一、故障现象
某次服务器告警宕机故障,无法ssh连入,控制台登录后查看,发生OOM事件,OOM就是我们常说的Out of Memory内存溢出,它是指需要的内存空间大于系统分配的内存空间,导致项目程序crash,甚至主机宕机; 报错如下:

发生OOM事件后,OOM killer 会杀掉某个进程以腾出内存留给系统用,不致于让系统立刻崩溃。如果检查相关的日志文件(/var/log/messages)就会看到如上图面类似的 Out of memory。
二、处理及分析
1)临时紧急处理:因OS已经"脑死”,目前只能重启,云控制台执行重启云实例操作:

2)查看日志,那段时间日志丢失了:

grep "Out of memory" /var/log/messages 也是一样无记录;
3)其他日志:
cat /var/log/kern.log |grep 'memory' #可看到也没有日志被记录到

dmesg -T | grep -i "Out of memory" #无任何输出
dmesg |grep -E 'kill|oom|out of memory' #无任何输出

find /var/log/ |grep -irn "out of memory" #根据内容查找文件
find /var/log/ -exec grep -irn "out of memory" {} \; -print #或,r对目录文件递归查询,-i忽略大小写,-n显示再文件中的行号,-H只显示那包含搜索的内容的些文件,多个字符串使用egrep -w -R 'word1|word2';
find /var/log/ -exec grep -irn "kill process" {} \; -print #输出如下,也未出现最近的,且同类故障最近出现过,根据当Out of memory时,系统会自动找到内存分配最大的“罪犯”,将其kill,结合历史经验,因此本次仍然NVS程序是最大的肇事者
/var/log/errors.log:28:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25976 (NVS) score 807 or sacrifice child
/var/log/errors.log:30:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25985 (event poller 0) score 808 or sacrifice child
/var/log/errors.log:32:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25996 (event poller 11) score 808 or sacrifice child
/var/log/errors.log:34:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25997 (event poller 12) score 808 or sacrifice child
/var/log/errors.log:36:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 26020 (event poller 0) score 808 or sacrifice child
/var/log/errors.log:38:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 26032 (event poller 0) score 808 or sacrifice child
/var/log/errors.log:40:Sep 29 14:49:57 HB-Sihua-41-New kernel: Out of memory: Kill process 26064 (event poller 0) score 810 or sacrifice child
/var/log/errors.log:71:Dec 26 10:06:01 HB-Sihua-41-New kernel: Out of memory: Kill process 28075 (NVS) score 766 or sacrifice child
/var/log/errors.log:77:Feb 14 13:05:33 HB-Sihua-41-New kernel: Out of memory: Kill process 5787 (NVS) score 630 or sacrifice child
/var/log/errors.log:79:Feb 14 15:59:14 HB-Sihua-41-New kernel: Out of memory: Kill process 2679 (NVS) score 626 or sacrifice child
/var/log/errors.log:82:Feb 14 16:42:37 HB-Sihua-41-New kernel: Out of memory: Kill process 2679 (NVS) score 633 or sacrifice child
/var/log/errors.log:88:Feb 27 18:20:57 HB-Sihua-41-New kernel: Out of memory: Kill process 23657 (NVS) score 754 or sacrifice child
/var/log/errors.log:91:Mar 27 15:35:36 HB-Sihua-41-New kernel: Out of memory: Kill process 13721 (NVS) score 753 or sacrifice child
/var/log/errors.log:97:May 10 16:34:06 HB-Sihua-41-New kernel: Out of memory: Kill process 22493 (NVS) score 731 or sacrifice child
/var/log/errors.log:99:May 31 14:42:18 HB-Sihua-41-New kernel: Out of memory: Kill process 32763 (NVS) score 731 or sacrifice child
