目录
Swin Trasnformer
1. 模型介绍
Swin Transformer是由微软亚洲研究院在今年公布的一篇利用transformer架构处理计算机视觉任务的论文。Swin Transformer 在图像分类,图像分割,目标检测等各个领域已经屠榜,在论文中,作者分析表明,Transformer从NLP迁移到CV上没有大放异彩主要有两点原因:1. 两个领域涉及的scale不同,NLP的token是标准固定的大小,而CV的特征尺度变化范围非常大。2. CV比起NLP需要更大的分辨率,而且CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:1.引入CNN中常用的层次化构建方式构建层次化Transformer 2.引入locality思想,对无重合的window区域内进行self-attention计算。另外,Swin Transformer可以作为图像分类、目标检测和语义分割等任务的通用骨干网络,可以说,Swin Transformer可能是CNN的完美替代方案。
2. 模型结构
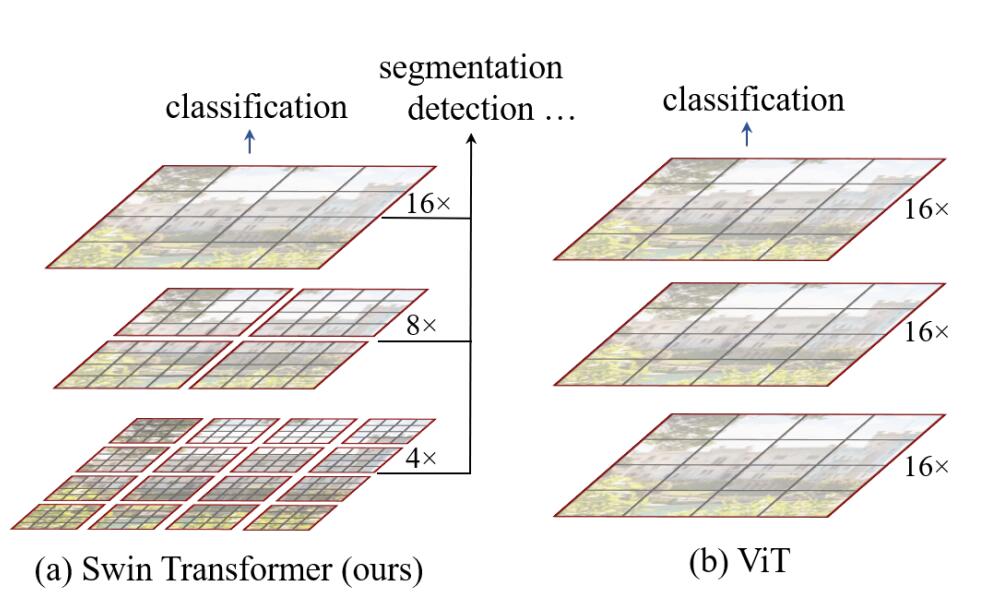
下图为Swin Transformer与ViT在处理图片方式上的对比,可以看出,Swin Transformer有着ResNet一样的残差结构和CNN具有的多尺度图片结构。
整体概括:
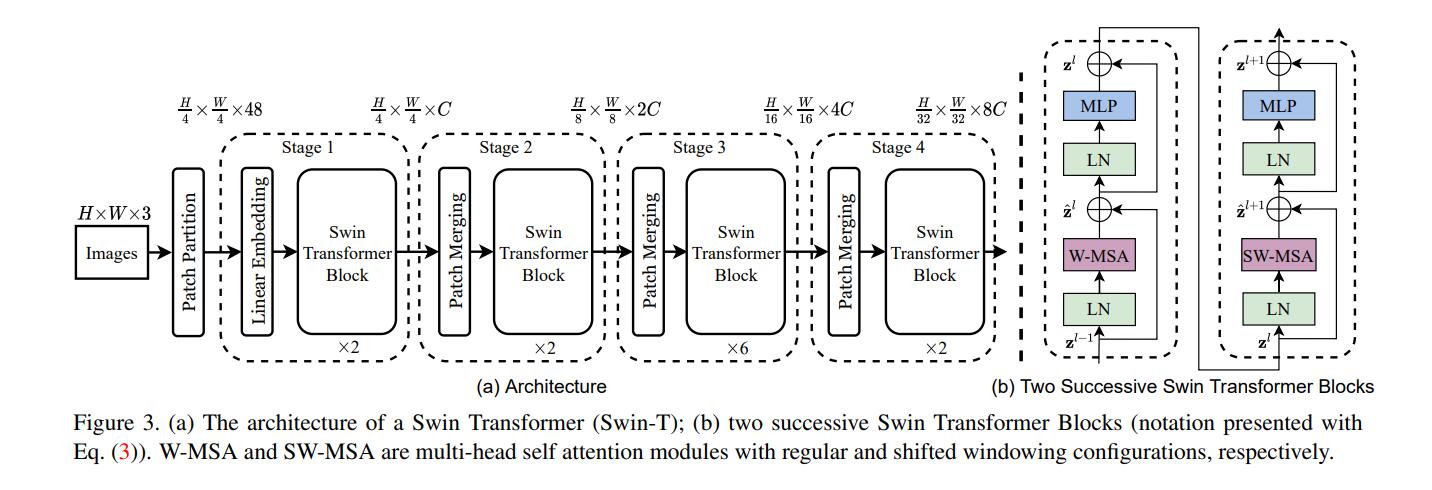
下图为Swin Transformer的网络结构,输入的图像先经过一层卷积进行patch映射,将图像先分割成4 × 4的小块,图片是224×224输入,那么就是56个path块,如果是384×384的尺寸,则是96个path块。这里以224 × 224的输入为例,输入图像经过这一步操作,每个patch的特征维度为4x4x3=48的特征图。因此,输入的图像变成了H/4×W/4×48的特征图。然后,特征图开始输入到stage1,stage1中linear embedding将path特征维度变成C,因此变成了H/4×W/4×C。然后送入Swin Transformer Block,在进入stage2前,接下来先通过Patch Merging操作,Patch Merging和CNN中stride=2的1×1卷积十分相似,Patch Merging在每个Stage开始前做降采样,用于缩小分辨率,调整通道数,当H/4×W/4×C的特征图输送到Patch Merging,将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C,之后经过一个MLP,将特征维度降为2C。因此变为H/8×W/8×2C。接下来的stage就是重复上面的过程。
每步细说:
Linear embedding
下面用Paddle代码逐步讲解Swin Transformer的架构。 以下代码为Linear embedding的操作,整个操作可以看作一个patch大小的卷积核和patch大小的步长的卷积对输入的B,C,H,W的图片进行卷积,得到的自然就是大小为 B,C,H/patch,W/patch的特征图,如果放在第一个Linear embedding中,得到的特征图就为 B,96,56,56的大小。Paddle核心代码如下。
class PatchEmbed(nn.Layer):
""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Layer, optional): Normalization layer. Default: None
"""
def __init__(self,
img_size=224,
patch_size=4,
in_chans=3,
embed_dim=96,
norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [
img_size[0] // patch_size[0], img_size[1] // patch_size[1]
]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1] #patch个数
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2D(
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) #将stride和kernel_size设置为patch_size大小
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x) # B, 96, H/4, W4
