特征选择 | 变量重要性衡量
写在前面
特征选择是预测模型构建的关键步骤,旨在1)降低数据维度,减少计算量;2)剔除一些无关或冗余变量,改善预测效果。
常规方法
用于特征选择的方法众多
- 简单的单因素分析(t检验、卡方)
- 回归分析(单因素或多因素回归)
- 特征选择算法(信息增益、LASSO、SHAP、Boruta等)
存在问题
- 1)每个方法选出的变量不尽相同,以哪个为准?为什么要以这个为准?
- 2)有些方法仅给出变量重要性,如SHAP,那到底是选择top5还是top10还是top20?
解决策略
一般来说,多数朋友会仅使用某一种特征选择算法,进而基于选择出的变量做预测模型。但是,这样很可能被审稿人问到,为何选择这个方法,代表性何在?为什么选择top10变量构建模型?为了规避这个问题,比较好的解决策略是:采用多个常用的特征选择方法,分别做特征选择,并纳入这些方法中共有的因素。
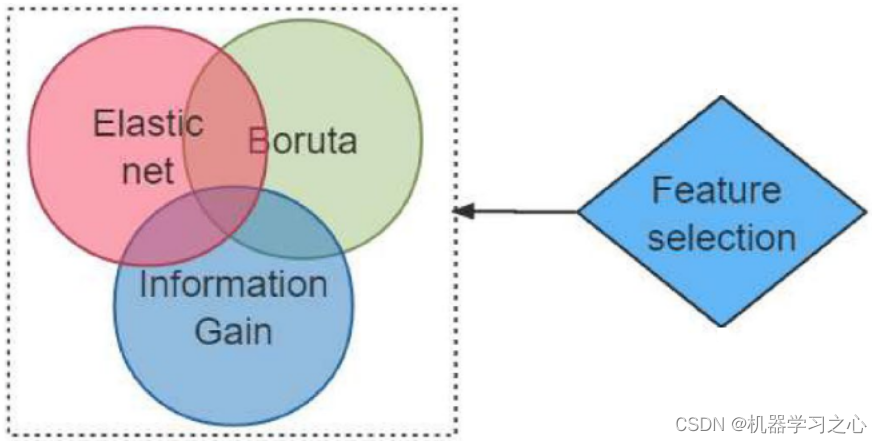
参考资料
[1] Artificial intelligence in detecting left atrial appendage thrombus by transthoracic echocardiography and clinical features: the Left Atrial Thrombus on Transoesophageal Echocardiography (LATTEE) registry
[2] https://blog.csdn.net/kjm13182345320/article/details/128690229
[3] Reference: XGBoost-SHAP-based interpretable diagnostic framework for alzheimer’s disease