/var/log/errors.log:101:May 31 14:42:18 HB-Sihua-41-New kernel: Out of memory: Kill process 339 (NVS) score 731 or sacrifice child
/var/log/errors.log:103:Jun 6 09:18:37 HB-Sihua-41-New kernel: Out of memory: Kill process 15350 (NVS) score 730 or sacrifice child
/var/log/errors.log:105:Jun 6 09:54:35 HB-Sihua-41-New kernel: Out of memory: Kill process 18984 (NVS) score 721 or sacrifice child
/var/log/kern.log:23017:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25976 (NVS) score 807 or sacrifice child
/var/log/kern.log:24011:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25985 (event poller 0) score 808 or sacrifice child
/var/log/kern.log:25026:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25996 (event poller 11) score 808 or sacrifice child
/var/log/kern.log:25071:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25997 (event poller 12) score 808 or sacrifice child
/var/log/kern.log:25668:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 26020 (event poller 0) score 808 or sacrifice child
/var/log/kern.log:25714:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 26032 (event poller 0) score 808 or sacrifice child
/var/log/kern.log:31826:Sep 29 14:49:57 HB-Sihua-41-New kernel: Out of memory: Kill process 26064 (event poller 0) score 810 or sacrifice child
/var/log/kern.log:197530:Dec 26 10:06:01 HB-Sihua-41-New kernel: Out of memory: Kill process 28075 (NVS) score 766 or sacrifice child
/var/log/kern.log:198136:Feb 14 13:05:33 HB-Sihua-41-New kernel: Out of memory: Kill process 5787 (NVS) score 630 or sacrifice child
/var/log/kern.log:202077:Feb 14 15:59:14 HB-Sihua-41-New kernel: Out of memory: Kill process 2679 (NVS) score 626 or sacrifice child
/var/log/kern.log:202121:Feb 14 16:42:37 HB-Sihua-41-New kernel: Out of memory: Kill process 2679 (NVS) score 633 or sacrifice child
/var/log/kern.log:202167:Feb 27 18:20:57 HB-Sihua-41-New kernel: Out of memory: Kill process 23657 (NVS) score 754 or sacrifice child
/var/log/kern.log:202207:Mar 27 15:35:36 HB-Sihua-41-New kernel: Out of memory: Kill process 13721 (NVS) score 753 or sacrifice child
/var/log/kern.log:202256:May 10 16:34:06 HB-Sihua-41-New kernel: Out of memory: Kill process 22493 (NVS) score 731 or sacrifice child
/var/log/kern.log:202302:May 31 14:42:18 HB-Sihua-41-New kernel: Out of memory: Kill process 32763 (NVS) score 731 or sacrifice child
/var/log/kern.log:202349:May 31 14:42:18 HB-Sihua-41-New kernel: Out of memory: Kill process 339 (NVS) score 731 or sacrifice child
/var/log/kern.log:202400:Jun 6 09:18:37 HB-Sihua-41-New kernel: Out of memory: Kill process 15350 (NVS) score 730 or sacrifice child
/var/log/kern.log:203269:Jun 6 09:54:35 HB-Sihua-41-New kernel: Out of memory: Kill process 18984 (NVS) score 721 or sacrifice child
