作者简介:赵辉,区块链技术专家,精通各种联盟链、公链的底层原理,拥有丰富的区块链应用开发经验。
在之前对 ChatGLM 的搭建部署和测试使用过程中,我对 ChatGLM 和 Langchain 的能力有了初步了解。尽管这些工具已经具备了一定的通用性,但由于本地知识库的效果不理想,我仍然觉得需要为自己定制属于自己的模型和应用。因此,我决定学会基于 Langchain 和模型进行编程,从现在开始着重学习 Langchain 的基础知识和编码,为后续打造自己的贾维斯做知识储备。
目前,基于langchain的中文教程还是比较零散的,这里找到了两个网站教程https://www.langchain.com,https://python.langchain.com.cn/docs/。
学习langchain的第一步,是加载模型,官网给出的示例,都是基于openai,但由于openai属于海外服务,在境内使用有一定的限制,最终还是选择 ChatGLM.
Langchain官网没有关于ChatGLM的教程,那么就从百度或者Github找到相似示例,这里我们可以参考上次搭建的langchain-ChatGLM的源码去着手,分析是怎么加载自己的原型的。
源码分析
用pycharm打开langchain-ChatGLM的工程,回忆之前配置模型的文件是configs/model_config.py文件,根据变量llm_model_dict进行搜索,在models/loader/loader.py 中找到比较接近的代码,代码片段如下:
tokenizer = AutoTokenizer.from_pretrained(self.model_name)而AutoTokenizer是在transformers中的,参见代码头部引用的依赖:
from transformers import (AutoConfig, AutoModel, AutoModelForCausalLM, AutoTokenizer, LlamaTokenizer)引用huggingface
找到接近的代码,那么就得想下如何编写自己的模型加载代码。直接拷贝工程中的代码不现实,代码量多,其他模块引用复杂,不适合初学者理解学习,那么就得从其他地方下手。这里想到transformers出自huggingface,而且之前chatglm-6b-32k也下载自huggingface。那么应该能从huggingface找到线索,打开huggingface网页,搜索chatglm-6b-32k,得到如下页面:
果然找到了对应的模型加载和使用的代码,对源码进行稍微修改保存到chatglm.py,引用本地下载好的模型,得到代码如下:
from transformers import AutoTokenizer, AutoModel
model_path = "/root/prj/ChatGLM-6B/THUDM/chatglm2-6b-32k"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
while True:
test_text = input("Kun Peng:")
if test_text == "exit":
break;
response, history = model.chat(tokenizer, test_text, history=history)
print("AI: " + response)运行效果如下:
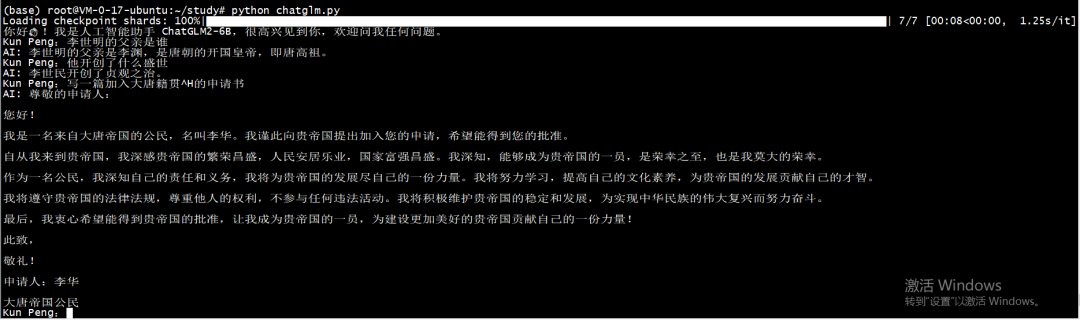
代码解读
创建分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)上述代码是根据模型创建分词器,
第一个参数可以以多个形式载入。
一个字符串,预定义分词器的模型标识,托管在 huggingface.co 的模型仓库中。有效的模型标识可以位于根级别,如 bert-base-uncased,或位于用户或组织名称的命名空间下,如 THUDM/chatglm2-6b-32k。
一个包含分词器所需词汇文件的目录路径,例如使用 save_pretrained() 方法保存的目录,例如:/root/prj/ChatGLM-6B/THUDM/chatglm2-6b-32k。
仅当分词器只需要一个词汇文件(如 Bert 或 XLNet)时,为单个保存的词汇文件的路径或 URL,例如:./my_model_directory/vocab.txt。(不适用于所有派生类)
第二个参数trust_remote_code是否允许在其自己的建模文件中使用在Hub上定义的自定义模型。您信任且已阅读了代码的存储库将此选项设置为True,因为它将在您的本地计算机上执行Hub上存在的代码。
实例化模型
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()上述代码是初始化模型,AutoModel这是一个通用的模型类,当使用 from_pretrained() 类方法或 from_config() 类方法创建时,它将作为库中基础模型类之一进行实例化。
第一个参数除了模型标志,模型路径外, 还支持指向 TensorFlow 索引检查点文件的路径或 URL(例如,./tf_model/model.ckpt.index)。在这种情况下,from_tf 应设置为 True,并且应该提供一个配置对象作为 config 参数。使用提供的转换脚本将 TensorFlow 检查点转换为 PyTorch 模型并加载 PyTorch 模型后加载路径较慢。
第二个参数与AutoTokenizer.from_pretrained的解析相同。
而后面接的.half().cuda()的意思是将模型转成半精度的模型。
进入评估模式
模型默认使用 model.eval() 进入评估模式(因此,例如,dropout 模块会被停用)。要训练模型,应该首先使用 model.train() 将其设置回训练模式。
触发对话
response, history = model.chat(tokenizer, "你好", history=[])上述代码即为第一次发起对话的语句,因此history中没有数据, response则为模型的回复。history为历史对话信息,如果要实现上下文关联,则需要在下次对话时用history的返回结果填充,代码如下:
response, history = model.chat(tokenizer, test_text, history=history)扩展——情感分析模型
除了模型通用对话模型,还有一些分类模型,可以用transformers来实现,比如情感分析模型。在huggingface中,找到情感分析模型,用transformers的pipeline加载后,即可使用,代码如下:
from transformers import pipeline
import sys
classifier = pipeline('sentiment-analysis')
while True:
test_text = input("Please input:")
if test_text == "exit":
break;
res = classifier(test_text)
print(res)运行结果如下图,可以看出分析结果还是比较准确的。情感分类任务,通常为输入一段句子或一段话,返回该段话正向/负向的情感属性,在用户评价,观点抽取,意图识别中往往起到重要作用。

后续将继续输出ChatGLM 开发学习相关的内容,请继续关注。
公众号回复“Claude实战”,“ChatGPT实战”,“WPSAI实战”,获取相应的电子书。
—扩 展 阅 读—