一、linux命名空间和docker
1.linux的7大ns--------------ipc,net,pid,mnt.uts.user


查看linux的ns
lsns
查看不同类型的ns
[root@master ~]# lsns -t net
NS TYPE NPROCS PID USER COMMAND
4026531956 net 116 1 root /usr/lib/systemd/systemd --system --deserialize 26查看某个ns的pid的并进入
ls -la /proc/1/ns容器内没有命令,通过主机查看容器内nsenter -t pid
步骤1.docker ps|grep nginx
步骤2docker inspect name |grep pid
步骤3:nsenter -t pid(pid号) -n ip a---------n别掉了,不认就变成知己的ip a了
nsenter -t 1 -n ip a

2.docker本身用****cgroupfs****作为cgroup driver这是内网一套cgroup系统 ,而kubelet的cgrop系统是*****systemd****
kubelet为了保护,启动时候会检查cgroup driver,一般把docker的都改成systemd,然后reload
3,,docker优势和与containerd的差异
docker的创新点在于联合文件系统,最大的优势在于打包镜像,打报镜像自带环境,可移植----------------上下文构建
docker和containerd的主要差异,docker加上一个shim连接上crid,原因是以前docker升级会杀进程,但是cridb不会,所以现在docker 通过shim连接crid

多段构建镜像


4. 网络Overlay(加一层打包--常用---隧道模式---加一层--封包解包)和underlay(重新规划pods节点的网络---物理机的网络---不常用---)
同一node的pod的连接方式
1.NULL模式----自己配---不常用
2.默认模式--网桥和NAT----pod分别和主机形成veth--pair,docker网桥和容器网络
docker run -d --name nginx01 -p 3344:80 nginxb暴露端的原理是iptable的规则改写