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~ matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~ matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-00000000000a4a2a-0005fcb6af7eaaec.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-0000000000000001-0005f4a4f21e9703.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@0af73aa4311e49609a688009f00bb9f5-0000000000000001-0005e9cb490d0d5e.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000004e32a-0005f70958e9ff64.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@8ac08d6c0c0e4039b0a5862683a688c7-0000000000000001-0005f0b19080bbfc.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000009060f-0005face6cf2a459.journal matches
/var/log/
28:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25976 (NVS) score 807 or sacrifice child
30:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25985 (event poller 0) score 808 or sacrifice child
32:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25996 (event poller 11) score 808 or sacrifice child
34:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25997 (event poller 12) score 808 or sacrifice child
36:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 26020 (event poller 0) score 808 or sacrifice child
38:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 26032 (event poller 0) score 808 or sacrifice child
40:Sep 29 14:49:57 HB-Sihua-41-New kernel: Out of memory: Kill process 26064 (event poller 0) score 810 or sacrifice child
71:Dec 26 10:06:01 HB-Sihua-41-New kernel: Out of memory: Kill process 28075 (NVS) score 766 or sacrifice child
77:Feb 14 13:05:33 HB-Sihua-41-New kernel: Out of memory: Kill process 5787 (NVS) score 630 or sacrifice child
79:Feb 14 15:59:14 HB-Sihua-41-New kernel: Out of memory: Kill process 2679 (NVS) score 626 or sacrifice child
82:Feb 14 16:42:37 HB-Sihua-41-New kernel: Out of memory: Kill process 2679 (NVS) score 633 or sacrifice child
88:Feb 27 18:20:57 HB-Sihua-41-New kernel: Out of memory: Kill process 23657 (NVS) score 754 or sacrifice child
91:Mar 27 15:35:36 HB-Sihua-41-New kernel: Out of memory: Kill process 13721 (NVS) score 753 or sacrifice child
97:May 10 16:34:06 HB-Sihua-41-New kernel: Out of memory: Kill process 22493 (NVS) score 731 or sacrifice child
99:May 31 14:42:18 HB-Sihua-41-New kernel: Out of memory: Kill process 32763 (NVS) score 731 or sacrifice child
101:May 31 14:42:18 HB-Sihua-41-New kernel: Out of memory: Kill process 339 (NVS) score 731 or sacrifice child
103:Jun 6 09:18:37 HB-Sihua-41-New kernel: Out of memory: Kill process 15350 (NVS) score 730 or sacrifice child
105:Jun 6 09:54:35 HB-Sihua-41-New kernel: Out of memory: Kill process 18984 (NVS) score 721 or sacrifice child
/var/log/errors.log
23017:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25976 (NVS) score 807 or sacrifice child
