目录
3.2.1 Function(arg1,..., argn)
3.2.2 OVER [PARTITION BY <...>]
一、前言
在讲Flink的时候,我们聊到了窗口函数的使用,了解了窗口函数的作用,本篇来详细聊聊hive中窗口函数的使用。
二、hive 窗口函数概述
窗口函数(Window functions)也叫做开窗函数、OLAP函数,其最大特点是:输入值是从SELECT语句的结果集中的一行或多行的“窗口”中获取的。如果函数具有OVER子句,则它是窗口函数。
窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
结合下图,可以对比理解下普通聚合函数与窗口函数的作用;
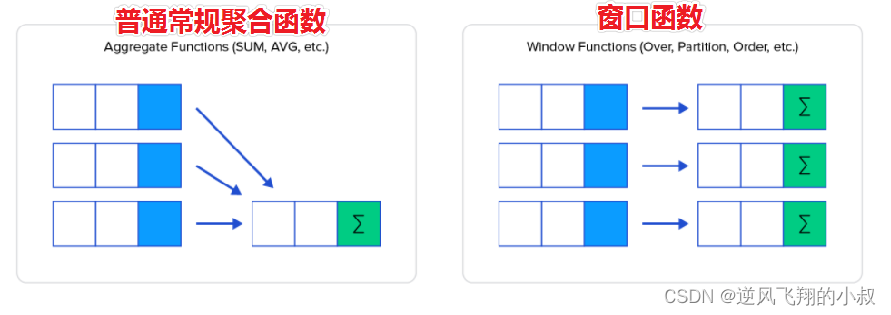
我们不妨通过两个sql来直观感受下普通聚合函数与窗口函数的差异所在;
2.1 聚合函数与窗口函数差别
下面用一个实例演示下
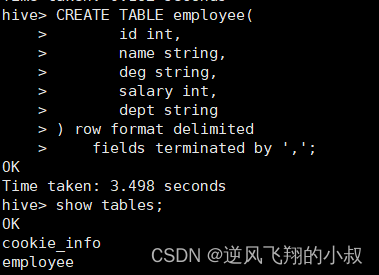
2.1.1 创建一张表
CREATE TABLE employee(
id int,
name string,
deg string,
salary int,
dept string
) row format delimited
fields terminated by ',';执行sql进行创建
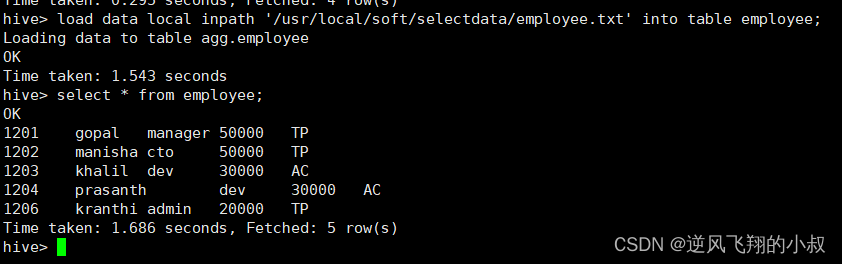
2.1.2 加载数据到表中
load data local inpath '/usr/local/soft/selectdata/employee.txt' into table employee;
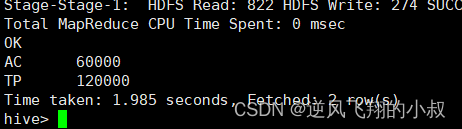
2.1.3 sum+group by普通常规聚合操作
select dept,sum(salary) as total from employee group by dept;执行结果
2.1.4 sum+窗口函数聚合操作
select id,name,deg,salary,dept,sum(salary) over(partition by dept) as total from employee;执行结果
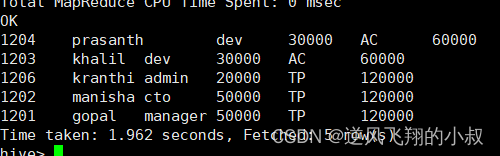
对比上面两个sql的执行结果可以发现,窗口函数的聚合能够反馈出更多的中间信息,这在某些需要展示更多字段信息场景的情况下是很有用处的。
三、窗口函数
3.1 窗口函数语法
窗口函数完整语法树如下
Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>])
3.2 参数说明
3.2.1 Function(arg1,..., argn)
可以是下面分类中的任意一个
--聚合函数:比如sum max avg等
--排序函数:比如rank row_number等
--分析函数:比如lead lag first_value等
3.2.2 OVER [PARTITION BY <...>]
1、类似于group by 用于指定分组 每个分组你可以把它叫做窗口;
2、如果没有PARTITION BY 那么整张表的所有行就是一组;
3.2.3 [ORDER BY <....>]
用于指定每个分组内的数据排序规则 支持ASC、DESC
3.2.4 [<window_expression>]
用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
3.3 窗口函数使用操作演示
3.3.1 数据准备
建立两张表,并加载数据,一张是网站的pv数据,一张是访问网站的url信息;
create table website_pv_info(
cookieid string,
createtime string, --day
pv int
