前言
无论是公司的项目还是自己的项目,我们都使用到了邮箱这一功能,并且在一些场景下,我们会要求查询指定邮箱号。比如向该邮箱号发送电子邮件,以及使用该邮箱绑定用户信息等,但是邮箱号本身无规律,如果直接查询那么基本都得走全表,这对于我们这种千万上亿级用户的库来说全表肯定是不可能的,所以我们需要一个方法去解决这个问题。
普通索引与前缀索引
我们能想到的最快的优化方式就是为邮箱这个字段创建一个索引。
两种方式,一种是直接创建一个普通的索引,另一种方式是创建一个前缀索引。
普通索引我们知道就会直接把这个字段的值作为我们的索引段,而前缀索引则是以当前字段的值的前x位组成索引段,这意味着可以节省一定的空间。
比如我们的邮箱号为 [email protected],那么我们使用普通索引则这个索引的内容为:
索引段:[email protected] 数据段:主键id
而如果我们使用前缀索引,并且长度为5则索引的内容为:
索引段:12345 数据段:主键id
这两个索引的区别不仅仅在于长度,还在于前者是完整的,后者是模糊的。
这意味着前者查询到之后可以直接返回到结果集,然后继续向下查询直到数据不匹配,
而后者查询到之后,还需要进行一次回表并且判断邮箱号是否匹配,如果不匹配,那么就继续查找下一条记录。
并且由于使用的是前缀来进行查找,那么同样的前缀但是真正满足我们要查询的数据的行数可能特别少,会增加我们扫描的次数。
也就是,我们使用前缀索引,占用的空间更少了,但是可能会增加额外的扫描次数。
所以,合理的制定前缀的长度是非常重要的,因为这意味着合理的空间占用并且更少的扫描次数。
那么我们再创建索引的时候,更关注的就是前缀的区分度,越高的区分度,意味着重复的键值越少。所以我们可以尝试通过统计索引上有多少个不同的值来判断要使用多长的前缀。
如何制订前缀长度?
那么如何判断前缀长度是否合理?
我使用如下的sql语句先进行一次email这个字段上有多少个不同的值的检索
select count(distinct email) as L from sys_user;
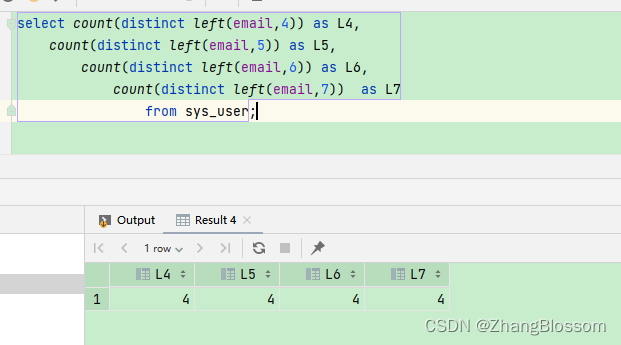
然后,依次选取不同长度的前缀来看这个值,比如我们要看一下 4~7 个字节的前缀索引,可以用这个语句:
select count(distinct left(email,4)) as L4,
count(distinct left(email,5)) as L5,
count(distinct left(email,6)) as L6,
count(distinct left(email,7)) as L7
from sys_user;
当然,使用前缀索引很可能会损失区分度,所以你需要预先设定一个可以接受的损失比例,比如 5%。然后,在返回的 L4~L7 中,找出不小于 L * 95% 的值,假设这里 L6、L7 都满足,你就可以选择前缀长度为 6。
对覆盖索引的影响
前缀索引不仅仅有可能影响扫描的行数,还会导致覆盖索引也一起失效。
比如如果我们直接创建一个普通索引,查询语句为:
select id,email from user where email = ‘xxxx’
那么对于这条语句,由于索引直接包含了完整的email,并且其数据段就是id,那么可以直接走覆盖索引,可以少一次回表查询。
而如果你创建的是前缀索引,那么即使是一样的查询条件,他也得回表再判断一次数据。
并且即使你把前缀的长度设定为和当前email一样的长度,他也依旧会回表,因为他不能确定是否完全截断了所有的数据。
其他方法
对于检索邮箱号,我们基本的解决方法就是前缀索引了,那么如果我们要检索的是前缀区分度更小的身份证号呢,因为我们知道对于同意省份地区的人,他们的前缀是相同的,比较不同的可能就是生日以及最后4位。
所以对于身份证号,我们可以使用倒序+前缀的方式。
也就是插入身份证号之后先使用reverse方法吧身份证号倒叙,然后取倒叙的前4位作为前缀。
第二种方法是使用crc32函数,我们可以对身份证号取crc32函数得到一个几乎不会重复的hash值,之后查询的时候我们以这个hash值作为索引来查询,当然,为了确保查询正确,我们还需要再后面补上and条件来精确的判断一次身份证,当然由于有了crc32这个hash字段作为索引,所以查询的范围一下子就小了很多了。