x = x.flatten(2).transpose([0, 2, 1]) # B Ph*Pw 96
if self.norm is not None:
x = self.norm(x)
return xPatch Merging
以下为PatchMerging的操作。该操作以2为步长,对输入的图片进行采样,总共得到4张下采样的特征图,H和W降低2倍,因此,通道级拼接后得到的是B,4C,H/2,W/2的特征图。然而这样的拼接不能够提取有用的特征信息,于是,一个线性层将4C的通道筛选为2C, 特征图变为了B,2C, H/2, W/2。细细体会可以发现,该操作像极了 卷积常用的Pooling操作和步长为2的卷积操作。Poling用于下采样,步长为2的卷积同样可以下采样,另外还起到了特征筛选的效果。总结一下,经过这个操作原本B,C,H,W的特征图就变为了B,2C,H/2,W/2的特征图,完成了下采样操作。
class PatchMerging(nn.Layer):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, "x size ({}*{}) are not even.".format(
H, W)
x = x.reshape([B, H, W, C])
# 每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
# 拼接在一起作为一整个张量,展开。通道维度会变成原先的4倍(因为H,W各缩小2倍)
x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.reshape([B, H * W // 4, 4 * C]) # B H/2*W/2 4*C
x = self.norm(x)
# 通过一个全连接层再调整通道维度为原来的两倍
x = self.reduction(x)
return xSwin Transformer Block:
下面的操作是根据window_size划分特征图的操作和还原的操作,原理很简单就是并排划分即可。
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.reshape([B, H // window_size, window_size, W // window_size, window_size, C])
windows = x.transpose([0, 1, 3, 2, 4, 5]).reshape([-1, window_size, window_size, C])
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.reshape([B, H // window_size, W // window_size, window_size, window_size, -1])
x = x.transpose([0, 1, 3, 2, 4, 5]).reshape([B, H, W, -1])
return xSwin Transformer中重要的当然是Swin Transformer Block了,下面解释一下Swin Transformer Block的原理。 先看一下MLP和LN,MLP和LN为多层感知机和相对于BatchNorm的LayerNorm。原理较为简单,因此直接看paddle代码即可。
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x下图就是Shifted Window based MSA是Swin Transformer的核心部分。Shifted Window based MSA包括了两部分,一个是W-MSA(窗口多头注意力),另一个就是SW-MSA(移位窗口多头自注意力)。这两个是一同出现的。
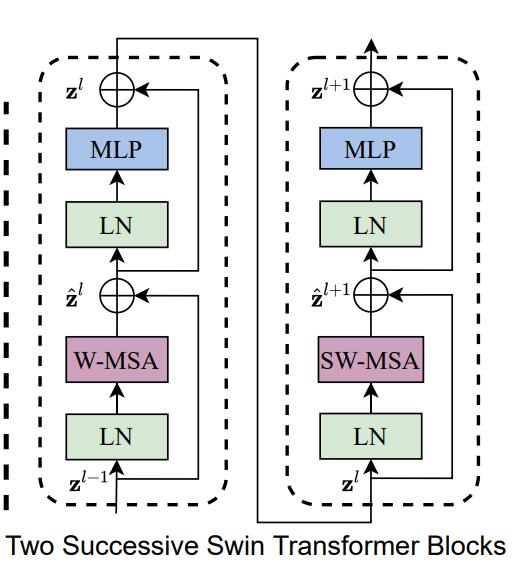
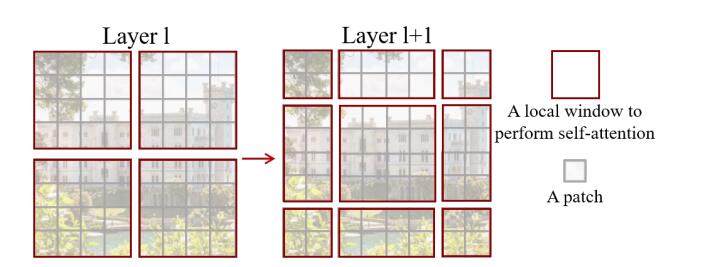
一开始,Swin Transformer 将一张图片分割为4份,也叫4个Window,然后独立地计算每一部分的MSA。由于每一个Window都是独立的,缺少了信息之间的交流,因此作者又提出了SW-MSA的算法,即采用规则的移动窗口的方法。通过不同窗口的交互,来达到特征的信息交流。注意,这一部分是本论文的精华,想要了解的同学必须要看懂源代码
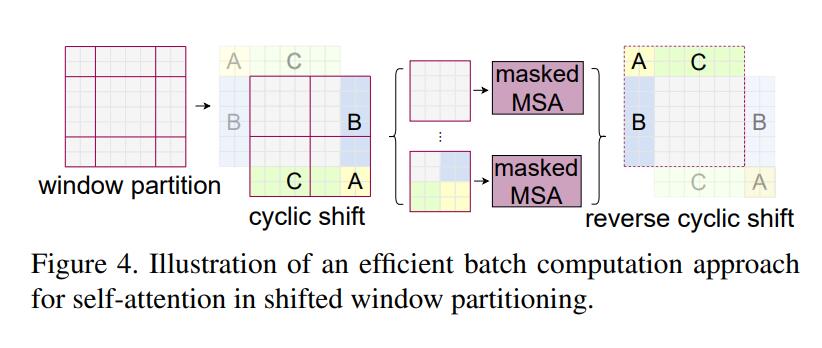
3. 模型实现
Swin Transformer涉及模型代码较多,所以建议完整的看Swin Transformer的代码.