24011:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25985 (event poller 0) score 808 or sacrifice child
25026:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25996 (event poller 11) score 808 or sacrifice child
25071:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 25997 (event poller 12) score 808 or sacrifice child
25668:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 26020 (event poller 0) score 808 or sacrifice child
25714:Sep 29 14:49:56 HB-Sihua-41-New kernel: Out of memory: Kill process 26032 (event poller 0) score 808 or sacrifice child
31826:Sep 29 14:49:57 HB-Sihua-41-New kernel: Out of memory: Kill process 26064 (event poller 0) score 810 or sacrifice child
197530:Dec 26 10:06:01 HB-Sihua-41-New kernel: Out of memory: Kill process 28075 (NVS) score 766 or sacrifice child
198136:Feb 14 13:05:33 HB-Sihua-41-New kernel: Out of memory: Kill process 5787 (NVS) score 630 or sacrifice child
202077:Feb 14 15:59:14 HB-Sihua-41-New kernel: Out of memory: Kill process 2679 (NVS) score 626 or sacrifice child
202121:Feb 14 16:42:37 HB-Sihua-41-New kernel: Out of memory: Kill process 2679 (NVS) score 633 or sacrifice child
202167:Feb 27 18:20:57 HB-Sihua-41-New kernel: Out of memory: Kill process 23657 (NVS) score 754 or sacrifice child
202207:Mar 27 15:35:36 HB-Sihua-41-New kernel: Out of memory: Kill process 13721 (NVS) score 753 or sacrifice child
202256:May 10 16:34:06 HB-Sihua-41-New kernel: Out of memory: Kill process 22493 (NVS) score 731 or sacrifice child
202302:May 31 14:42:18 HB-Sihua-41-New kernel: Out of memory: Kill process 32763 (NVS) score 731 or sacrifice child
202349:May 31 14:42:18 HB-Sihua-41-New kernel: Out of memory: Kill process 339 (NVS) score 731 or sacrifice child
202400:Jun 6 09:18:37 HB-Sihua-41-New kernel: Out of memory: Kill process 15350 (NVS) score 730 or sacrifice child
203269:Jun 6 09:54:35 HB-Sihua-41-New kernel: Out of memory: Kill process 18984 (NVS) score 721 or sacrifice child
/var/log/kern.log
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~ matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~ matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-00000000000a4a2a-0005fcb6af7eaaec.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-0000000000000001-0005f4a4f21e9703.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@0af73aa4311e49609a688009f00bb9f5-0000000000000001-0005e9cb490d0d5e.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000004e32a-0005f70958e9ff64.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@8ac08d6c0c0e4039b0a5862683a688c7-0000000000000001-0005f0b19080bbfc.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000009060f-0005face6cf2a459.journal matches
/var/log/journal