) row format delimited
fields terminated by ',';
create table website_url_info (
cookieid string,
createtime string, --访问时间
url string --访问页面
) row format delimited
fields terminated by ',';
load data local inpath '/usr/local/soft/selectdata/website_pv_info.txt' into table website_pv_info;
load data local inpath '/usr/local/soft/selectdata/website_url_info.txt' into table website_url_info;
执行完毕上面的sql,检查数据是否成功加载到表中
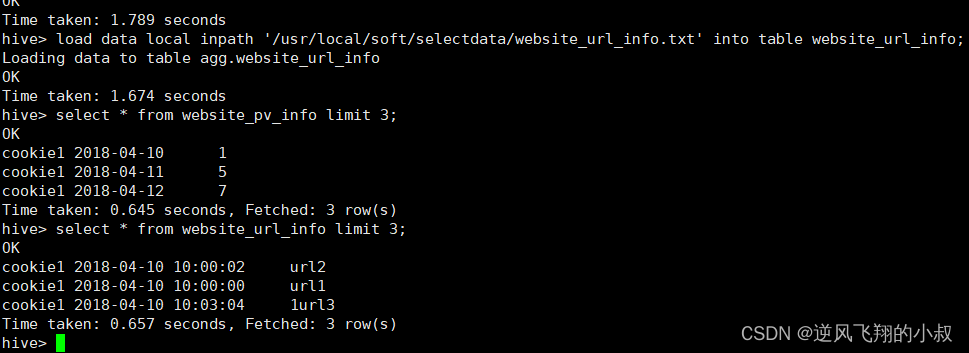
select * from website_pv_info;
select * from website_url_info;
执行结果如下
3.3.2 窗口聚合函数的使用
求每个用户总pv数, sum+group by普通常规聚合操作
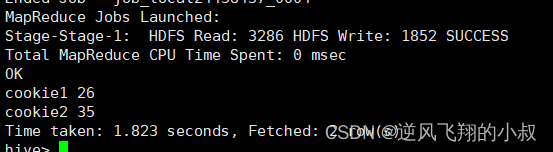
select cookieid,sum(pv) as total_pv from website_pv_info group by cookieid;执行结果
3.3.3 sum+窗口函数
该方式总共有四种用法 ,注意是整体聚合 还是累积聚合,
--sum(...) over( )对表所有行求和
--sum(...) over( order by ... ) 连续累积求和
--sum(...) over( partition by... ) 同组内所行求和
--sum(...) over( partition by... order by ... ) 在每个分组内,连续累积求和
紧接着,我们实现这样一个需求:求出网站总的pv数 所有用户所有访问加起来,语法:sum(...) over( )对表所有行求和;
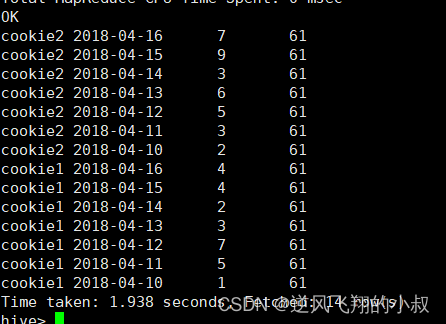
select cookieid,createtime,pv,
sum(pv) over() as total_pv --注意这里窗口函数是没有partition by 也就是没有分组 全表所有行
from website_pv_info;看下执行结果,在这种情况下,原本的数据保留,每一行记录多了一个汇总的结果列;
3.3.4 求出每个用户总pv数
sum(...) over( partition by... ),同组内所行求和
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid) as total_pv
from website_pv_info;执行结果

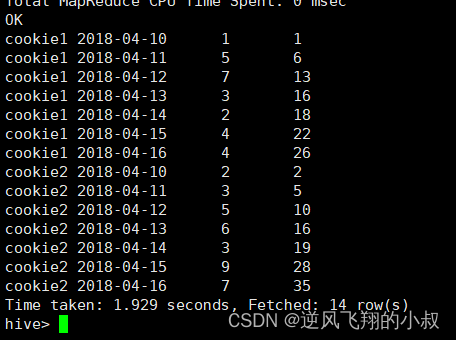
3.3.5 求出每个用户截止到当天,累积的总pv数
sum(...) over( partition by... order by ... ),在每个分组内,连续累积求和
3.4 窗口表达式
窗口表达式概述
- 在sum(...) over( partition by... order by ... )语法完整的情况下,进行累积聚合操作,默认累积聚合行为是:从第一行聚合到当前行;
- Window expression窗口表达式给我们提供了一种控制行范围的能力,比如向前2行,向后3行;
窗口表达式语法
关键字是rows between,包括下面这几个选项
- preceding:往前
- following:往后
- current row:当前行
- unbounded:边界
- unbounded preceding 表示从前面的起点