查看iptables的规则,如果是tcp协议,添加规则,目标端口是 3344会做一个DNAT(分发)
[root@master ~]# iptables-save -t nat |grep 3344
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 3344 -j DNAT --to-destination 172.17.0.2:80二、k8s调度策略
Borg调度策略:Worst Fit(资源空闲最多的地方,放上去,所有节点的资源占用率差不多)
Best Fit(刚好满足的放上去,节省资源,成本,尽量填满节点,减少集群碎片)
Hybrid(找到局部最优放进去,而不是遍历所有节点)
1.k8s打开DEBUG模式的方法:
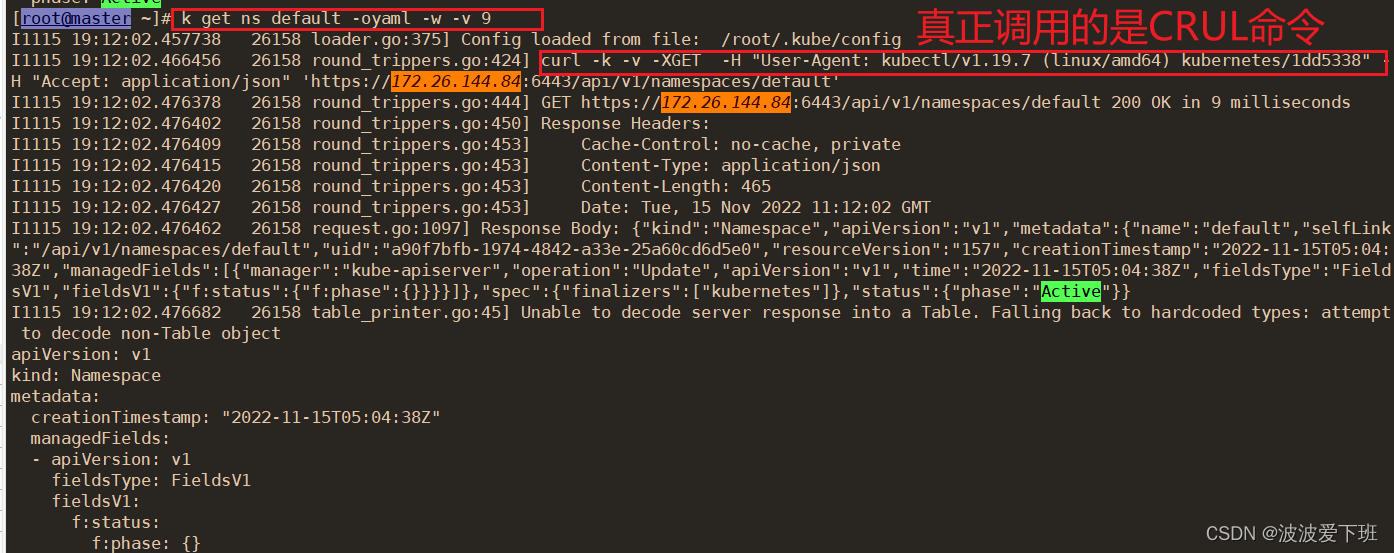
k get ns default -v 9kubectl的本质是对rest api的封装,CURL命令
不要去api-server取东西,要去缓存取东西
[root@master module4]# k get ns default -v 9
I1115 18:55:49.139247 12707 loader.go:375] Config loaded from file: /root/.kube/config
I1115 18:55:49.148958 12707 round_trippers.go:424] curl -k -v -XGET -H "Accept: application/json;as=Table;v=v1;g=meta.k8s.io,application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json" -H "User-Agent: kubectl/v1.19.7 (linux/amd64) kubernetes/1dd5338" 'https://172.26.144.84:6443/api/v1/namespaces/default'
cat /root/.kube/config
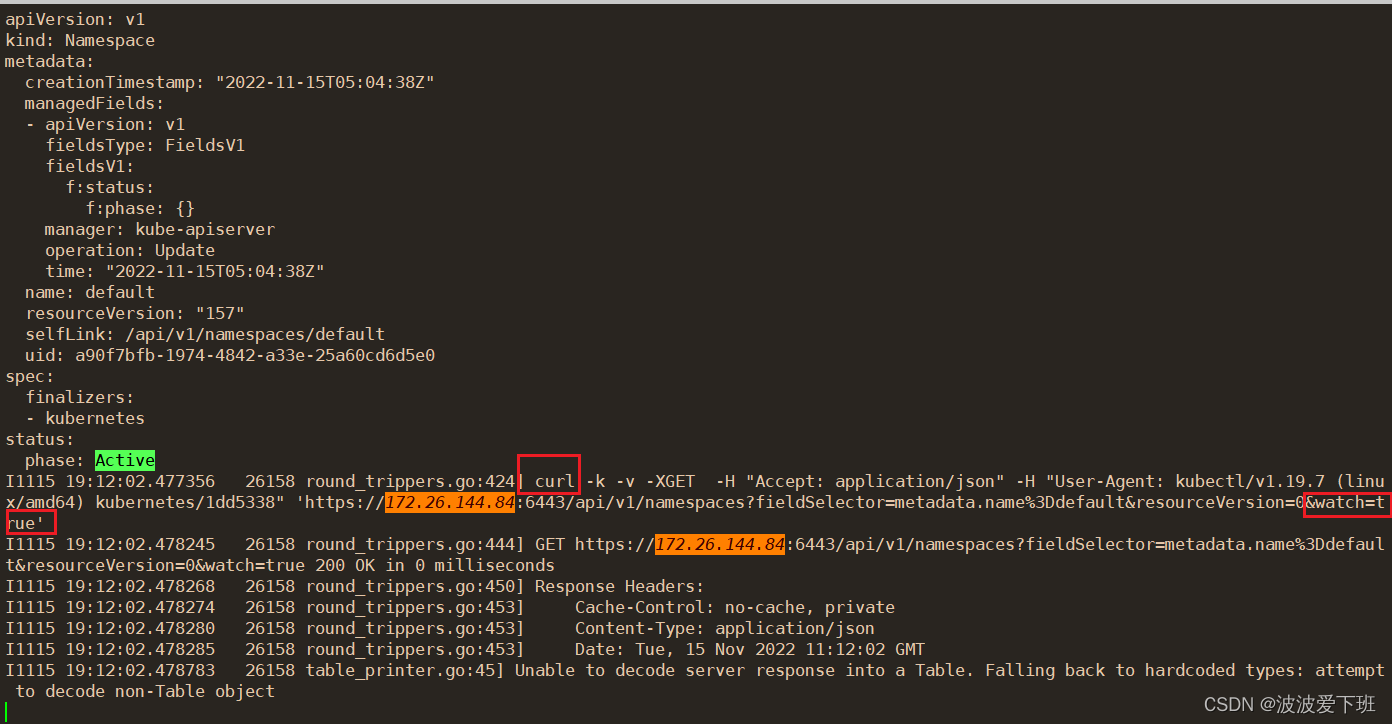 此时在左侧更新ns右侧可以监听到
此时在左侧更新ns右侧可以监听到

