语境
这个故事是关于一个托管在 AWS 上的 IoT 项目,该项目接收某些设备生成的数据。
该系统是一个分布式架构,在摄取阶段之后,原始数据通过Amazon Kinesis Data Stream传递。
该流是一系列服务的来源,每个服务负责我们需要对数据执行的不同处理。
Kinesis 是系统的关键点,因为它允许每个使用者读取事件并以其速度处理它们,使每个处理管道独立于其他处理管道。Kinesis 还可以吸收所有流量峰值,并允许在一个或多个处理管道因任何原因暂时禁用时继续摄取。
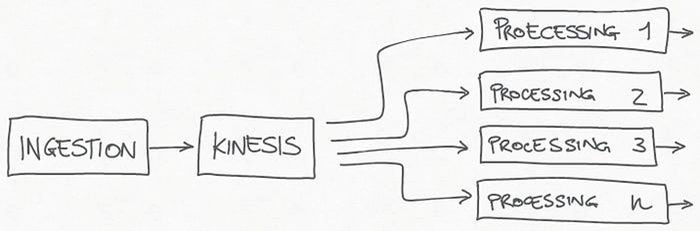
Kinesis Data Stream 是所有处理管道的来源
交叉检查的需要
在项目的发展过程中,验证对数据流执行的处理变得很重要。我们的想法是找到一种方法来保存原始数据,以便可以交叉检查结果、快速排除故障并验证处理。
当数据量巨大时,您不能简单地将其保存在关系数据库中并以当前和未来所有可能的方式查询它。但 OpenSearch(当然还有ElasticSearch)可以做得很好,而且也是查询和过滤数据、进行高级聚合以及可视化结果的绝佳工具,几乎在几秒钟内完成,而无需进行初步数据准备。
因此,我们添加了一种嗅探器组件,在快速丰富/反规范化过程之后,它开始使用 Kinesis 中的事件并将它们保存到 OpenSearch 中。
结果是包含来自所有设备的所有数据的索引,事实证明 OpenSearch 是满足我们的故障排除需求的绝佳工具。
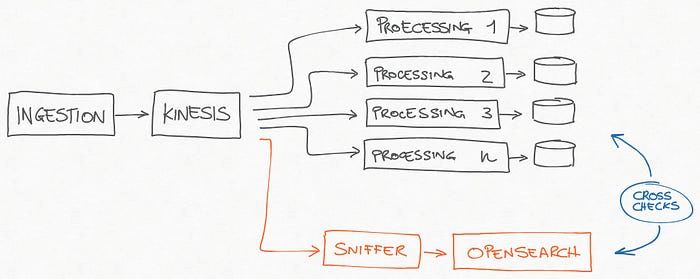
数据“嗅探”以对处理后的数据进行交叉检查
性能和成本考虑
OpenSearch 对于大数据量非常有用,但在我们的场景中,每个文档约为 2KB,每天必须存储 4000 万个文档。
我们开始使用每日指数。从性能角度来看,OpenSearch 运行得非常好,但每个索引大约为22 GB ,这意味着每年大约8 TB的数据。对于一个服务来说有点太多了,毕竟严格来说它不是系统的一部分,而是类似于“数据观察工具”的东西。
成本很快就开始太高,我们看到的第一个选择是删除旧数据并仅保留尾部,例如最近两三个月的数据。
这肯定是一个选择,但有时对长期数据执行查询可能会很有趣,例如仅来自单个设备的数据,但在很长一段时间内,例如一年,甚至更长。
更好的替代方案是找到一种方法来聚合数据,减少数据大小,从而通过支付类似的成本来保留更多数据。
汇总职位
更干净的方法似乎是使用Index rollups,该功能通过以完全透明的方式进行指标聚合来自动降低数据粒度。
经过一些测试,我们注意到我们的数据存在一些错误。可能与我们数据中的某些问题有关,或者可能是因为 OpenSearch 相对较年轻而存在错误。我们没有发现这些失败背后的原因,我们没有有用的日志,也没有时间花在调查上。
除此之外,该解决方案在聚合类型方面受到限制,因为汇总作业只能执行All、Min、Max、Sum、Avg和Value Count。