- unbounded following:表示到后面的终点
3.5 窗口表达式案例演示
下面来看窗口表达式的操作演示
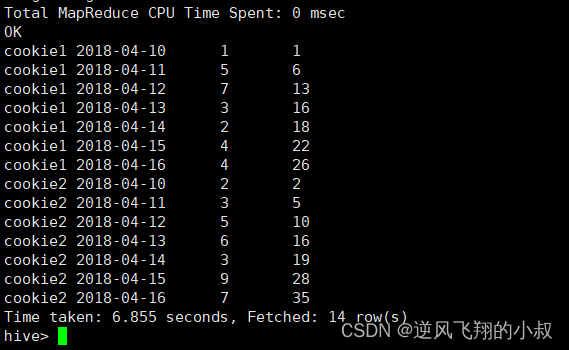
3.5.1 默认从第一行到当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as pv1 --默认从第一行到当前行
from website_pv_info;执行结果
3.5.2 第一行到当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from website_pv_info;执行结果

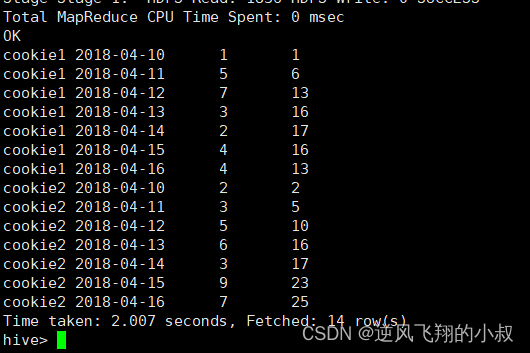
3.5.3 向前3行至当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from website_pv_info;执行结果
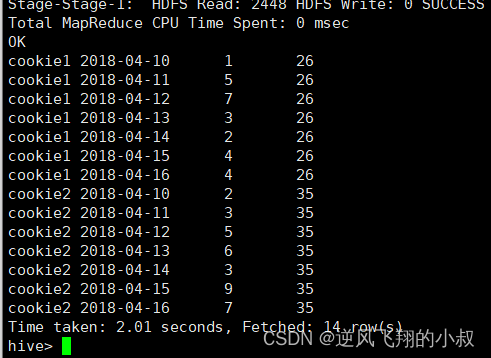
其他情况
--向前3行 向后1行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from website_pv_info;
--当前行至最后一行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from website_pv_info;
--第一行到最后一行 也就是分组内的所有行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;比如:第一行到最后一行, 也就是分组内的所有行
3.6 窗口排序函数
用于给每个分组内的数据打上排序的标号,注意窗口排序函数不支持窗口表达式,如下为一个窗口排序函数的语法使用;
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM website_pv_info
WHERE cookieid = 'cookie1';关于sql中有几个重要参数做如下说明:
- row_number:在每个分组中,为每行分配一个从1开始的唯一序列号,递增,不考虑重复;
- rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;
- dense_rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;
接下来看操作演示
3.6.1 找出每个用户访问pv最多的Top3
重复并列的不考虑
SELECT * from
(SELECT
cookieid,
createtime,
pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS seq
FROM website_pv_info) tmp where tmp.seq <4;
运行sql观察执行结果,就得到了每个用户的top3的PV;

3.7 窗口排序函数-ntile
有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的三分之一数据拿出来呢?NTILE函数即可以满足。
3.7.1 ntile 概述
1、将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号;
2、如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1;
如下sql,要把每个分组内的数据分为3桶
SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;
对应着数据表如下所示

3.7.2 统计每个用户pv数最多的前3分之1天
解决思路:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分