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~ matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~ matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-00000000000a4a2a-0005fcb6af7eaaec.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-0000000000000001-0005f4a4f21e9703.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@0af73aa4311e49609a688009f00bb9f5-0000000000000001-0005e9cb490d0d5e.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000004e32a-0005f70958e9ff64.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@8ac08d6c0c0e4039b0a5862683a688c7-0000000000000001-0005f0b19080bbfc.journal matches
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000009060f-0005face6cf2a459.journal matches
/var/log/journal/2d373eb792a749f68374f19577cd62be
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~ matches
/var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~ matches
/var/log/journal/2d373eb792a749f68374f19577cd62be/[email protected]~
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-00000000000a4a2a-0005fcb6af7eaaec.journal matches
/var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-00000000000a4a2a-0005fcb6af7eaaec.journal
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-0000000000000001-0005f4a4f21e9703.journal matches
/var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-0000000000000001-0005f4a4f21e9703.journal
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@0af73aa4311e49609a688009f00bb9f5-0000000000000001-0005e9cb490d0d5e.journal matches
/var/log/journal/2d373eb792a749f68374f19577cd62be/system@0af73aa4311e49609a688009f00bb9f5-0000000000000001-0005e9cb490d0d5e.journal
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000004e32a-0005f70958e9ff64.journal matches
/var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000004e32a-0005f70958e9ff64.journal
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@8ac08d6c0c0e4039b0a5862683a688c7-0000000000000001-0005f0b19080bbfc.journal matches
/var/log/journal/2d373eb792a749f68374f19577cd62be/system@8ac08d6c0c0e4039b0a5862683a688c7-0000000000000001-0005f0b19080bbfc.journal
Binary file /var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000009060f-0005face6cf2a459.journal matches
/var/log/journal/2d373eb792a749f68374f19577cd62be/system@b402138a680c40cea8e628aba4cc2d9b-000000000009060f-0005face6cf2a459.journal
假如环境使用了java应用,执行:jstat -gcutil pid 500 5 ,表示每500毫秒打印一次Java堆状况(各个区的容量、使用容量、gc时间等信息),打印5次;jmap -histo pid,打印出当前堆中所有每个类的实例数量和内存占用
jmap -dump:format=b,file=文件名 [pid],可以把指定java进程的堆内存快照搞到一个指定的文件里去,也可以用gcore工具来导出内存快照,然后用MAT工具/Eclipse MAT的内存分析插件,来对导出的文件进行分析去分析,确定导致OOM的对象;
假如说大量的对象涌入内存,结果始终不能回收,会出现的情况就是,快速撑满年轻代,然后young gc几次,根本回收不了什么对象,导致survivor区根本放不下,然后大量对象涌入老年代。老年代很快也满了,然后就频繁full gc,但是也回收不掉,最后对象持续增加最终就会导致oom。线上环境建议:jvm必须配置-XX:+HeapDumpOnOutOfMemoryError,-XX:HeapDumpPath=/path/heap/dump。因为这样就是说OOM的时候自动导出一份内存快照,你就可以分析发生OOM时的内存快照了,到底是哪里出现的问题。必要时,分析gc日志,可配置加上一些jvm的参数,让线上系统定期打出来gc的日志,一般常见线上系统经常卡顿,就可查看gc日志分析:
