文章目录
Abstract
背景/动机:
判断网络在移动端是否有效主要是依据FLOPs或参数计算量。然而本文中作者提出这些度量在移动端与网络延迟不太相关。
验证方式:
在移动端设备上部署一些移动端较友好的网络进行大量的实验以对不同的度量进行分析。
获得成果/提出的改进:
作者们识别并分析了最近高效神经网络的架构和优化瓶颈,并提出一些方法去缓解这些。——>即提出了MobileOne 主干网络,效率更高,速度更快,性能更优。
1 Introduction
本文的贡献:
- 提出了一种新的主干网络:MobileOne。在移动设备上(iphone12)可以在1ms内运行,且与其他有效/轻量级网络在图像分类任务上相比可达到SOTA;
- 分析了有效/轻量级网络在移动端产生高延迟成本的激活和分支的性能瓶颈;
- 分析了训练时间可重参数化分支和正则化动态松弛在训练中的作用;
- 实验证明本文提出的轻量级模型泛化能力更优,性能更好。
3 Method
本章中,作者分析了移动端 FLOPs、参数计算量与延迟间的关系。评估了不同的结构设计对在手机延迟的影响。基于以上分析,提出了新的网络结构和训练算法。
3.1 Metric Correlations
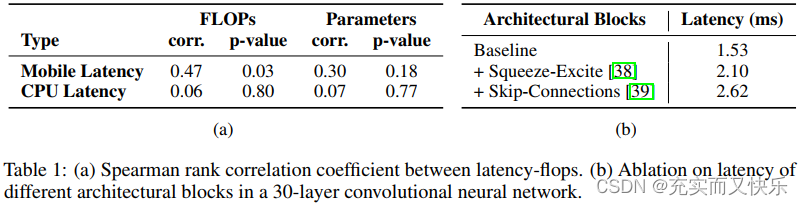
比较模型间大小/规模的最常用方式是直接比较参数量和FLOPs。但在实际移动端应用中,这两者与延迟间没有很好的关联度/相关性。
在本小节中,作者主要研究有效网络/轻量级网络的延迟与FLOPs和参数计算量间的关系。
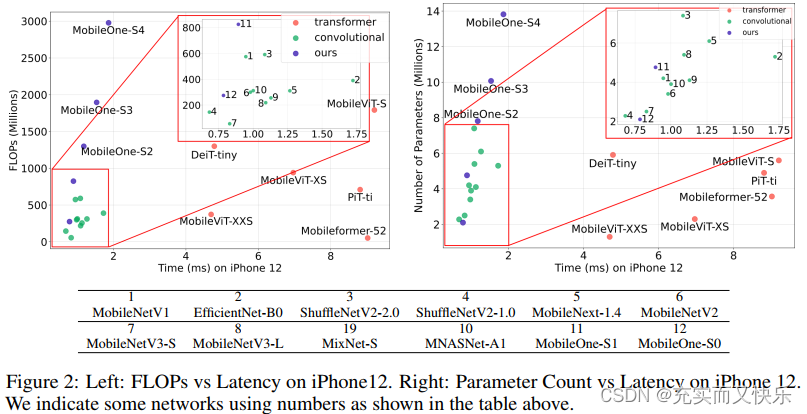
3.2 Key Bottlenecks
Activation Functions
网络结构一致,仅采用不同的激活函数,得到的延迟结果截然不同。
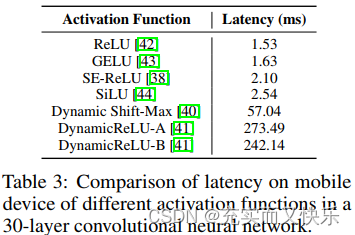
基于上述的实验结果,本文选择ReLU激活来构建自己的新网络:MobileOne。
Architectural Blocks
影响运行时性能的两个关键因素是内存访问成本和并行度。
实验发现:
网络中存有多分支结构会造成额外的内存访问开销和同步开销,比如在使用激活函数激活某一层特征,使用全局池化等。
作者改进的方向:
推理阶段采用无分支的网络结构;不使用SE Block。
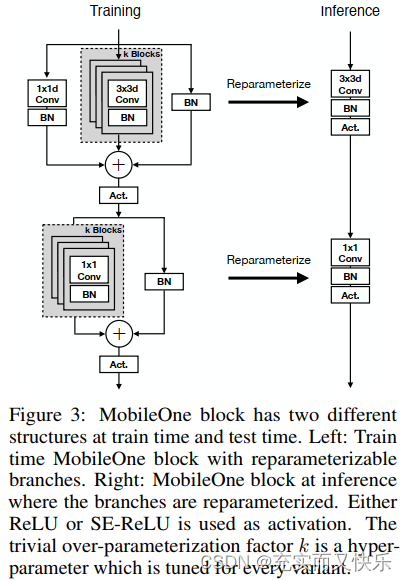
3.3 MobileOne Architecture
MobileOne
扫描二维码关注公众号,回复:
16155831 查看本文章

5 Discussion
- 为移动设备提出了一个高效的、通用的驻港网络—MobileOne;
- 本文提出的MobileOne适用于各种图像任务;
- 本文表明,在效率的方面,延迟可能与其他指标(如参数计数和FLOPs)不太相关;
- 同时还有直接在移动设备上策略其他各种轻量级网络的延迟,证明了本文使用的re-parameterizable结构的有效性;
- 性能达到SOTA。
Limitations and Future Work
- 本文提出的算法/主干网络与其他高效/轻量级网络相比性能可达到SOTA,但是跟大型模型相比差距较大;
- 未来工作的目标是提高轻量级网络的准确率;
- 将本文提出的MobileOne Backbone方法应用到其他视觉领域以取得更有效/快的推理速度。