4. 模型特点
-
首次在cv领域的transformer模型中采用了分层结构。分层结构因为其不同大小的尺度,使不同层特征有了更加不同的意义,较浅层的特征具有大尺度和细节信息,较深层的特征具有小尺度和物体的整体轮廓信息,在图像分类领域,深层特征具有更加有用的作用,只需要根据这个信息判定物体的类别即可,但是在像素级的分割和检测任务中,则需要更为精细的细节信息,因此,分层结构的模型往往更适用于分割和检测这样的像素级要求的任务中。Swin Transformer 模仿ResNet采取了分层的结构,使其成为了cv领域的通用框架。
-
引入locality思想,对无重合的window区域内进行self-attention计算。不仅减少了计算量,而且多了不同窗口之间的交互。
5. 模型效果
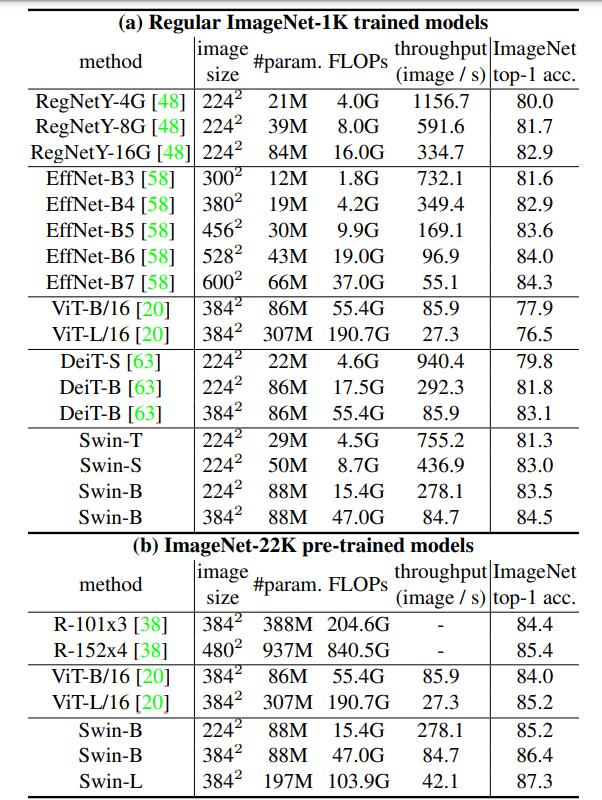
第一列为对比的方法,第二列为图片尺寸的大小(尺寸越大浮点运算量越大),第三列为参数量,第四列为浮点运算量,第五列为模型吞吐量。可以看出,Swin-T 在top1准确率上超过了大部分模型EffNet-B3确实是个优秀的网络,在参数量和FLOPs都比Swin-T少的情况下,略优于Swin-T,然而,基于ImageNet1K数据集,Swin-B在这些模型上取得了最优的效果。另外,Swin-L在ImageNet-22K上的top1准确率达到了87.3%的高度,这是以往的模型都没有达到的。并且Swin Transformer的其他配置也取得了优秀的成绩。图中不同配置的Swin Transformer解释如下。

C就是上面提到的类似于通道数的值,layer numbers就是Swin Transformer Block的数量了。这两个都是值越大,效果越好。和ResNet十分相似。
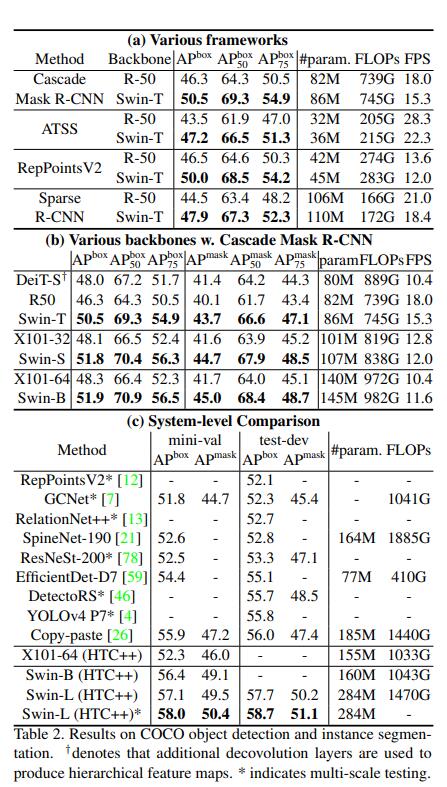
下图为COCO数据集上目标检测与实例分割的表现。都是相同网络在不同骨干网络下的对比。可以看出在不同AP下,Swin Transformer都有大约5%的提升,这已经是很优秀的水平了。怪不得能成为ICCV2021最佳paer。
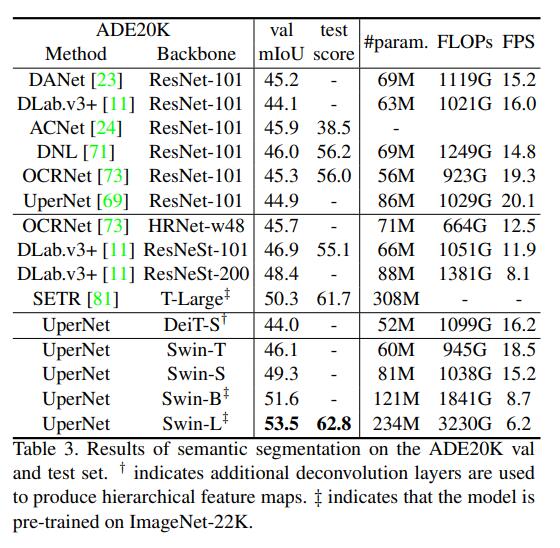
下图为语义分割数据集ADE20K上的表现。相较于同为transformer的DeiT-S, Swin Transformer-S有了5%的性能提升。相较于ResNeSt-200,Swin Transformer-L也有5%的提升。另外可以看到,在UNet的框架下,Swin Transformer的各个版本都有十分优秀的成绩,这充分说明了Swin Transformer是CV领域的通用骨干网络。
ViT( Vision Transformer)
模型介绍
在计算机视觉领域中,多数算法都是保持CNN整体结构不变,在CNN中增加attention模块或者使用attention模块替换CNN中的某些部分。有研究者提出,没有必要总是依赖于CNN。因此,作者提出ViT[1]算法,仅仅使用Transformer结构也能够在图像分类任务中表现很好。
