作者 | 小戏、Python
理想化的 Learning 的理论方法作用于现实世界总会面临着诸多挑战,从模型部署到模型压缩,从数据的可获取性到数据的隐私问题。而面对着公共领域数据的稀缺性以及私有领域的数据隐私问题,联邦学习(Federated Learning)作为一种分布式的机器学习框架吸引了许多关注。
而伴随着大模型的出现与逐渐成熟,大规模语言模型(LLMs)对更大规模训练数据的依赖以及数据隐私与商业竞争问题,催生了一个新的问题,如何在不侵犯数据隐私法律条款的基础上,利用各个商业实体私人领域的孤立数据联合训练一个大规模语言模型?想象一个场景,有三家医院想训练一款专门针对医学领域的大模型,但是每家医院所拥有的数据都不足以支撑大模型所需要的数据要求,而完全共享三家医院的数据由于数据隐私问题又不现实,在这个大背景下,就需要一种基于联邦学习的大规模语言模型的训练架构与方法,解决分布式的大模型训练问题。
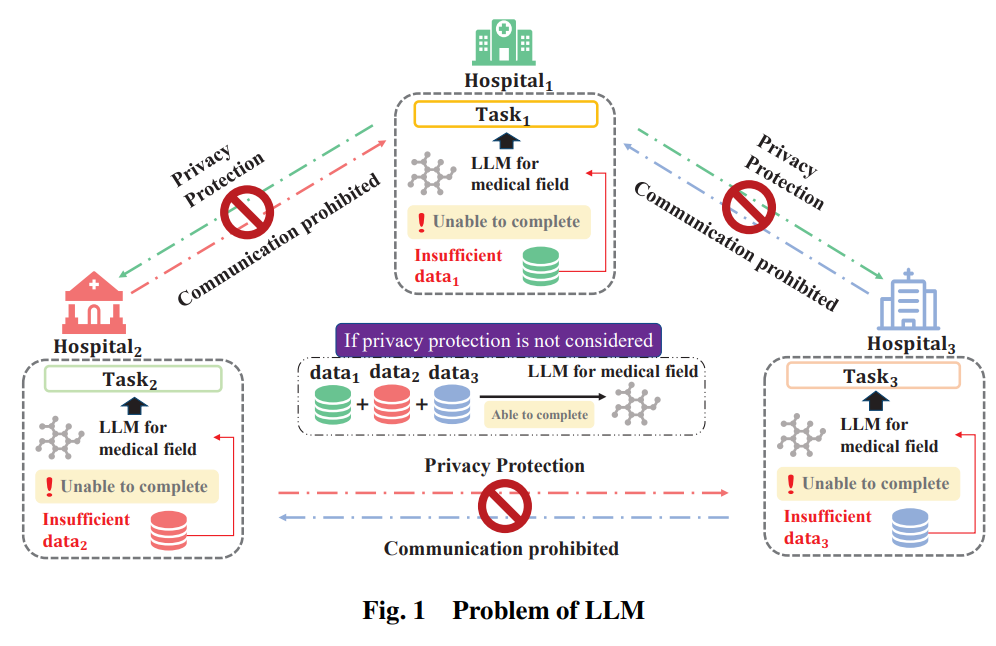
面对这个问题,浙江大学提出了联邦 LLMs 的概念,构建了联邦 LLM 的三个组成部分包括联邦 LLM 预训练、联邦 LLM 微调以及 联邦 LLM Prompt 工程。对于每个组成部分,论文讨论了它相对于传统 LLMs 训练方法的优势,并提出了具体的工程策略实现方法。最后,面对联邦学习与 LLMs 的集成,论文提出了两个领域联合带来的新有待解决的挑战及潜在解决方案。
论文题目:
Federated Large Language Model : A Position Paper
论文链接:
https://arxiv.org/pdf/2307.08925.pdf
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
Hello, GPT4!