查看crid runtime,默认值是k8s1.24版本以前是docker
[root@master ~]# cat /var/lib/kubelet/config.yaml |grep runtime
kubeReservedCgroup: /podruntime.slice
runtimeRequestTimeout: 2m0s
三、ETCD
etcd是基于raft协议的分布式k-v数据库
键值存储
服务发现与注册
监听机制--异步系统
理解raft一致性算法Raft,一段时间没有领导后,自己会变成候选人,发出消息,造反成功,一直告诉别人我是你的头
新加节点learner只学习不投票
etcd是k-v所以智勇多key做索引就可以
etcd和主机放在一起,读的效率会很高,加一个独立的挂载盘SSD----一定要全是SSD,不然分裂
etcd的reversion的modified版本号,每修改一次就会整体更新,两个都是最新的版本号才会让过
ETcd的数据确认也是超过半数可以确认
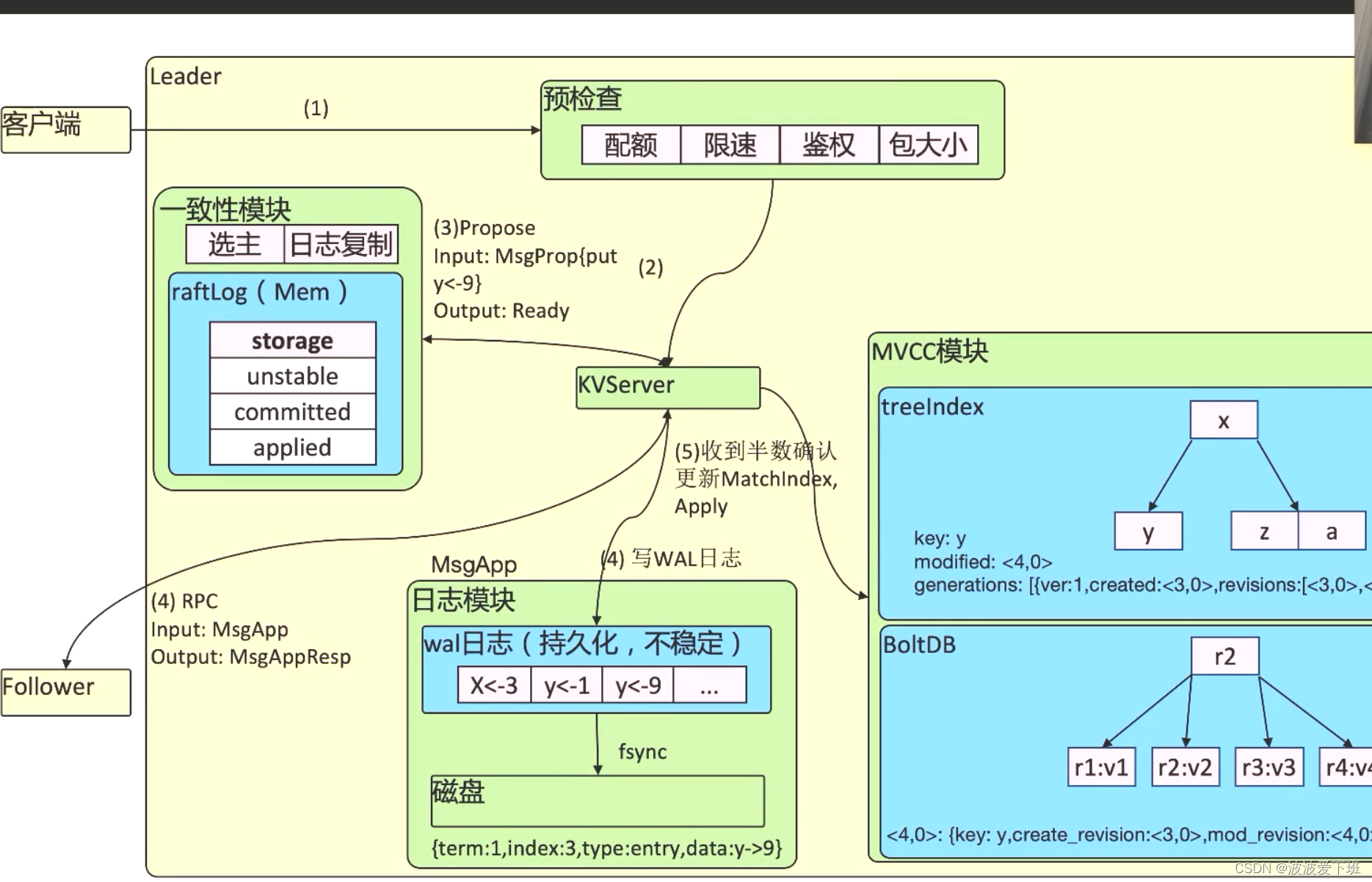
ETCD备份时,snapshot会加锁,所以要合理规划备份时间,拉出来VAR/LOG,先恢复snapshot,在加载、var/log数据