受到NLP领域中Transformer成功应用的启发,ViT算法中尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法中,会将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。
该算法在中等规模(例如ImageNet)以及大规模(例如ImageNet-21K、JFT-300M)数据集上进行了实验验证,发现:
-
Transformer相较于CNN结构,缺少一定的平移不变性和局部感知性,因此在数据量不充分时,很难达到同等的效果。具体表现为使用中等规模的ImageNet训练的Transformer会比ResNet在精度上低几个百分点。
-
当有大量的训练样本时,结果则会发生改变。使用大规模数据集进行预训练后,再使用迁移学习的方式应用到其他数据集上,可以达到或超越当前的SOTA水平。
模型结构与实现
ViT算法的整体结构如 图1 所示。
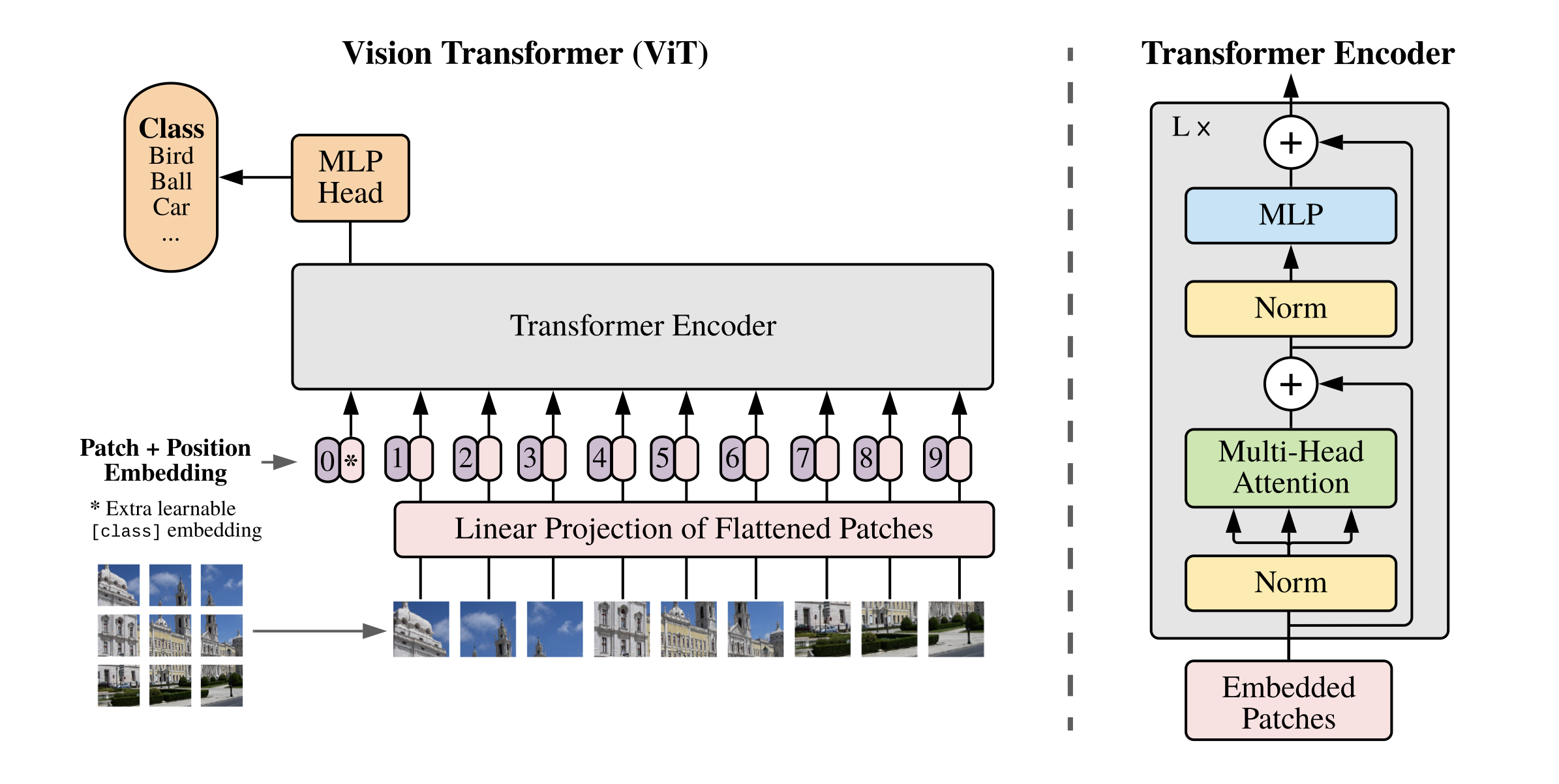
图1 ViT算法结构示意图
1. 图像分块嵌入

上述对图像进行分块以及 Embedding 的具体方式如 图2 所示。
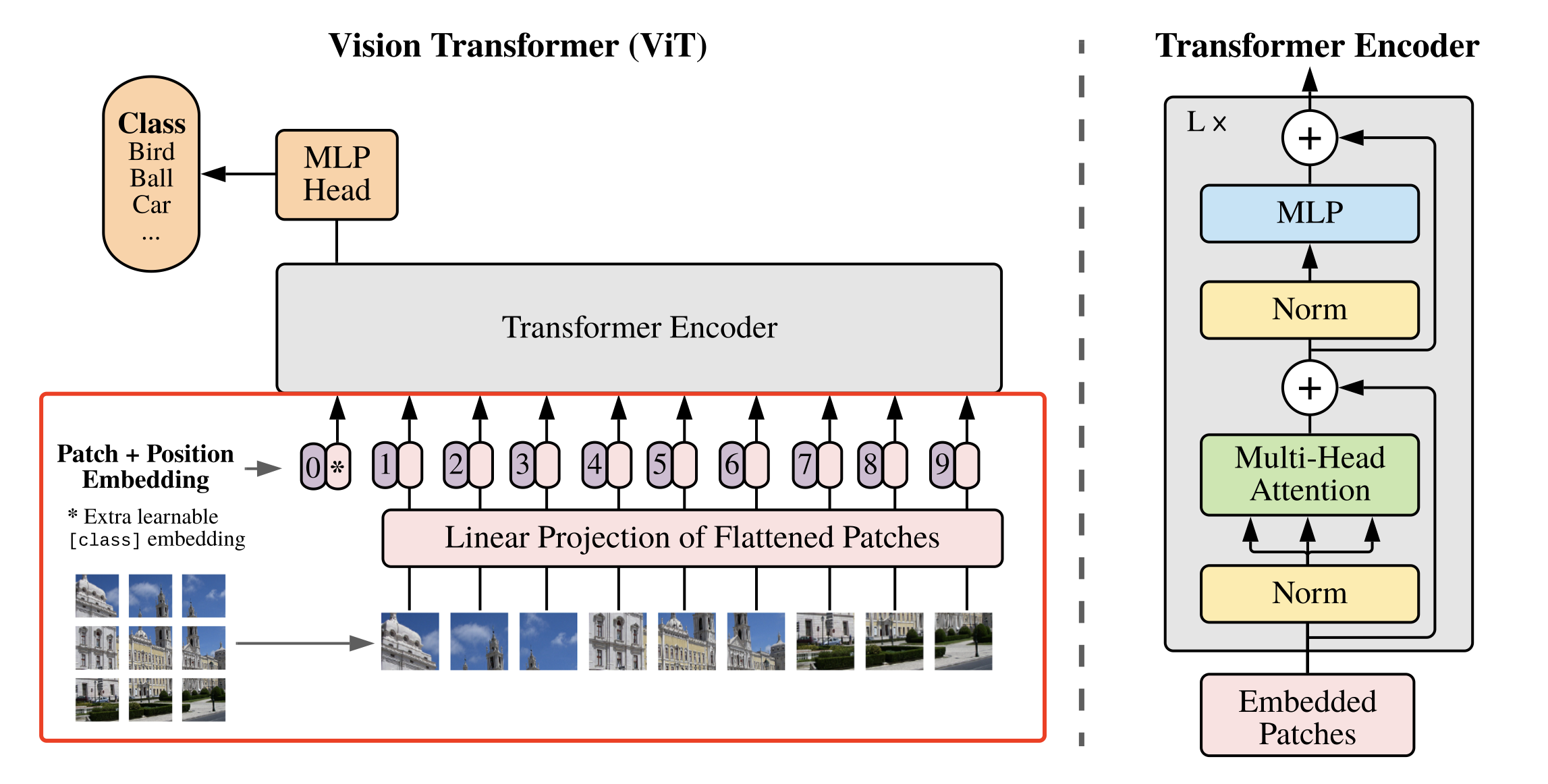
图2 图像分块嵌入示意图
具体代码实现如下所示。本文中将每个大小为 P 的图像块经过大小为 P 的卷积核来代替原文中将大小为 P 的图像块展平后接全连接运算的操作。
# 图像分块、Embedding
class PatchEmbed(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
# 原始大小为int,转为tuple,即:img_size原始输入224,变换后为[224,224]
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
# 图像块的个数
num_patches = (img_size[1] // patch_size[1]) * \
(img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
# kernel_size=块大小,即每个块输出一个值,类似每个块展平后使用相同的全连接层进行处理
# 输入维度为3,输出维度为块向量长度
# 与原文中:分块、展平、全连接降维保持一致
# 输出为[B, C, H, W]
self.proj = nn.Conv2D(
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# [B, C, H, W] -> [B, C, H*W] ->[B, H*W, C]
x = self.proj(x).flatten(2).transpose((0, 2, 1))
return x2. 多头注意力