-XX:+PrintGCTimeStamps
-XX:+PrintGCDeatils
-Xloggc:
更多参看:OOM内存溢出问题
注,另外还可以搜搜关键词:No swap limit support,No space left on device
find /var/log/ -exec grep -irn "No space left on device" {
} \; -print
find /var/log/ -exec grep -irn "No swap limit support" {
} \; -print
4)历史监控信息










近7日情况:




近30天的趋势:




手动分析:
ps -eo pid,cmd,%mem,%cpu --sort=-%mem #内存

pmap -x pid #pmap 命令可以打印一个进程的内存映射表,显示进程使用的虚拟内存和物理内存情况
26113: /opt/vpm/NVS/NVS
Address Kbytes RSS Dirty Mode Mapping
0000558a9a6df000 7600 1960 0 r---- NVS
0000558a9ae4b000 12468 2716 0 r-x-- NVS
0000558a9ba78000 4336 388 0 r---- NVS
0000558a9beb5000 400 400 400 r---- NVS
0000558a9bf19000 32 24 24 rw--- NVS
yum install htop -y #使用htop命令

pert top 分析观察热点函数使用率
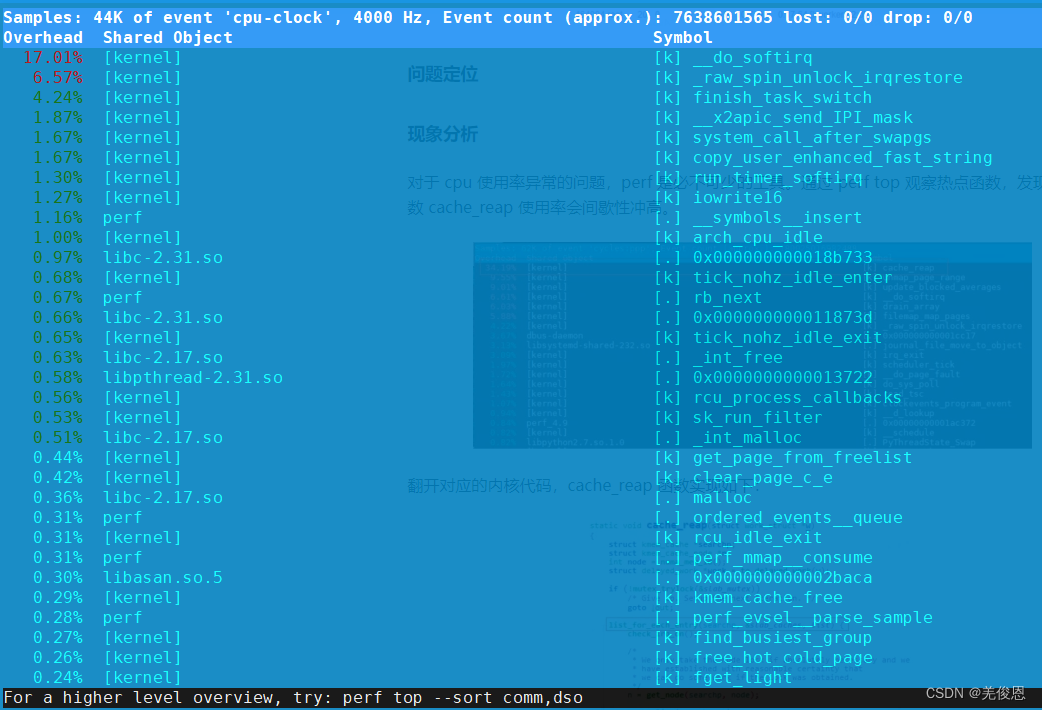
#即使节点有足够的内存,也会出现下面报错
…… kernel: SLUB: Unable to allocate memory on node -1 (gfp=0x20)
…… kernel: cache: kmalloc-256, object size: 256, buffer size: 256, default order: 1, min order: 0
…… kernel: node 0: slabs: 1550, objs: 45776, free: 0
cat /etc/sysctl.conf #系统配置
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_max_syn_backlog = 4096
net.core.somaxconn = 1024
net.ipv4.tcp_syncookies = 1
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 65535
net.core.wmem_default = 65535
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.ip_local_port_range = 1024 65535
vm.max_map_count = 262144
vm.swappiness=10
vm.vfs_cache_pressure=100
其他参考:kmem_cache_alloc, slub: make dead caches discard free slabs immediately;
cat /proc/cgroup #查看系统的当前 cgroup 信息,确认 memory cgroup 数量,正常情况下,下图为7

tree -d|wc -l #查看cgroup下memory数量,与上面对比,正常应该偏差不大
5)可能原因
综上,结合本次故障日志丢失,即未存储到磁盘,可能出现磁盘日志占满的情况,虽然监控里未出现;另历史趋势里负载明显异常的就是cpu,几乎耗尽,假设应用日志占满,导致后续日志无法写入,正常情况日志会继续写入内存中,极端情况下也会导致内存耗尽;如果是应用cgroup限制问题,也会导致OOM;因本台主机是udp主要连接,也可能udp连接数过多导致OOM;不过通过日志丢失(也可能rsyslog进程被杀死,不过可能性很低),那就是存储问题;另,相关经验表明,kmem account在RHEL 3.10内核中是不稳定的,存在bug,如果开启了 kmem account 特性 会导致可分配内存越来越少,导致OOM,现场内核版本正是3.10.0-1160.25.1.el7.x86_64,该bug已在4.0中修复;

原因1:应用程序内存泄漏。如果应用程序在运行时不断分配内存,但不释放,就会导致内存泄漏,最终耗尽系统内存资源,引起 OOM 错误。
原因2:系统资源限制不足。如果操作系统中对应用程序的资源限制(例如 ulimit,cgroup)不够大,也可能导致 OOM 错误。
原因3:应用程序运行环境配置不合理。如果应用程序的运行环境配置不合理,如 JVM 的 Heap 大小设置过小,也可能导致 OOM 错误。现场环境不涉及,可排除;
原因4:内核对于每个 cgroup 子系统的的条目数是有限制的,限制的大小定义在 kernel/cgroup.c #L139,当正常在 cgroup 创建一个 group 的目录时,条目数就加1。我们遇到的情况就是因为开启了 kmem accounting 功能,虽然 cgroup 的目录删除了,但是条目没有回收。这样后面就无法创建65535个 cgroup 了。也就是说,在当前3.10 内核版本下,开启了 kmem accounting 功能,会导致 memory cgroup 的条目泄漏无法回收。明显的现象就是,执行 dmesg 有日志显示:slub无法分配内存:SLUB: Unable to allocate memory on node -1;每一个 memory cgroup 都会对应一个 memory.kmem.slabinfo 文件;
kmem account 是cgroup 的一个扩展,全称CONFIG_MEMCG_KMEM,属于OS默认配置,本身没啥问题,只是该特性在 3.10 的内核上存在漏洞有内存泄露问题,4.x的内核修复了这个问题。相关解释如下:slub: make dead caches discard free slabs immediately,1;Cgroup泄漏,runc社区,Changing cgroup