四、api-server
api-server相当于api网关
拥有认证、鉴权、准入策略、限流、
插件前面可以修改,后面不能修改
一般webhook作为apiserver的sidecar一起跑



五、docker切换成crd
101/docker2containerd.md at master · cncamp/101 · GitHub
启动顺序:CSI-->>CRI-->>CNI
六、网络插件
Flannel-------VXLAN模式,封包解包、本身资源开销子10%左右------没有生态
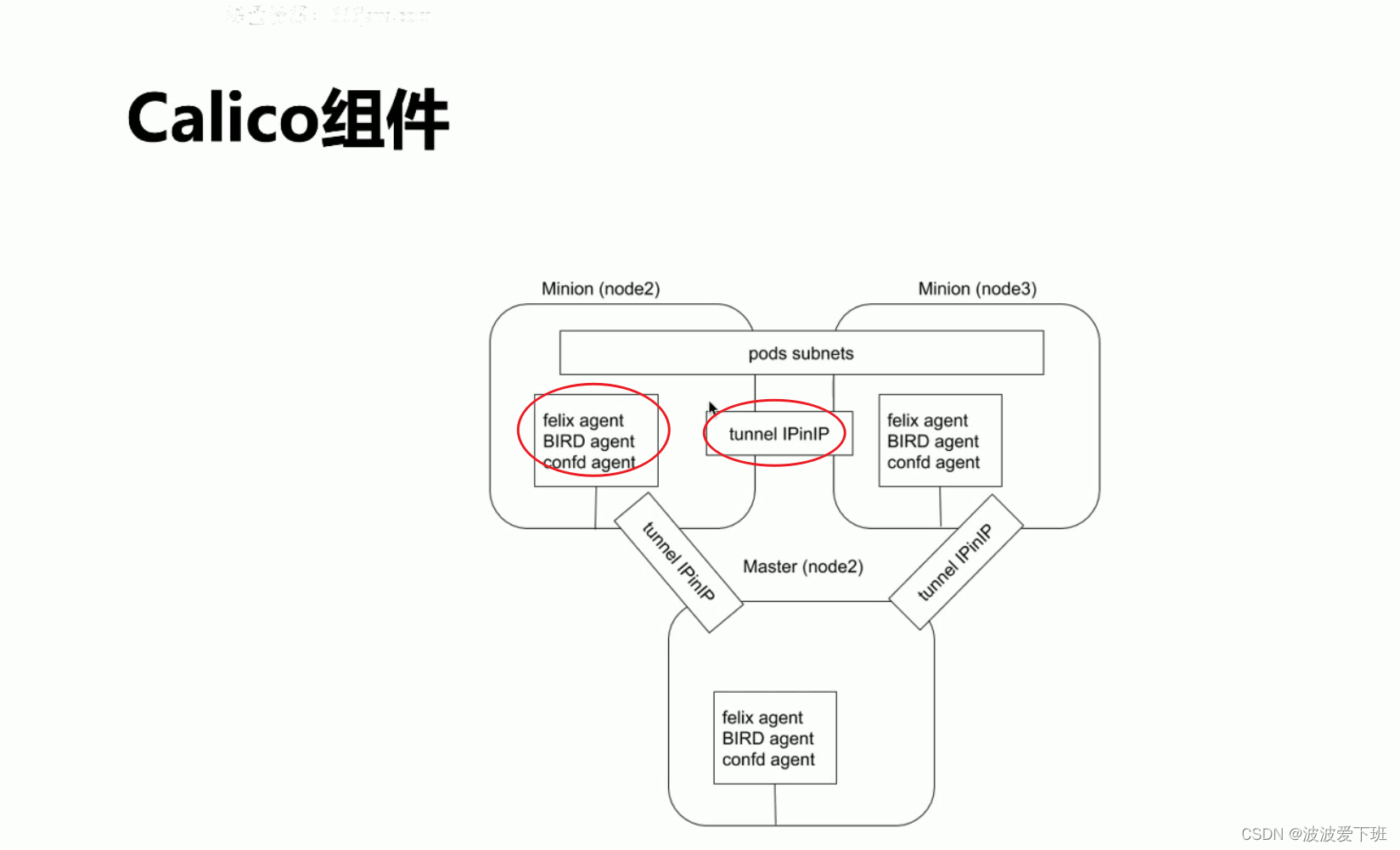
calico------------同网段3层、BGP协议(互相通知)、无需封包解包---------跨主机网段tunl0模式(隧道---IPIP----IP包后面再加IP包---------vxlan加UDP的包)
calico-----动态路由模式
七、pod的状态计算细节