从联邦学习到联邦 LLMs
隐私保护计算,是一种为了解决利用私人领域数据开展模型训练,维护数据隐私的计算技术,目前隐私保护计算的方法主要有基于密码学的方法、利用可信硬件的方法以及联邦学习的方法。而大模型庞大的计算需求限制了密码学方法与硬件方法在大模型训练之中的应用,而联邦学习作为一种平衡效率与隐私安全的成熟架构,非常有潜力应用于大模型的隐私保护计算。
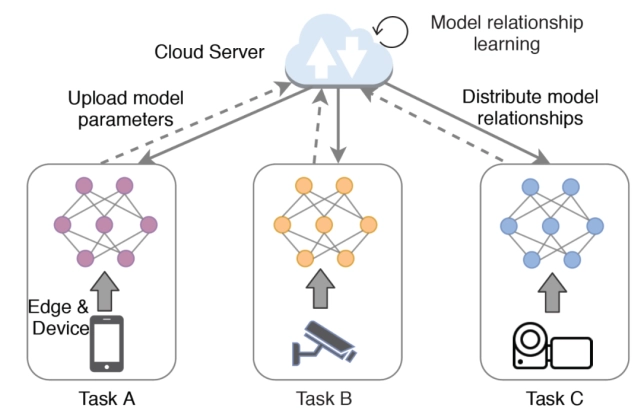
联邦学习作为一种机器学习范式,完成由多个客户端共同合作训练一个由中央服务器监督的共享模型的任务。于传统集中式的机器学习方法相比,联邦学习允许数据在本地存储,从而减少相关的隐私风险。在联邦学习之中,客户端的设备异步的对如网络权重与梯度等信息进行更新,以最小化数据泄露的风险并减少带宽需求,常见的联邦学习算法有联邦平均算法、差分隐私等等。
相应的,如果希望完成一个大规模语言模型的训练任务,一般可以分为三个阶段,分别是预训练、自适应微调以及应用。在预训练阶段,模型使用无标签的文本数据进行无监督的训练以获得有关语言的基础知识,而自适应微调则从特定领域或下游任务的实际需求出发,通过对骨干网络参数进行冻结,或使用不同的 Prompt 对模型输出进行调整。
综合联邦学习与大规模语言模型的思想,论文作者对在联邦学习框架之中的 LLM 的训练过程进行了详细的研究,具体的,作者关注了联邦 LLMs 的三个关键组成部分:联邦 LLM 预训练、联邦 LLM 微调以及 联邦 LLM Prompt 工程。
联邦 LLMs 架构设计
传统的大模型训练面对的显著挑战之一,就是高质量的训练数据稀缺的问题,通常,这些模型在训练阶段都会依赖公开可用的数据集,比如维基百科、书籍、源代码等等,而最近也有研究表明,高质量的语言数据有可能在 2026 年达到枯竭点,而更低质量的数据也将在 2030 年到 2050 年间耗尽。
