常见的面试问题
描述使用场景
es集群架构3个节点,根据不同的服务创建不同的索引,根据日期和环境,平均每天递增60*2,大约60Gb的数据。
调优技巧
原文参考:干货 | BAT等一线大厂 Elasticsearch面试题解读 - 掘金
设计阶段的调优
- 根据业务增长的需求,采取日期模版创建索引,通过roll over API实现滚动索引
定义条件,生成新的索引,但都指向一个别名
https://juejin.cn/post/6959744054905012231
-
根据别名对索引进行管理
-
凌晨对索引进行force_merge操作,释放空间
合并Lucene索引在每个分片中保存的分段数,强制合并减少分片中的分段数量
https://blog.csdn.net/weixin_43820556/article/details/122986027
- 冷热分离机制,热数据放在SSD,冷数据定期shrink操作,缩减存储
删除副本,只读索引,减少主分片的数量
https://blog.csdn.net/UbuntuTouch/article/details/109004225
- 使用curator进行索引的生命周期管理
对索引和快照进行管理,配置规则,定时任务调用
https://cloud.tencent.com/developer/article/1382110
-
仅针对需要分词的字段,选用合适的分词器
-
Mapping阶段充分结合各个字段的属性,是否要检索、存储
写入调优
- 写入前refresh_interval=-1
默认情况下索引的refresh_interval为1秒,这意味着数据写1秒后就可以被搜索到,每次索引的 refresh 会产生一个新的 lucene 段,这会导致频繁的 segment merge 行为,如果你不需要这么高的搜索实时性,应该降低索引refresh 周期
-
采用bulk批量写入
-
使用自动生成的id
写入 doc 时如果是外部指定了 id,es 会先尝试读取原来doc的版本号, 判断是否需要更新,使用自动生成 doc id 可以避免这个环节
查询调优
- 禁用批量terms(分页)
- 数据量大时,先基于时间范围检索
- 充分利用倒排索引机制,keyword查询
- 合理的路由机制
索引数据多的调优和部署
动态索引
基于模板+时间+rollover api 滚动创建索引
存储层面
冷热数据分离存储,冷数据force_merge+shrink压缩
部署层面
合理的前期规划,动态增加节点缓解集群压力
master选举机制
基本前提
- 候选主节点才能成为主节点
- 最小主节点数防止脑裂
选举流程

索引文档流程
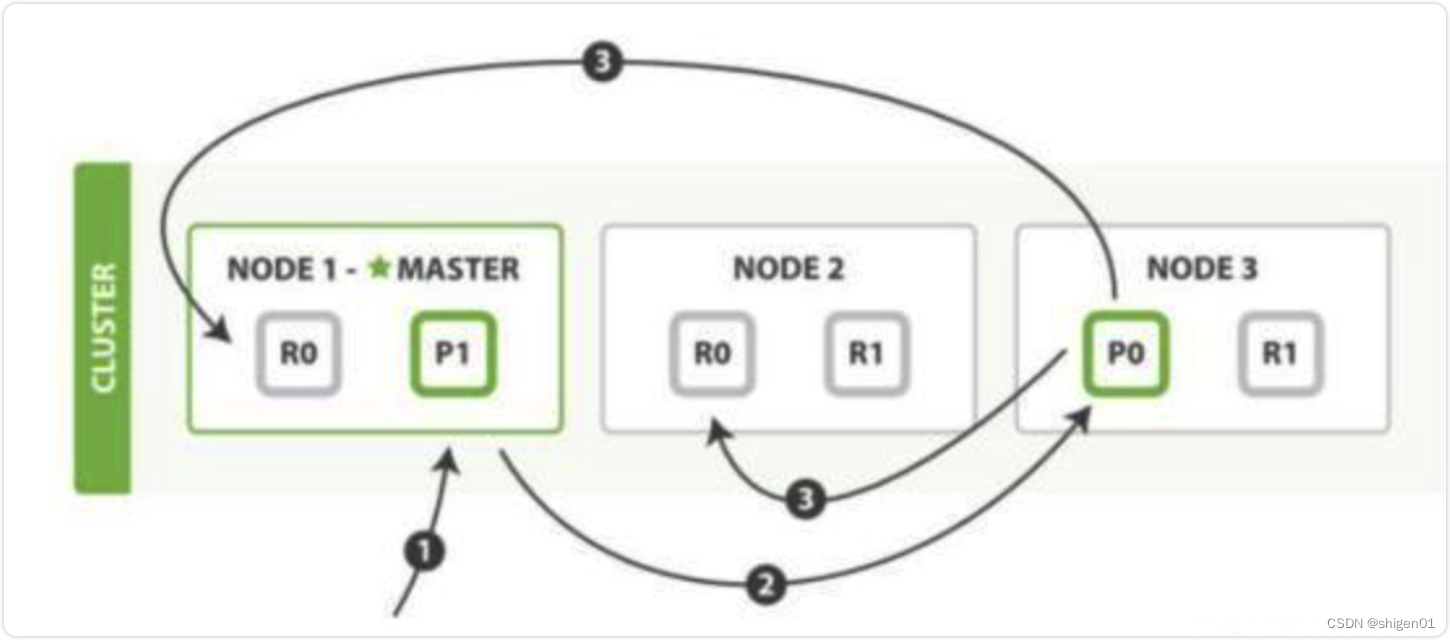
文档获取分片
文档id计算目标分片id
shard = hash(_routing) % (num_of_primary_shards)