在我们的场景中,它对我们在聚合逻辑方面拥有更多自由可能很有用,例如,收集指标的分布。
因此我们探索了使用索引变换的选项,通过这个功能我们终于达到了我们的目标。,
转变工作
该解决方案基于针对不同需求拥有两组不同数据的想法:
· 未压缩原始数据的滑动窗口(在我们的例子中配置为最近 2 个月)
· 一组历史压缩数据
(尽可能久远地进入过去)
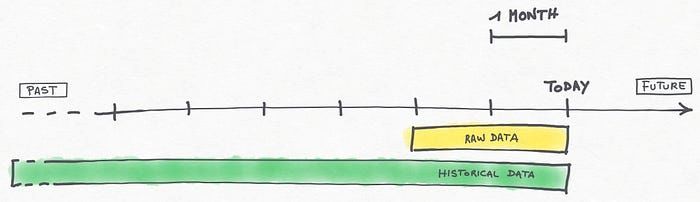
时间线和两个数据集
很快,该解决方案的工作原理如下:
· EventBridge规则计划每天执行并启动 Lambda 函数
· lambda 创建每月索引及其压缩数据的映射(在 OpenSearch 中这些操作是幂等的)
· lambda 删除早于配置的滑动窗口的未压缩数据的每日索引(在我们的例子中,这意味着在执行时间之前删除第 61 个每日索引)
· lambda 创建每日转换作业,以便立即执行
· 执行转换作业,并处理前一天的数据
· 每个设备的数据以 1 小时为单位进行聚合
· 一些指标是使用可用的标准聚合(min、max、average等)进行聚合的
· 其他指标使用自定义scripted_metric 聚合进行处理,并利用映射/组合/减少脚本的灵活性,在我们的示例中,数据被缩减为自定义分布报告
优点和缺点
根据我们需要进行的调查,我们可以决定是使用最新的原始数据还是使用历史压缩数据更好。
例如,如果需要检查特定设备上周到底发送了什么,我们可以使用未压缩原始数据的每日索引。
相反,如果需要研究去年的趋势,则压缩的月度指数是正确的数据源。
该解决方案的一个缺点是,当我们开始进行可视化时,我们必须提前决定要使用两个数据源中的哪一个。架构不同,因此在每日索引上创建的可视化效果不适用于每月索引,反之亦然。
这实际上并不是一个主要问题,因为通常您很清楚什么来源最适合特定需求。无论如何,从这个角度来看,索引汇总功能肯定更好,因为索引是相同的,并且您不必处理这个双数据源。
一些快速计算
每日原始数据未压缩索引
· 每个 JSON 文档大约 1.6 KB
· 每个索引平均包含 4000 万个文档
· 每日索引大小平均为23 GB
· 1个月数据量约700GB
每月汇总指数
· 每个 JSON 文档大约 2.2 KB
· 每个索引平均包含 1500 万个文档
· 索引每月大小平均为6 GB
最后的考虑因素
很容易看出,最终的压缩比大约为100:1。
这意味着,即使为 1 个副本配置历史索引并将其大小加倍,处理一个月原始数据所需的磁盘空间也允许我们存储超过4 年的聚合数据。
除此之外,OpenSearch 查询聚合索引的速度要快得多。
在实施此解决方案之前,我们已经存储了 1 年的原始数据,但由于性能问题,我们不得不将 OpenSearch 集群扩展到 6 个节点。这产生了相当大的计算和存储资源成本。
借助这一自动进行数据聚合的无服务器解决方案,我们能够将集群大小减少到只有 3 个节点,每个节点的存储空间更小。
换句话说,在数据丢失量较小且可接受的情况下,今天我们花费更少的钱,同时我们有能力保留所有历史数据。