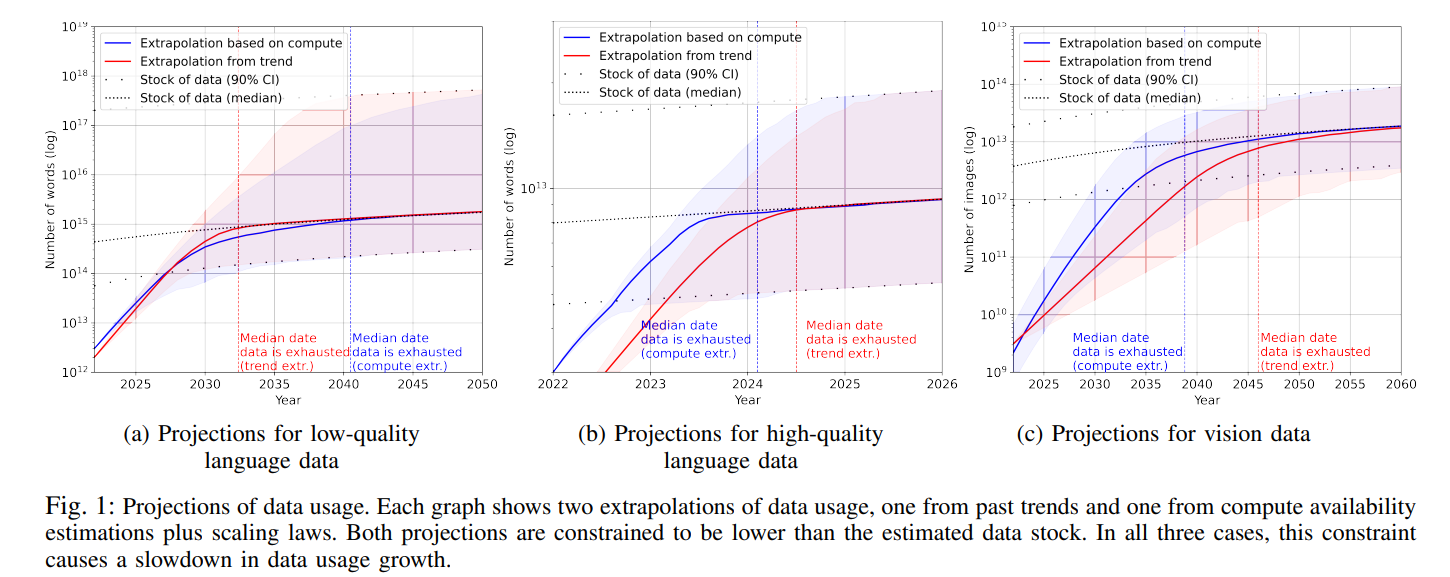
在这个背景下,联邦 LLM 预训练通过结合集中式公开数据源以及分散式私有数据源可以极大的提高模型的泛化能力并未模型的未来可扩展性奠定基础。具体而言,作者设计的联邦 LLM 预训练包含两种实现方法,其中第一种方法是从多个客户端的原始数据开始,通过数据预处理、LLM 架构设计与任务设计进行模型预训练,而在服务端接受各个客户端的梯度信息通过聚合与计算回传到各个客户端,这种方法预设了大量的计算与通信开销。而第二种方法是不重新训练一个 LLM,而是使用现有的开源模型,直接在开源模型的基础之上进行微调,第一种方法具有更好的潜在性能并且支持自定义模型架构,而第二种方法降低了开销但是牺牲了一定的任务适应性。联邦 LLM 预训练方法如下图左所示:
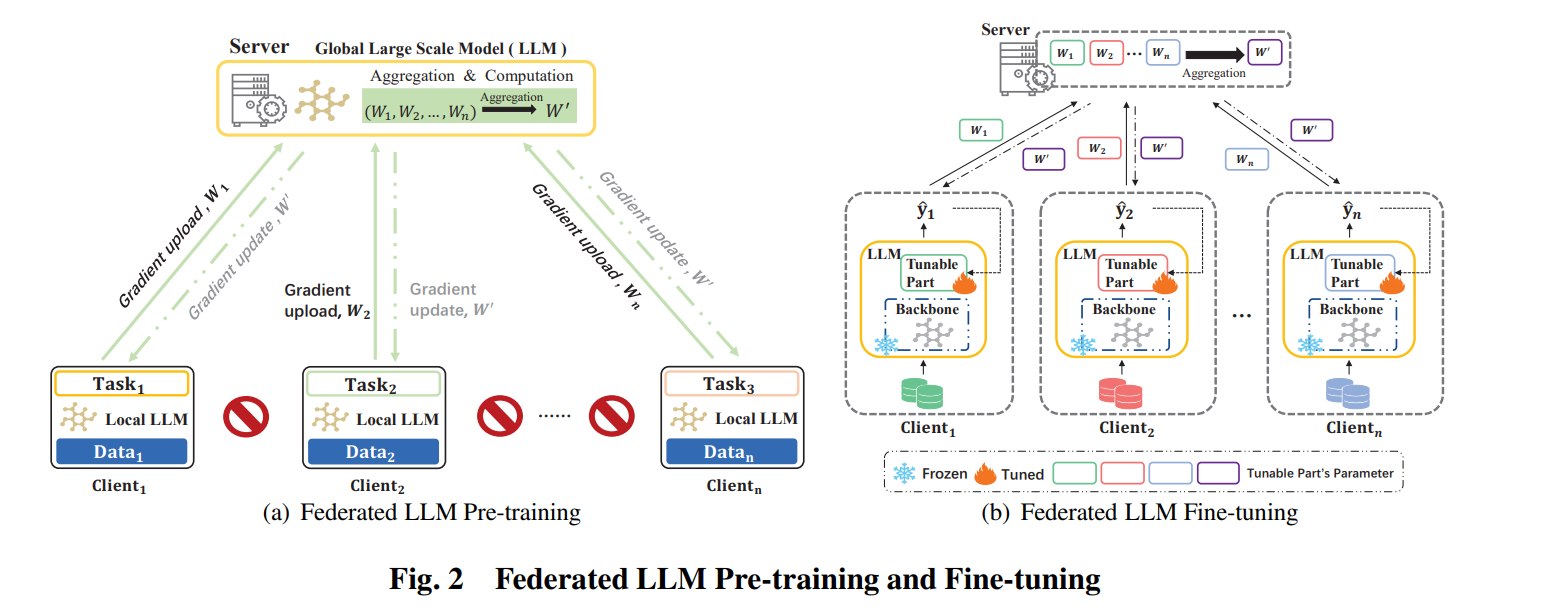
在联邦 LLM 微调之中,需要解决的关键问题在于不同客户端之间的合作问题,论文提出了两种联邦 LLM 微调方法,分别是各个客户端复制预训练模型,进行全模型微调以及将参数高效微调方法与联邦学习框架结构,利用如 LoRA 的方法减少计算与通信成本,在保持计算性能与减少成本间保持了平衡整体方法如上图右所示。
最后,为了应用 Prompt 技术增强模型的上下文学习与处理复杂任务的能力,作者提出了一种联邦 LLM 提示工程方法,在敏感数据上生成 Prompt 的同时确保隐私被保护。从下图可以看到,从客户端到服务端传递的参数只涉及 Prompt 与文本的相互关系,并不包含任何输入特征的嵌入。同时,在联邦 Prompt 工程中,作者采用了 Soft Prompt(Prompt 在模型的嵌入空间中执行),Soft Prompt 完美适配联邦学习的背景要求增强了联邦学习与大模型的协同作用。