将图像转化为 的序列后,就可以将其输入到 Transformer 结构中进行特征提取了,如 图3 所示。
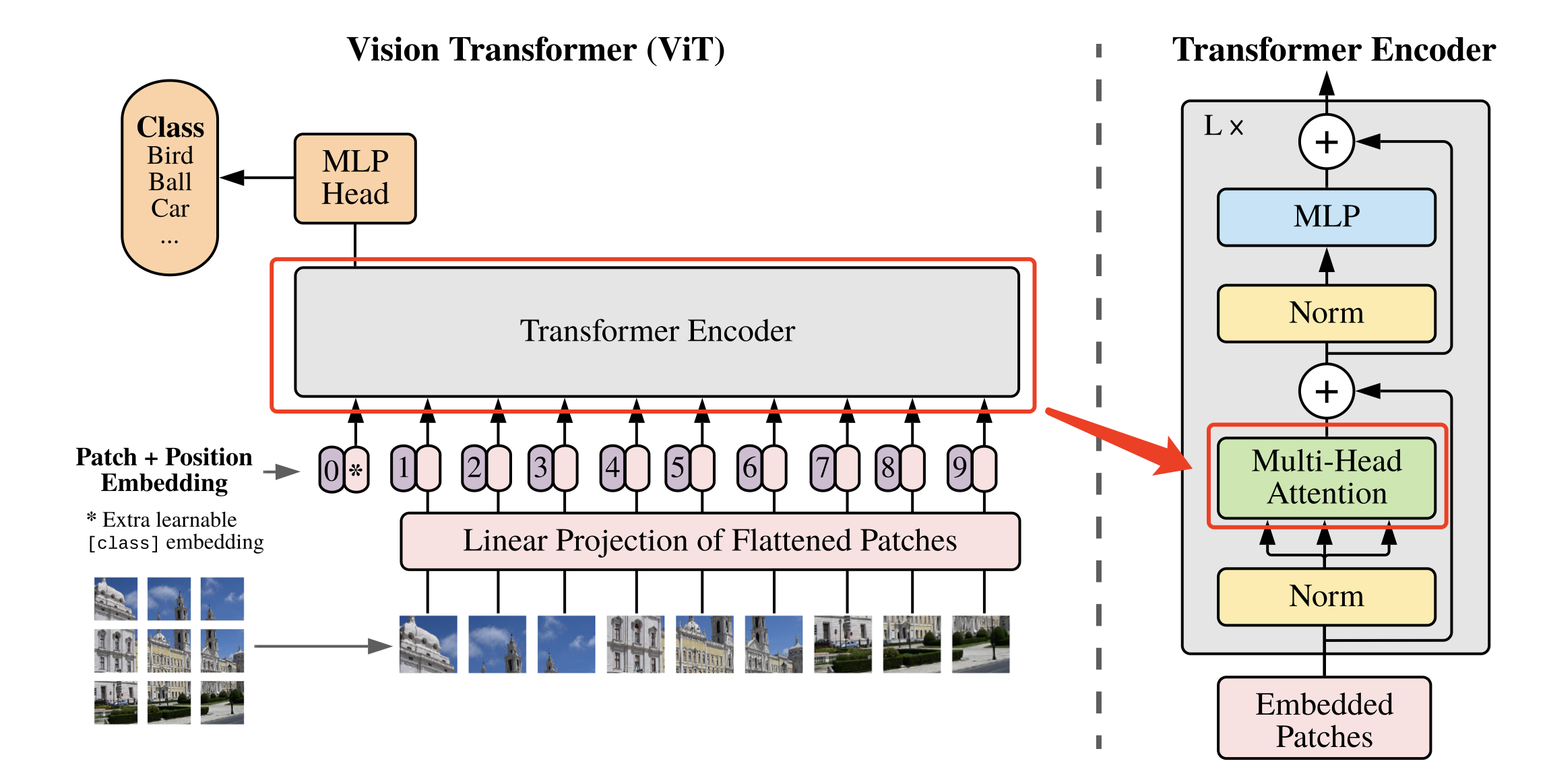
图3 多头注意力示意图

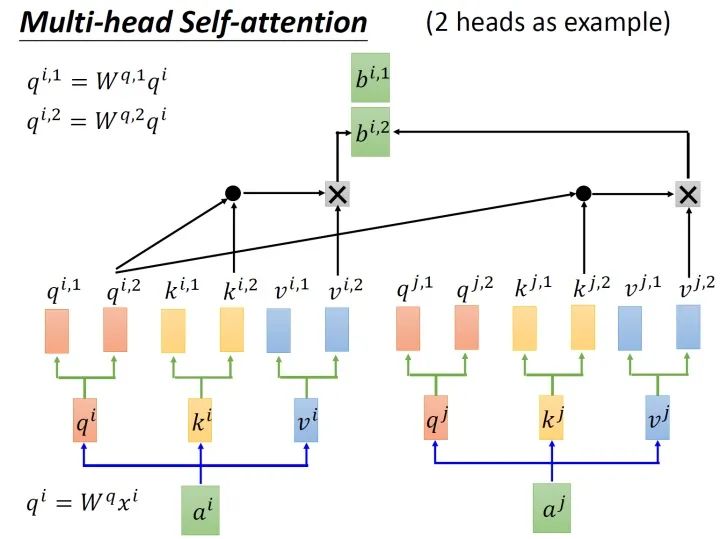
图4 多头注意力

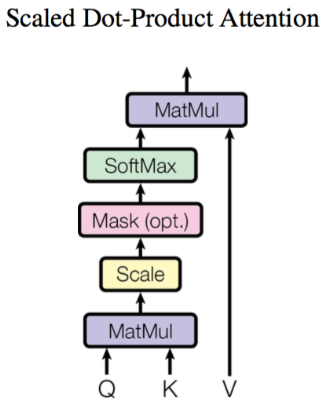
图5 缩放点积注意力
具体代码实现如下所示。
# Multi-head Attention
class Attention(nn.Layer):
def __init__(self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.,
proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
# 计算 q,k,v 的转移矩阵
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
# 最终的线性层
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
N, C = x.shape[1:]
# 线性变换
qkv = self.qkv(x).reshape((-1, N, 3, self.num_heads, C //
self.num_heads)).transpose((2, 0, 3, 1, 4))
# 分割 query key value
q, k, v = qkv[0], qkv[1], qkv[2]
# Scaled Dot-Product Attention
# Matmul + Scale
attn = (q.matmul(k.transpose((0, 1, 3, 2)))) * self.scale
# SoftMax
attn = nn.functional.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
# Matmul
x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((-1, N, C))
# 线性变换
x = self.proj(x)
x = self.proj_drop(x)
return x3. 多层感知机(MLP)
Transformer 结构中还有一个重要的结构就是 MLP,即多层感知机,如 图6 所示。
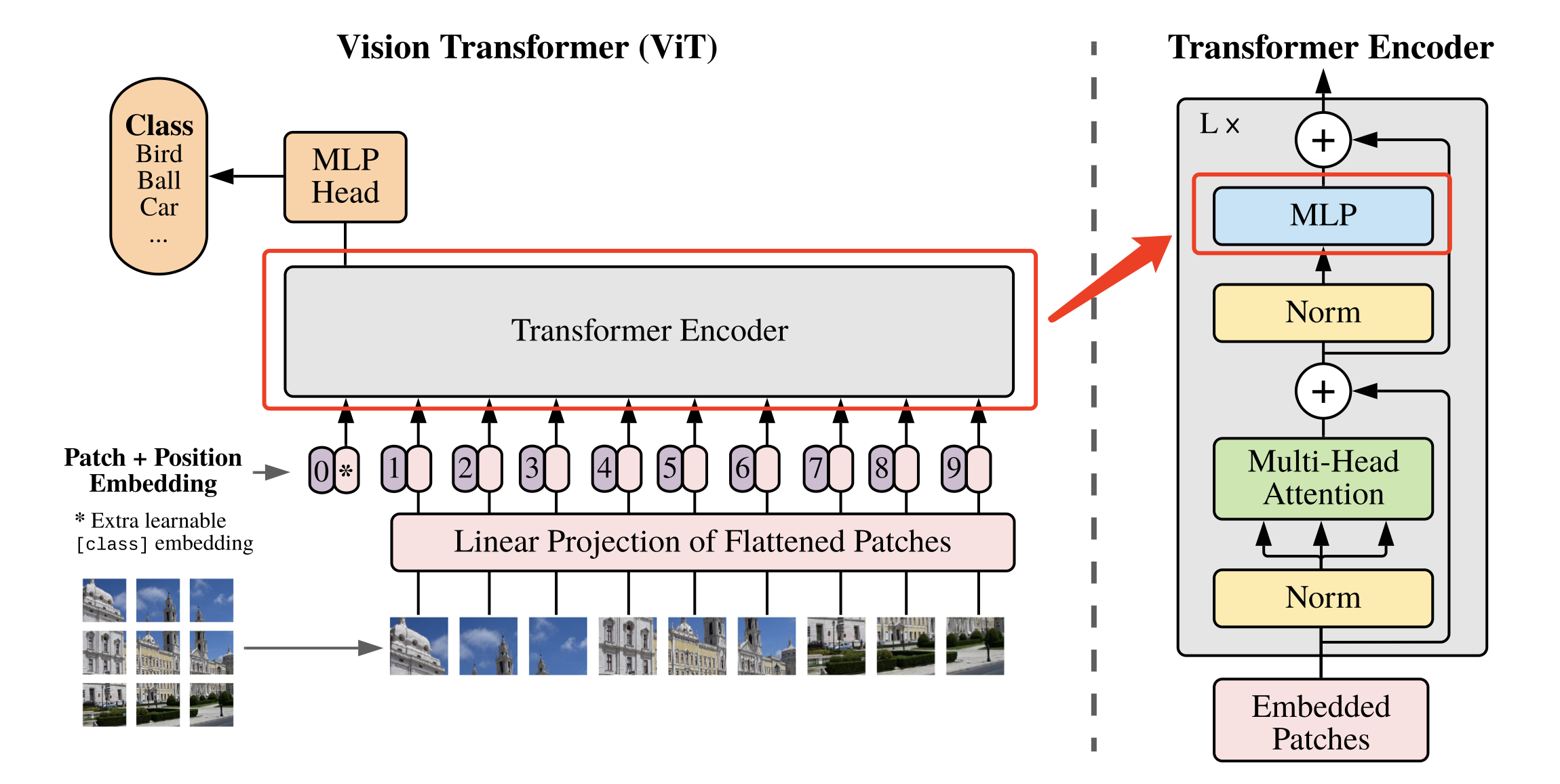
图6 MLP多层感知机的结构
多层感知机由输入层、输出层和至少一层的隐藏层构成。网络中各个隐藏层中神经元可接收相邻前序隐藏层中所有神经元传递而来的信息,经过加工处理后将信息输出给相邻后续隐藏层中所有神经元。在多层感知机中,相邻层所包含的神经元之间通常使用“全连接”方式进行连接。多层感知机可以模拟复杂非线性函数功能,所模拟函数的复杂性取决于网络隐藏层数目和各层中神经元数目。多层感知机的结构如 图7 所示。