sql
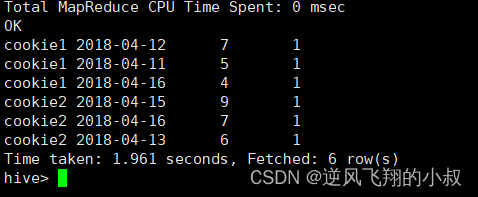
SELECT * from
(SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn
FROM website_pv_info) tmp where rn =1;执行结果
3.8 窗口分析函数
常用的窗口分析函数总结如下
3.8.1 LAG(col,n,DEFAULT)
用于统计窗口内往上第n行值,第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL);
3.8.2 LEAD(col,n,DEFAULT)
用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL);
3.8.3 FIRST_VALUE
取分组内排序后,截止到当前行,第一个值
3.8.4 LAST_VALUE
取分组内排序后,截止到当前行,最后一个值
3.8.5 案例操作演示
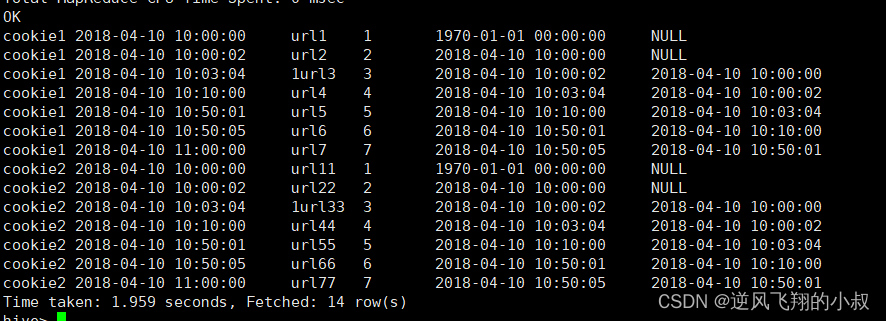
LAG 操作
查询website_url_info表,根据cookieid开窗,并根据createtime排序向上取2行
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time,
LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time
FROM website_url_info;执行结果
LEAD 操作(与上面相反的操作)
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LEAD(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS next_1_time,
LEAD(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_2_time
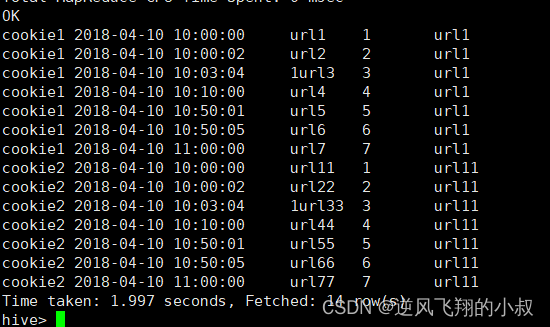
FROM website_url_info;FIRST_VALUE 操作
取分组内排序后,截止到当前行,第一个值
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
FROM website_url_info;执行结果
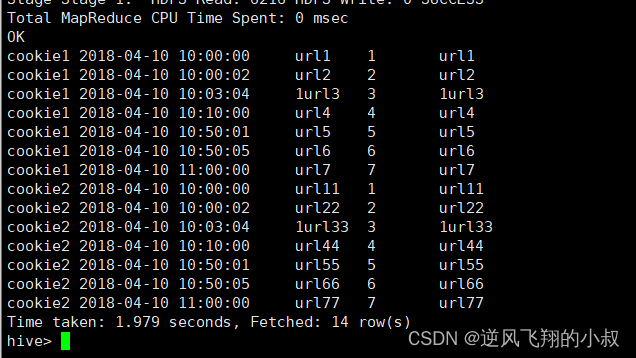
LAST_VALUE操作
取分组内排序后,截止到当前行,最后一个值
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM website_url_info;执行结果
四、抽样函数
4.1 抽样函数概述
当数据量过大时,我们可能需要查找数据子集以加快数据处理速度分析,这就是抽样、采样,一种用于识别和分析数据中的子集的技术,以发现整个数据集中的模式和趋势。
在HQL中,可以通过三种方式采样数据
- 随机采样;
- 存储桶表采样;
- 块采样;
4.2 Random 随机抽样
随机抽样使用rand()函数来确保随机获取数据,LIMIT来限制抽取的数据个数。 优点是随机,缺点是速度不快,尤其表数据多的时候。
1、推荐DISTRIBUTE+SORT,可以确保数据也随机分布在mapper和reducer之间,使得底层执行有效率;
2、ORDER BY语句也可以达到相同的目的,但是表现不好,因为ORDER BY是全局排序,只会启动运行一个reducer ;
4.3 案例操作演示
4.3.1 数据准备
使用下面的表的数据做演示
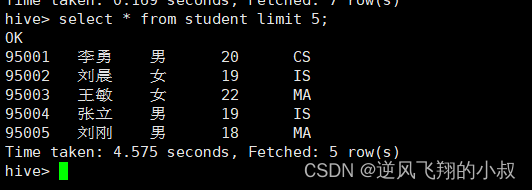
4.3.2 随机抽取2个学生的情况进行查看
SELECT * FROM student