联邦 LLMs 的挑战
当前联邦学习与大模型的结合还面临着许多挑战,具体而言,作者将这些问题归类为安全威胁及安全防御、隐私威胁与隐私增强、效率问题以及处理非独立同分布(Non-IID)数据四大挑战。
其中,安全威胁主要指潜在的攻击者利用漏洞来破坏系统安全与隐私政策,在联邦学习框架下,已经有如毒化攻击(Poisoning attacks)、对抗样本攻击(Adversarial sample attacks)等攻击方式,不同的攻击方式会影响联邦学习不同的训练阶段
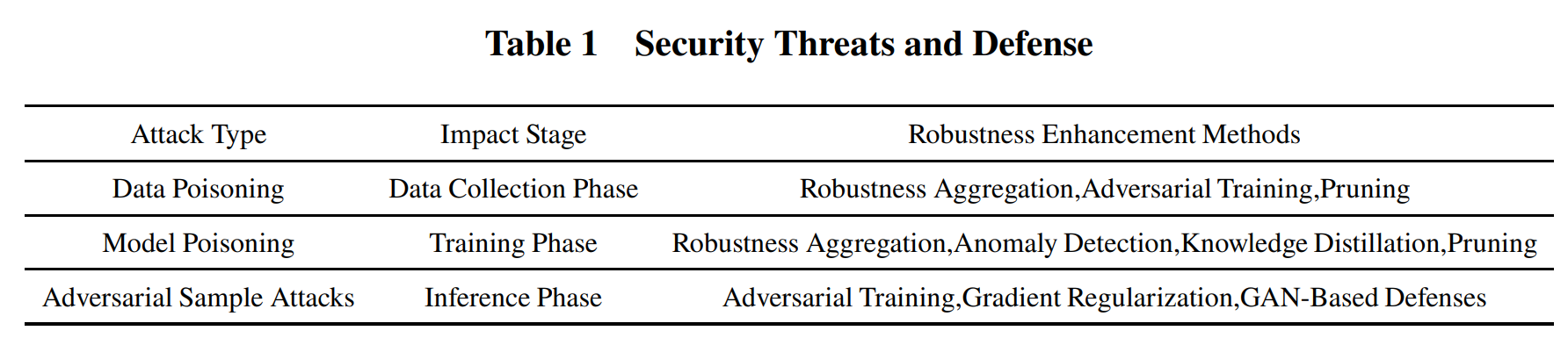
毒化攻击可以分为数据毒化攻击与模型毒化攻击,其中数据毒化攻击发生在数据收集的初始阶段,恶意者会向联邦数据集中引入损坏的数据样本。相反,模型毒化攻击通过向全局模型注入恶意参数或梯度来破坏模型的完整性,阻碍学习的进程。而对抗样本攻击主要发生在推理阶段,对抗样本攻击通过对样本的微小扰动旨在欺骗训练好的模型,导致错误的预测。这些攻击方法在 Transformer 架构下普遍存在,并且在联邦 LLMs 之中成功率会更加高也更加难以检测,联邦学习分布式的训练模式增加了模型参数泄露的可能性,使得模型容易受到白盒攻击。相应的,目前对这些安全威胁的主要应对措施包括数据清晰、鲁棒聚合、对抗训练等等,但是有些应对方法有时又与联邦学习的目标相违背,这为应对安全威胁的实践带来了挑战
