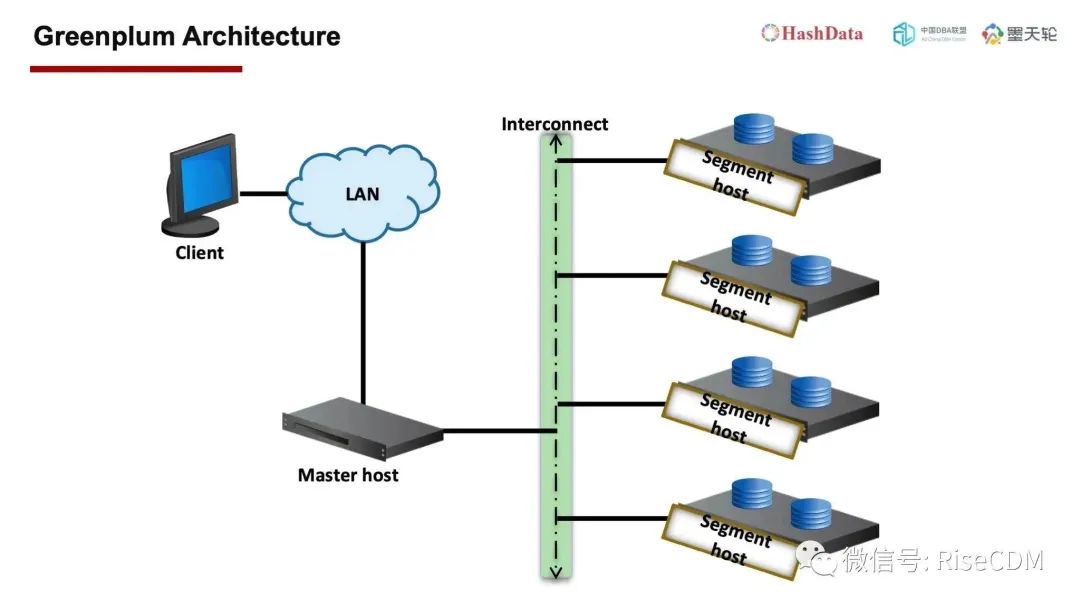
HashData最初的产品原型是基于Greenplum,它是一个典型的MPP架构,但是它是存算耦合的,即数据存储、数据计算都在一个数据节点。

经过面向云原生的反复迭代设计后,HashData v3的架构是这样的。它是一个服务、计算、存储三者分离的架构,有效解决了传统MPP的木桶效应问题,使得HashData数据仓库具备支持超大规模的集群能力。

HashData目前已经成功应用于C行的超大规模数据仓库服务,截止2022年底,目前在生产中已经有2万多个数据节点 在运行,数据存储约13PB左右。

数据仓库向数据湖融合另一挑战是如何提供低成本解决方案?来自华为云官网的数据显示,对象存储的成本仅仅只有磁盘、SSD的价格的几十分之一。如果把所有的数据全部存储在对象存储中,整体解决方案将大幅降低。不幸的是对象存储的IO不太好,这样会牺牲性能。在价格和性能中间,我们采用多级存储技术:持久化数据存储在对象存储中,在计算层增加热点缓存技术,很好的解决了这个问题。

采用了对象存储的HashData数据湖解决方案整体成本可以降低到原来的1/10,但通过热点缓存技术保证了性能。相关Benchmark数据报告表明,性能非常接近原来的水平。
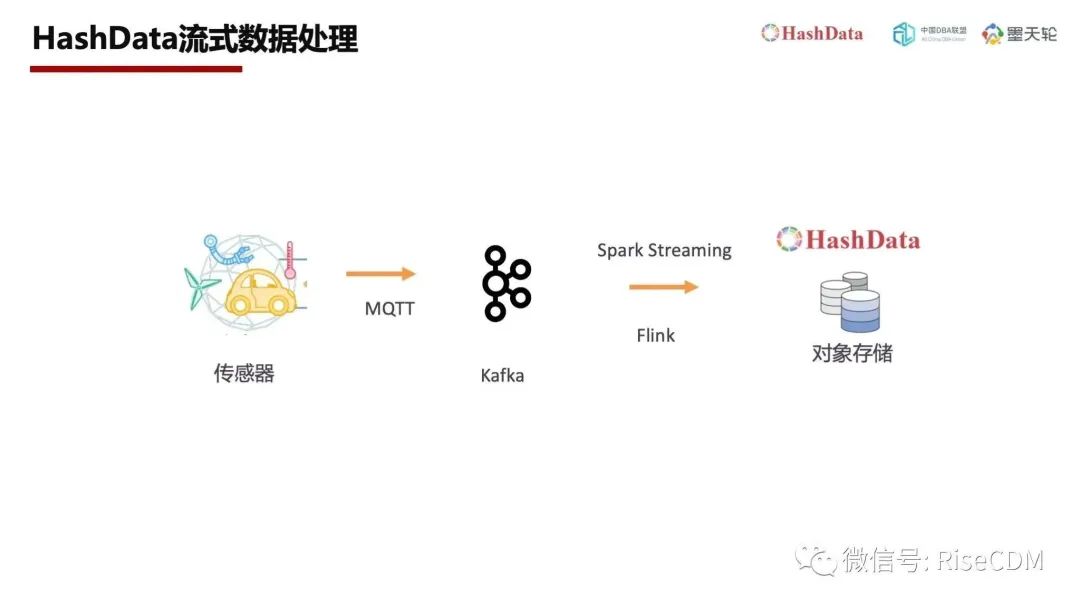
对于机器产生的数据比如IoT数据,HashData支持流式计算引擎准实时写入,从而提高数据分析的实效性。