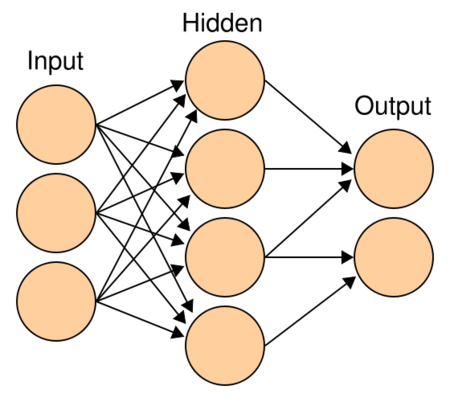
图7 多层感知机
具体代码实现如下所示。
class Mlp(nn.Layer):
def __init__(self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
# 输入层:线性变换
x = self.fc1(x)
# 应用激活函数
x = self.act(x)
# Dropout
x = self.drop(x)
# 输出层:线性变换
x = self.fc2(x)
# Dropout
x = self.drop(x)
return x4. DropPath
除了以上重要模块意外,代码实现过程中还使用了DropPath(Stochastic Depth)来代替传统的Dropout结构,DropPath可以理解为一种特殊的 Dropout。其作用是在训练过程中随机丢弃子图层(randomly drop a subset of layers),而在预测时正常使用完整的 Graph。
具体实现如下:
def drop_path(x, drop_prob=0., training=False):
if drop_prob == 0. or not training:
return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor)
output = x.divide(keep_prob) * random_tensor
return output
class DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)5. 基础模块
基于上面实现的 Attention、MLP、DropPath模块就可以组合出 Vision Transformer 模型的一个基础模块,如 图8 所示。
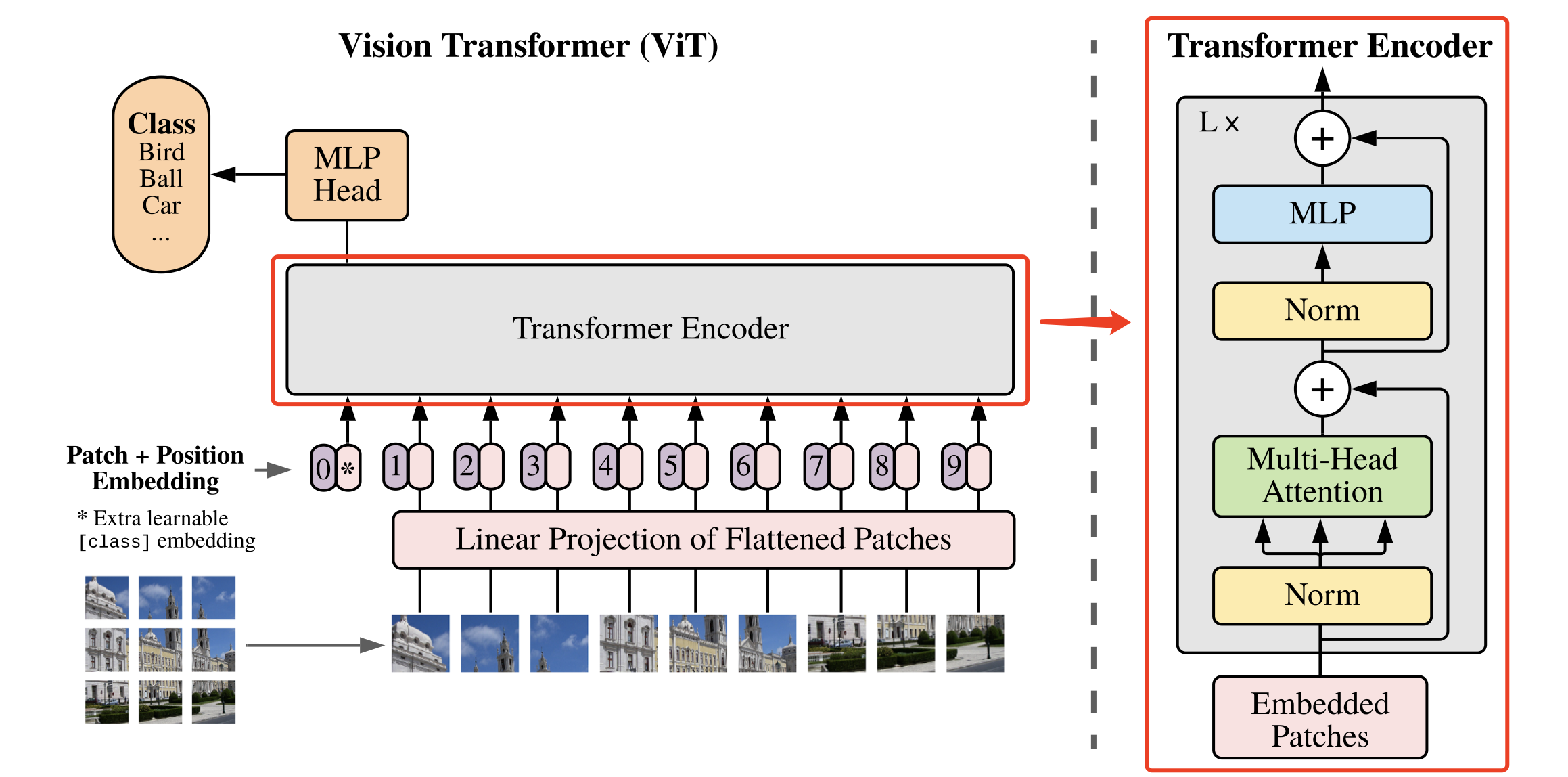
图8 基础模块示意图
基础模块的具体实现如下:
class Block(nn.Layer):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer='nn.LayerNorm',
epsilon=1e-5):
super().__init__()
self.norm1 = eval(norm_layer)(dim, epsilon=epsilon)
# Multi-head Self-attention
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop)
# DropPath
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = eval(norm_layer)(dim, epsilon=epsilon)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop)