原因5:docker创建时通过 cgroup memory申请的slab,但是docker关闭时,这些slab却没有释放。导致越积越多,将内存消耗殆尽。如果系统上的很多操作(如创建销毁容器/云主机、登录宿主机、cron 定时任务等)都会触发创建临时的 memory cgroup。这些 memory cgroup 组内的进程在运行过程中可能会产生 cache 内存(如访问文件、创建新文件等),该 cache 内存会关联到该 memory cgroup。当 memory cgroup 组内进程退出后,该 cgroup 组在/sys/fs/cgroup/memory 目录下对应的目录会被删除。但该 memory cgroup 组产生的 cache 内存并不会被主动回收,由于有 cache 内存还在引用该 memory cgroup 对象,所以也就不会删除该 memory cgroup 在内存中的对象。

常见两个触发源会导致 memory cgroup 泄露:
1、特定的 cron 定时任务执行
2、用户频繁登录和退出主机
以上2个且都是跟 systemd-logind 登录服务有关系,执行 cron 定时任务或者是登录宿主机时,systemd-logind 服务都会创建临时的 memory cgroup,待 cron 任务执行完或者是用户退出登录后,会删除临时的 memory cgroup,在有文件操作的场景下会导致 memory cgroup 泄漏。
复现方法:(来源网络)

通过以上操作,创建临时 memory cgroup,并进行文件操作产生 cache 内存,然后删除 memory cgroup 临时目录,通过以上的方式,在测试环境能够很快的复现 40w memory cgroup 残留的现场。更多参看memory cgroup
6)其他相关经验:
慢查询 -> cpu过高 -> 影响其他查询 -> 连接释放不及时 -> 连接数飙升 -> 数据量大导致内存飙升 -> OOM -> 宕机 -> 日志检查最早记录的慢sql -> 回到代码分析
7)处理
1、升级内核到4.0以上,最好是升级到最新稳定版;修改/boog/grub2/grub.cfg 增加 cgroup_disable=memory 后,重启系统
2、启动容器时禁用kmem记数功能,关闭 runc 和 kubelet 的 kmem account,k8s中(runc) 默认已启用。即docker/runc 禁用 KernelMemoryAccounting 功能,kernel 提供了 cgroup.memory = nokmem 参数,关闭 kmem accounting 功能,配置该参数后,memory cgroup 就不会有单独的 slabinfo 文件,这样即使出现 memory cgroup 泄露,也不会导致 kworker 线程 CPU 冲高了。但该方案需要重启系统才能生效,对业务会有一定影响,且该方案并不能完全解决 memory cgroup 泄露这个根本性的问题,只能在一定程度缓解问题。
3、 docker-ce 使用 v18.09.1 以上版本后,Docker中就禁用了runc的kmem计数;现场版本为20.10.16, build aa7e414,正常不受该影响;
4、如果是cgroup 泄露导致的,而它又是由于 cache 内存无法回收引起的,那么最直接的方案就是通过“echo 3 > /proc/sys/vm/drop_caches”清理系统缓存;注意:drop cache 动作本身也会消耗大量 cpu 对业务造成影响,而对于已经形成了大量 cgroup 泄漏的节点,drop cache 动作可能卡在清理缓存的流程中,造成新的问题。
5、消除触发源,关闭 cron 任务;
6、对频繁登录主机的,可执行loginctl enable-linger username 将对应用户设置成后台常驻用户来解决。设置成常驻用户后,用户登录时,systemd-logind 服务会为该用户创建一个永久的 memory cgroup 组,用户每次登录时都可以复用这个 memory cgroup 组,用户退出后也不会删除,所以也就不会出现泄漏。
cat /sys/fs/cgroup/memory/docker/8e4cf2c25e46132adbdfc7b80bdeff3aaa46e1610a327edfceeb9bc8b922fd85/memory.kmem.slabinfo //输出下面的就飙升kmem accounting 关闭
cat: /sys/fs/cgroup/memory/docker/8e4cf2c25e46132adbdfc7b80bdeff3aaa46e1610a327edfceeb9bc8b922fd85/memory.kmem.slabinfo: Input/output error
cat /sys/fs/cgroup/memory/memory.kmem.slabinfo //输出如下,表 kmem accounting feature is disabled successfully:
cat: /sys/fs/cgroup/memory/memory.kmem.slabinfo: Input/output error
cat /sys/fs/cgroup/memory/docker/memory.kmem.slabinfo
cat: /sys/fs/cgroup/memory/docker/memory.kmem.slabinfo: Input/output error
//如果存在内存泄露会出现
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
三、附录:
3.1、调整参数配置 OOM killer
我们可以通过一些内核参数来调整 OOM killer 的行为,避免系统在那里不停的杀进程。比如我们可以在触发 OOM 后立刻触发 kernel panic,kernel panic 10秒后自动重启系统。
sysctl -w vm.panic_on_oom=1 #输出如下
vm.panic_on_oom = 1
sysctl -w kernel.panic=10 #输出如下
kernel.panic = 10
echo "vm.panic_on_oom=1" >> /etc/sysctl.conf
echo "kernel.panic=10" >> /etc/sysctl.conf