而隐私威胁,主要指未经授权的对敏感信息的访问对模型目标带来的潜在危害,这些隐私攻击旨在于联邦学习的不同阶段获取隐私信息与其他利益,主要包括样本隐私泄露、生成对抗网络攻击、推断攻击与 Prompt 攻击等等。

联邦 LLMs 将会引入新的隐私威胁,如 LLM 可能会“无意”透露一些训练数据,如医疗记录与银行账户等,许多研究都证明了大模型有可能会生成敏感信息造成隐私泄露的问题,比如直接攻击,越狱攻击,道德攻击……这样做,ChatGPT 就会泄漏你的隐私,通过设计对 ChatGPT 不同的攻击方式,可以有效的获得敏感数据。对应的,隐私增强技术如同态加密、多方安全计算以及差分隐私等都可以帮助减轻联邦学习中的隐私威胁。但是在联邦 LLMs 下,由于模型参数的规模与模型的深度加深使得应用如差分隐私这类的方法将会使得模型的性能出现下降。
联邦 LLMs 面临的另一个显著挑战在于其通信开销方面,在大量设备与服务器之间梯度的更新与交换将会造成实质性的通信开销,延长通信时间使得联邦 LLMs 无法正常训练。在整个联邦 LLMs 的训练过程之中,可以采取多种方法优化模型的训练,如在预训练阶段可以采用模型并行、流水线并行等技术手段,将庞大模型参数分布在多个 GPU 之间,通过采用张量转移与优化器转移等技术,减少内存占用,加速模型的训练。此外,Non-IID 数据也会为联邦学习训练带来无法规避的挑战,对收敛速度与准确性产生不利的影响。
总结与讨论
这篇论文对联邦学习与大模型的结合做了提纲挈领的叙述,通过将联邦学习与大模型训练结合的基础框架划分为三个关键组件,在阐明了联邦 LLMs 的优势的同时,抛出了联邦学习与大模型两个领域“跨界”将会面临的新的问题。伴随着大模型技术的成熟,联邦 LLMs 也必然会逐步登上人们关注的日程表,期待这一领域未来更加细致与深入的工作。