def forward(self, x):
# Multi-head Self-attention, Add, LayerNorm
x = x + self.drop_path(self.attn(self.norm1(x)))
# Feed Forward, Add, LayerNorm
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x6. 定义ViT网络
基础模块构建好后,就可以构建完整的ViT网络了。在构建完整网络结构之前,还需要给大家介绍几个模块:
-
Class Token
假设我们将原始图像切分成 3×3共9个小图像块,最终的输入序列长度却是10,也就是说我们这里人为的增加了一个向量进行输入,我们通常将人为增加的这个向量称为 Class Token。那么这个 Class Token 有什么作用呢?
我们可以想象,如果没有这个向量,也就是将 N=9个向量输入 Transformer 结构中进行编码,我们最终会得到9个编码向量,可对于图像分类任务而言,我们应该选择哪个输出向量进行后续分类呢?因此,ViT算法提出了一个可学习的嵌入向量 Class Token,将它与9个向量一起输入到 Transformer 结构中,输出10个编码向量,然后用这个 Class Token 进行分类预测即可。
其实这里也可以理解为:ViT 其实只用到了 Transformer 中的 Encoder,而并没有用到 Decoder,而 Class Token 的作用就是寻找其他9个输入向量对应的类别。
-
Positional Encoding
按照 Transformer 结构中的位置编码习惯,这个工作也使用了位置编码。不同的是,ViT 中的位置编码没有采用原版 Transformer 中的 sincos 编码,而是直接设置为可学习的 Positional Encoding。对训练好的 Positional Encoding 进行可视化,如 图9 所示。我们可以看到,位置越接近,往往具有更相似的位置编码。此外,出现了行列结构,同一行/列中的 patch 具有相似的位置编码。
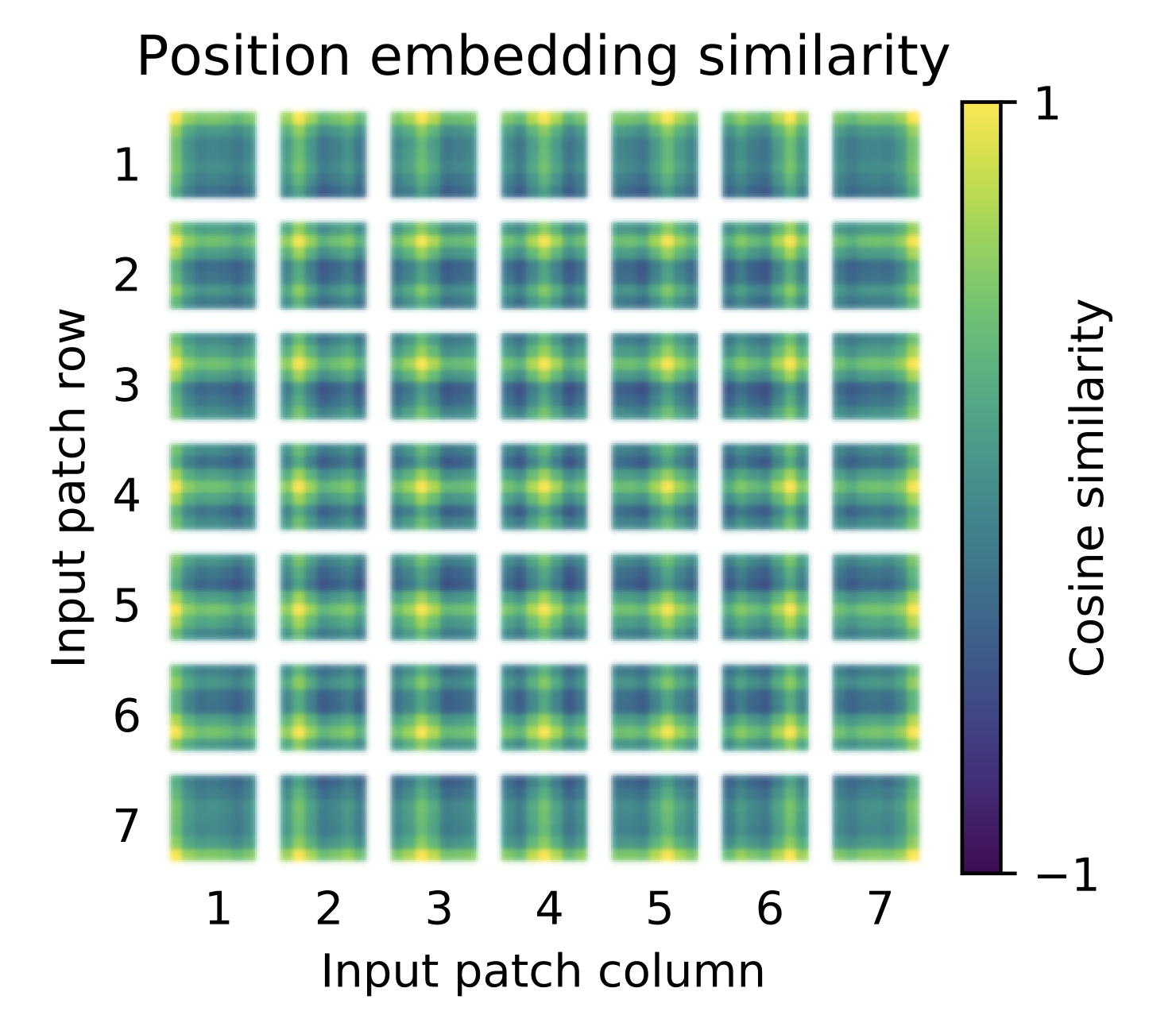
图9 Positional Encoding
-
MLP Head
得到输出后,ViT中使用了 MLP Head对输出进行分类处理,这里的 MLP Head 由 LayerNorm 和两层全连接层组成,并且采用了 GELU 激活函数。
具体代码如下所示。
首先构建基础模块部分,包括:参数初始化配置、独立的不进行任何操作的网络层。
# 参数初始化配置
trunc_normal_ = nn.initializer.TruncatedNormal(std=.02)
zeros_ = nn.initializer.Constant(value=0.)