从 oom_kill.c 代码里可以看到 oom_badness() 会给每个进程打分,根据 points 的高低来决定杀哪个进程,这个 points 可以根据 adj 调节,root 权限的进程通常被认为很重要,不应该被轻易杀掉,所以打分的时候可以得到 3% 的优惠(adj -= 30; 分数越低越不容易被杀掉)。我们可以在用户空间通过操作每个进程的 oom_adj 内核参数来决定哪些进程不这么容易被 OOM killer 选中杀掉。比如,如果不想 Nginx进程被轻易杀掉的话可以找到 Nginx 运行的进程号后,调整 oom_score_adj 为 -15(注意 points 越小越不容易被杀):
ps aux | grep nginx
cat /proc/23503/oom_score_adj #一般是0
echo -15 > /proc/23503/oom_score_adj
当然,你也可以完全关闭 OOM killer(严禁用在生产环境):
sysctl -w vm.overcommit_memory=2 #或者
echo "vm.overcommit_memory=2" >> /etc/sysctl.conf
3.2、slub: make dead caches discard free slabs immediately
To speed up further allocations SLUB may store empty slabs in per cpu/node
partial lists instead of freeing them immediately. This prevents per
memcg caches destruction, because kmem caches created for a memory cgroup
are only destroyed after the last page charged to the cgroup is freed.
To fix this issue, this patch resurrects approach first proposed in [1].
It forbids SLUB to cache empty slabs after the memory cgroup that the
cache belongs to was destroyed. It is achieved by setting kmem_cache's
cpu_partial and min_partial constants to 0 and tuning put_cpu_partial() so
that it would drop frozen empty slabs immediately if cpu_partial = 0.
The runtime overhead is minimal. From all the hot functions, we only
touch relatively cold put_cpu_partial(): we make it call
unfreeze_partials() after freezing a slab that belongs to an offline
memory cgroup. Since slab freezing exists to avoid moving slabs from/to a
partial list on free/alloc, and there can't be allocations from dead
caches, it shouldn't cause any overhead. We do have to disable preemption
for put_cpu_partial() to achieve that though.
The original patch was accepted well and even merged to the mm tree.
However, I decided to withdraw it due to changes happening to the memcg
core at that time. I had an idea of introducing per-memcg shrinkers for
kmem caches, but now, as memcg has finally settled down, I do not see it
as an option, because SLUB shrinker would be too costly to call since SLUB
does not keep free slabs on a separate list. Besides, we currently do not
even call per-memcg shrinkers for offline memcgs. Overall, it would
introduce much more complexity to both SLUB and memcg than this small
patch.
Regarding to SLAB, there's no problem with it, because it shrinks
per-cpu/node caches periodically. Thanks to list_lru reparenting, we no
longer keep entries for offline cgroups in per-memcg arrays (such as
memcg_cache_params->memcg_caches), so we do not have to bother if a
per-memcg cache will be shrunk a bit later than it could be.
3.3、内存泄漏分析工具
3.4、内存管理——Slab分配器
参看:https://zhuanlan.zhihu.com/p/629760989
3.5、docker的namespace和cgroup总结及资源限制
参看:https://blog.51cto.com/taokey/3831327;深入理解DOCKER容器引擎RUNC执行框架,docker 容器运行限制