DISTRIBUTE BY rand() SORT BY rand() LIMIT 2;
执行结果

使用order by+rand也可以实现同样的效果 但是效率不高
SELECT * FROM student
ORDER BY rand() LIMIT 2;
4.4 Block 基于数据块抽样
Block块采样允许随机获取n行数据、百分比数据或指定大小的数据,采样粒度是HDFS块大小。
优点是速度快,缺点是不随机
4.4.1 案例操作演示
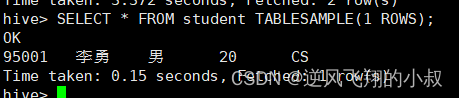
根据行数抽样
SELECT * FROM student TABLESAMPLE(1 ROWS);
可以看出来这个速度是非常快的
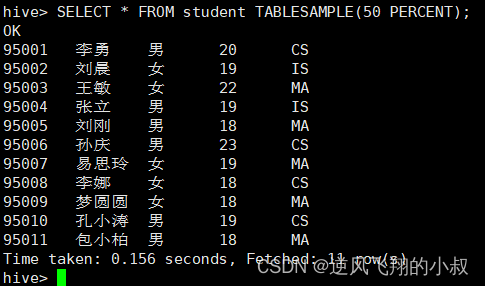
根据数据大小百分比抽样
SELECT * FROM student TABLESAMPLE(50 PERCENT);
执行结果
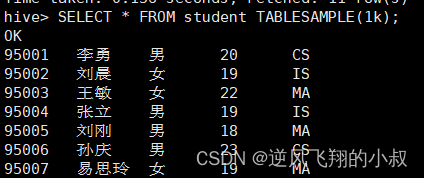
根据数据大小抽样
支持数据单位 b/B, k/K, m/M, g/G
SELECT * FROM student TABLESAMPLE(1k);
执行结果
其他抽样
---bucket table抽样
--根据整行数据进行抽样
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 5 ON rand());
--根据分桶字段进行抽样 效率更高
describe formatted t_usa_covid19_bucket;
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 5 ON state);4.5 Bucket table 基于分桶表抽样
这是一种特殊的采样方法,针对分桶表进行了优化。优点是既随机速度也很快。语法如下:
TABLESAMPLE (BUCKET x OUT OF y [ON colname] )
参数说明
1、y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例
例如,table总共分了4份(4个bucket),当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
2、x表示从哪个bucket开始抽取
例如,table总bucket数为4,tablesample(bucket 4 out of 4),表示总共抽取(4/4=)1个bucket的数据,抽取第4个bucket的数据。注意:x的值必须小于等于y的值,否则FAILED:Numerator should not be bigger than denominator in sample clause for table stu_buck
3、ON colname表示基于什么抽
ON rand() —— 表示随机抽,ON 分桶字段 —— 表示基于分桶字段抽样 效率更高 推荐
4.6 案例操作演示
在之前的文章中创建了如下的分桶表,直接使用这个分桶表

4.6.1 根据整行数据进行抽样
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 5 ON rand());
执行结果

4.6.2 根据分桶字段进行抽样 ,效率更高
describe formatted t_usa_covid19_bucket;
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 5 ON state);
可以看出来这个查询的速度很快

五、写在文末
窗口函数在大数据的统计分析中具有重要的意义,合理实用窗口函数可以让数据处理获得更好的效率和性能,比如在Flink中窗口函数是很实用的技术,甚至mysql在mysql8版本中也引入了窗口函数,因此有必要对窗口函数进行深入的学习。