八、查看iptables规则
进来出去的都去KUBE-SERVICES走一波
-d代表destition(目的地址)
iptables-save -t nat[root@master ~]# iptables-save -t nat |grep -i ser
:KUBE-SERVICES - [0:0]
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE
-A KUBE-SERVICES ! -s 172.20.0.0/16 -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP dst,dst -j KUBE-MARK-MASQ
-A KUBE-SERVICES -m addrtype --dst-type LOCAL -j KUBE-NODE-PORT
-A KUBE-SERVICES -m set --match-set KUBE-CLUSTER-IP dst,dst -j ACCEPT
策略是想撞第一个,没撞到就第二个,还没有就第三个百分百兜底
小规模集群问题不大
iptables链路规则太多转发效率会超级低,就算优化,首包的效率也非常低
iptables是全量刷新的
ipvs在postrouting做SNAT

ipvs启用的时候会起来一个ipvs0的虚拟网卡,防止不是本机的数据包被丢失
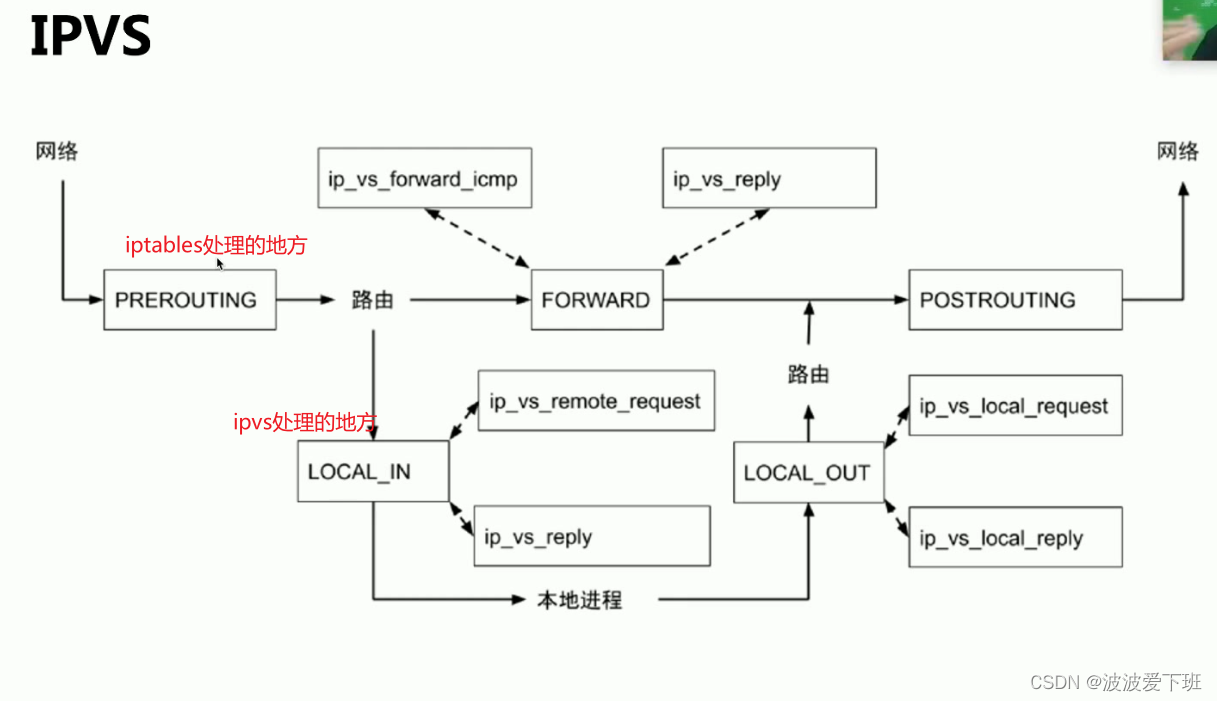
在prerouting和postrouting的地方,ipvs是没有hook点的,出栈的伪装(postrouting处)还是要依靠iptables,所以在ipvs下iptables的nat规则会比较少

ipvsadm -L