在A能源集团案例中,统一数据湖已经存储油藏、地质、勘探、生产等数据1.7PB,当然也有上面提到的机器设备产生的流式数据。

对于半结构化数据,现在基本上数据库都有很好的支持,这是不重复说明了。重点在于非结构化数据,数据库其实可以以二进制方式存储图片等,但使用起来比较麻烦,这不是一个好的解决方法。
对于非结构化分析,目前我们给出的解决方案是分两部分:
-
原始文件存储在对象存储中。
-
解析出来的结构化数据存储于数据库中,便于检索比对。

下面以高速公路的卡口数据分析案例进一步说明。摄像头抓拍车牌信息后,将原始照片存储到对象存储,以做原始证据。解析出来的车牌号、颜色、时间存放到HashData数据库,以支持流量统计监测、逃费稽核等应用。
-

-
对于机器学习,HashData支持SQL方式调用函数在库内进行机器学习,现在新增支持更开放的Python的原生支持。综上,HashData湖仓一体解决方案是一个以服务、计算、存储三者分离的技术架构为基石,面向多种场景,包括数据仓库、数据湖,也包括数据要素市场等场景的解决方案。
四、湖仓融合的思考与展望
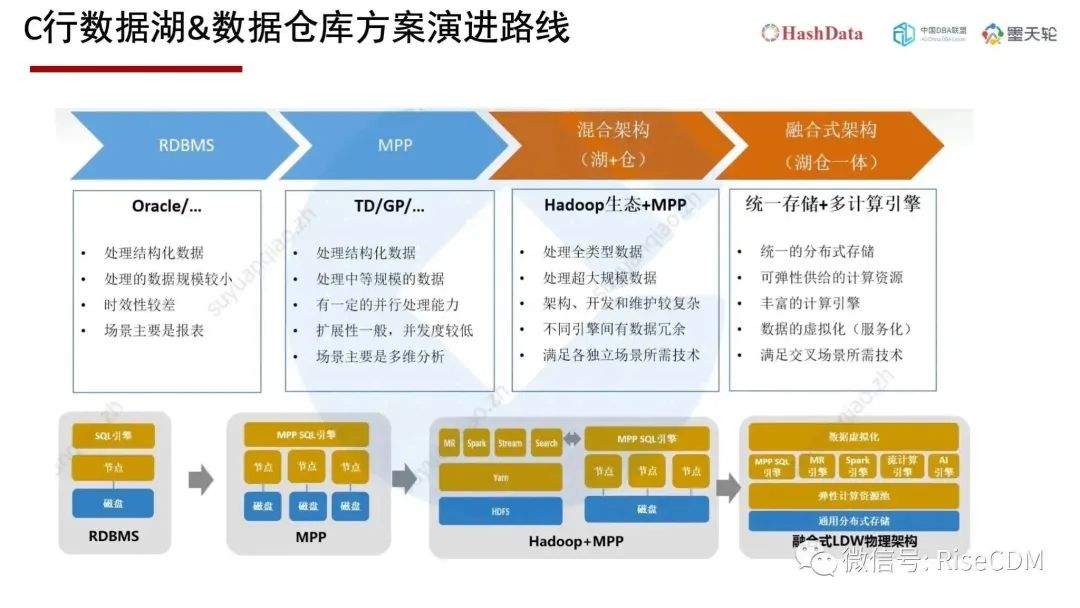
湖仓融合后的会形成一个统一存储+多计算引擎的格局。对于数据格式的融合,HashData后续会引入Iceberg作为TableFormat。

今天分享的更多的技术平台融合,更多模型、数据治理、数据资产管理方面的湖仓一体专题请参考以上两本杂志。