ones_ = nn.initializer.Constant(value=1.)
# 将输入 x 由 int 类型转为 tuple 类型
def to_2tuple(x):
return tuple([x] * 2)
# 定义一个什么操作都不进行的网络层
class Identity(nn.Layer):
def __init__(self):
super(Identity, self).__init__()
def forward(self, input):
return input
完整代码如下所示。
class VisionTransformer(nn.Layer):
def __init__(self,
img_size=224,
patch_size=16,
in_chans=3,
class_dim=1000,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4,
qkv_bias=False,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
norm_layer='nn.LayerNorm',
epsilon=1e-5,
**args):
super().__init__()
self.class_dim = class_dim
self.num_features = self.embed_dim = embed_dim
# 图片分块和降维,块大小为patch_size,最终块向量维度为768
self.patch_embed = PatchEmbed(
img_size=img_size,
patch_size=patch_size,
in_chans=in_chans,
embed_dim=embed_dim)
# 分块数量
num_patches = self.patch_embed.num_patches
# 可学习的位置编码
self.pos_embed = self.create_parameter(
shape=(1, num_patches + 1, embed_dim), default_initializer=zeros_)
self.add_parameter("pos_embed", self.pos_embed)
# 人为追加class token,并使用该向量进行分类预测
self.cls_token = self.create_parameter(
shape=(1, 1, embed_dim), default_initializer=zeros_)
self.add_parameter("cls_token", self.cls_token)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = np.linspace(0, drop_path_rate, depth)
# transformer
self.blocks = nn.LayerList([
Block(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[i],
norm_layer=norm_layer,
epsilon=epsilon) for i in range(depth)
])
self.norm = eval(norm_layer)(embed_dim, epsilon=epsilon)
# Classifier head
self.head = nn.Linear(embed_dim,
class_dim) if class_dim > 0 else Identity()
trunc_normal_(self.pos_embed)
trunc_normal_(self.cls_token)
self.apply(self._init_weights)
# 参数初始化
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight)
def forward_features(self, x):
B = paddle.shape(x)[0]
# 将图片分块,并调整每个块向量的维度
x = self.patch_embed(x)
# 将class token与前面的分块进行拼接
cls_tokens = self.cls_token.expand((B, -1, -1))
x = paddle.concat((cls_tokens, x), axis=1)
# 将编码向量中加入位置编码
x = x + self.pos_embed
x = self.pos_drop(x)
# 堆叠 transformer 结构
for blk in self.blocks:
x = blk(x)
# LayerNorm
x = self.norm(x)
# 提取分类 tokens 的输出
return x[:, 0]
def forward(self, x):
# 获取图像特征
x = self.forward_features(x)
# 图像分类
x = self.head(x)
return x模型指标
ViT模型在常用数据集上进行迁移学习,最终指标如 图10 所示。可以看到,在ImageNet上,ViT达到的最高指标为88.55%;在ImageNet ReaL上,ViT达到的最高指标为90.72%;在CIFAR100上,ViT达到的最高指标为94.55%;在VTAB(19 tasks)上,ViT达到的最高指标为88.55%。
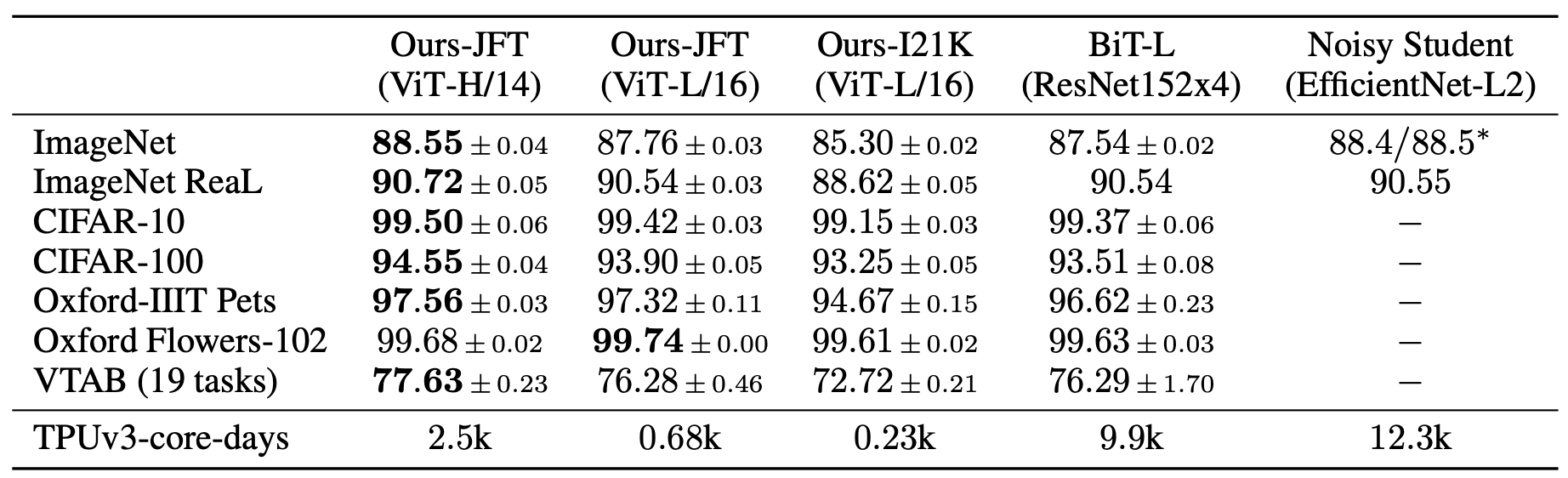
图10 ViT网络指标
模型特点
-
作为CV领域最经典的 Transformer 算法之一,不同于传统的CNN算法,ViT尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。
-
为了满足 Transformer 输入结构的要求,将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列输入到网络。同时,使用了Class Token的方式进行分类预测。