摘要:
- FreeWilly1 和 FreeWilly2这两种模型都擅长推理和理解语言的微妙之处,并通过各种基准进行验证。
- 数据生成过程受到 Microsoft 方法的启发,使用来自特定数据集的高质量指令。
- 尽管与以前的模型相比,FreeWilly 模型在较小的数据集上进行了训练,但仍表现出卓越的性能。
- FreeWilly2 在某些领域击败了 GPT-4,在大多数领域击败了 GPT-3。
随着 Llama 2 和现在的 FreeWilly 的出现,开源社区正在取得连胜。随着竞争的加剧,毫无疑问我们将在人工智能领域获得更快的发展。
在人工智能领域有一个非常重要的分支,就是自然语言处理(NLP)。简单来说,就是让计算机能够理解和生成人类使用的自然语言,比如中文、英文等。目前最先进的自然语言处理技术,就是大规模语言模型(LLM)。这种技术利用海量的文本数据,训练出一个能够捕捉语言规律和知识的 AI 模型。这个模型可以应用在各种场景中,比如聊天、搜索、写作、翻译等。
目前最知名的大规模语言模型,就是 OpenAI 开发的 GPT 系列。这个系列的最新版本,叫做 GPT-4,参数可能达到万亿甚至百万亿级别,由于官方未正式公布,但从GPT-3.5的1750亿参数基本能推断GPT-4更加庞大。参数是 AI 模型中用来存储和调整信息的变量,参数越多,模型越强大。而 ChatGPT 就是基于 GPT-3.5(1750 亿个参数)搭建的一个智能聊天机器人,可以与人类进行流畅、有趣、有深度的对话。
不过,OpenAI 的 GPT 系列并不是唯一的选择。最近LLM开源界非常热闹,不断推出各种能与GPT媲美的模型出来,前几天,一家名为 Stability AI 的公司,与它的子公司 CarperAI 联合发布了两个新的大规模语言模型,分别叫做 FreeWilly1 和 FreeWilly2。这两个模型都是基于 Meta 的 LLaMA 系列模型进行微调的,能够处理复杂的自然语言理解和推理任务,而且是开源和免费的,不过目前授权仅用于研究,不能用于商业。
Meta 是一家专注于元学习(Meta-Learning)和元数据(Meta-Data)技术的公司。元学习是一种让 AI 模型能够快速适应新任务和新环境的技术。元数据是一种描述数据本身特征和关系的数据。Meta 在 2022 年底发布了一系列商用可用、开源免费、高性能低成本、跨平台适配的大规模语言模型,叫做 LLaMA 系列。其中最新版的 LLaMA 2 拥有 700 亿个参数,相当于 GPT-3.5 的一半左右。
FreeWilly1 就是在 LLaMA 65B(650 亿个参数)的基础上进行微调得到的,而 FreeWilly2 则是在 LLaMA 2 70B(700 亿个参数)上进行微调得到的。它们都采用了一种非常先进和高效的数据生成和训练方法,叫做 Orca Method。这种方法是由 Microsoft 在 2022 年提出的一种利用大规模语言模型自身生成训练数据,并通过逐步学习复杂解释过程来提升推理能力的方法。
Stability AI 根据这种方法,利用不同质量和复杂度的语言模型生成了 60 万条训练数据,并用这些数据对 LLaMA 系列模型进行了微调。虽然这些数据只占原始 Orca 方法使用数据量的 10%,但却取得了非常显著的效果。
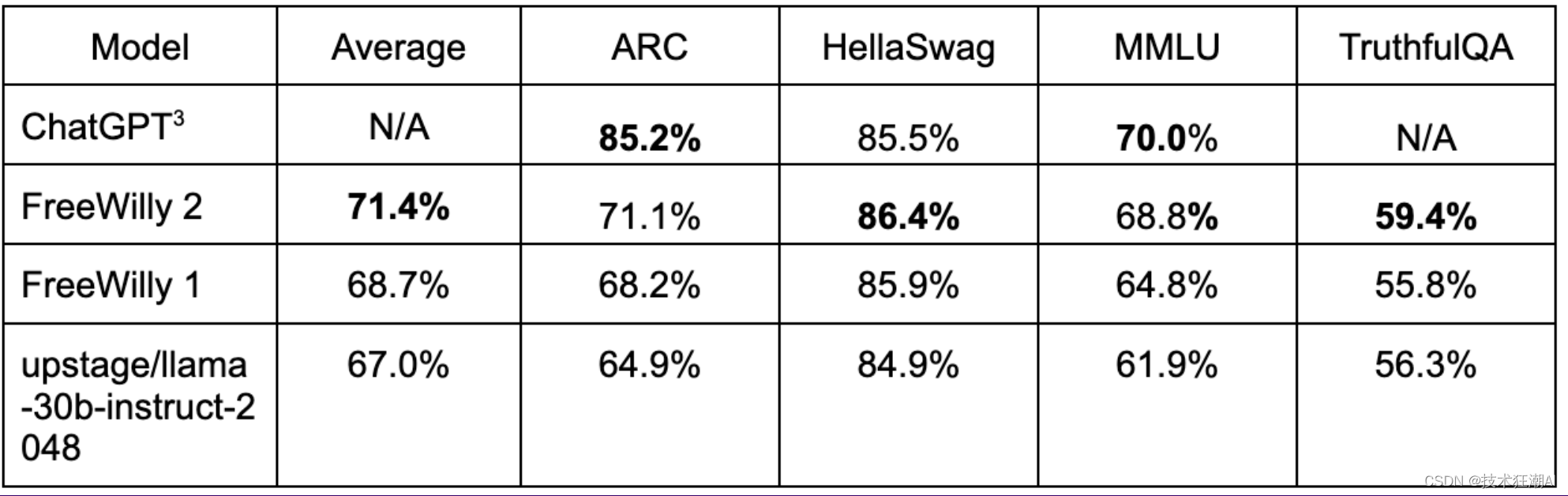

最后,FreeWilly1 和 FreeWilly2 在多个公开评测指标上展现了惊人的性能,甚至超过了 ChatGPT。
- 在 HellaSwag 这个需要常识和推理能力的自然语言推理任务上,FreeWilly2 达到了 86.4% 的准确率,而 ChatGPT 只有 85.5%。
- 在 MMLU 这个需要多任务能力的综合评测上,FreeWilly2 达到了 68.8% 的准确率,而 ChatGPT 只有 70.0%。
- 在 AGIEval 这个用于评估人工通用智能(AGI)的综合评测上,FreeWilly2 在除了 SAT 数学之外的所有子任务上都达到了与 ChatGPT 相当或更高的性能。
这些成绩无疑证明了 FreeWilly1 和 FreeWilly2 的强大和先进,也为开源社区提供了一种新的可能性和机会。Stability AI 表示,它们希望这两个模型能够为 AI 社区带来无限的可能性,激发新的 AI 应用的灵感。同时,它们也强调了对 AI 安全性的重视,表示已经对这两个模型进行了内部的安全测试,并欢迎外部的反馈和协助。
如果您对 FreeWilly1 和 FreeWilly2 感兴趣,想要了解更多的细节或者尝试使用它们,您可以访问 Stability AI 的官方网站或者 Hugging Face 的[模型库]。相信您一定会被这两个超强大的开源语言模型所震撼和惊喜。谢谢您的阅读!
资源
GPT-4 技术报告
https://arxiv.org/abs/2303.08774v3
Orca:从 GPT-4 的复杂解释痕迹中渐进式学习
https://arxiv.org/abs/2306.02707
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。