系列文章目录
编程小白的自学笔记六(python中类的静态方法和动态方法)
目录
前言
很多小白都是听说python可以很好的编写爬虫脚本慕名而来,我也是,终于学到爬虫部分了,前面的html语言,客户端和服务器的交互等基础就不赘述了,直接进入主题。
一、使用get方法请求数据
开发网络爬虫需要第三方模块requests,我们需要安装,语法如下:
Pip install requests
安装完成后,使用其中的get方法就可以返回结果,其功能等同于我们在浏览器输入网址,然后服务器返回一个页面给我们一样 。
requests库的get方法是用于向服务器发送GET请求的。它的完整参数如下:
- url:请求的URL地址。
- params:查询字符串,用于传递参数。
- headers:请求头信息。
- cookies:Cookie信息。
- proxies:代理服务器地址。
- timeout:超时时间。
- verify:是否验证SSL证书。
下面我们看一个小例子:
import requests
url = 'http://www.baidu.com'
try:
req = requests.get(url)
print(req.text)
except:
print('查询失败')代码还是很简单的,返回的结果是:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
返回的内容比较多,我删除了中间的一些代码,这个就是网站的源码。我可以看出,只要给get方法传递一个url地址就行。
二、爬取酷狗音乐排行榜
下面就进入真正的实战了,爬取酷狗音乐排行榜数据,网址是酷狗TOP500_排行榜_乐库频道_酷狗网,可以看到网页上对歌曲进行了排名。

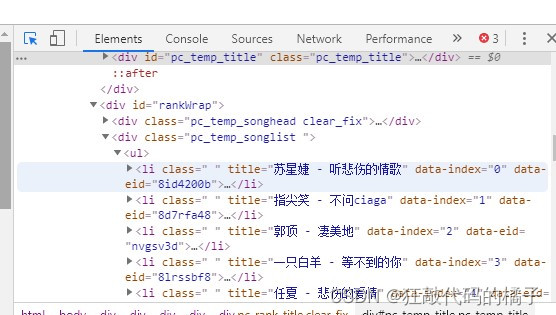
我们右击鼠标打开检查选项,可以找到歌曲信息在Html中的位置,可以看出歌曲名称和演唱者都在<li>元素的title属性中,如果我们通过get方法获取了网页的全部内容,就可以使用正则表达式提取出我们需要的信息。
下面是实战代码
import requests
import re
url = 'https://www.kugou.com/yy/rank/home/1-8888.html'
try:
req = requests.get(url)
songs = re.findall(r'<li.*?title="(.*?)".*?>',req.text)
for song in songs:
print(song)
except:
print('查询失败')程序运行成功,但不是我们想要的结果,返回的是空,也就是说没有匹配到结果,为此,我增加了代码print(req.text),看看我们获取到的返回结果是什么。
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>403 Forbidden</title> <style type="text/css">body{margin:5% auto 0 auto;padding:0 18px}.P{margin:0 22%}.O{margin-top:20px}.N{margin-top:10px}.M{margin:10px 0 30px 0}.L{margin-bottom:60px}.K{font-size:25px;color:#F90}.J{font-size:14px}.I{font-size:20px}.H{font-size:18px}.G{font-size:16px}.F{width:230px;float:left}.E{margin-top:5px}.D{margin:8px 0 0 -20px}.C{color:#3CF;cursor:pointer}.B{color:#909090;margin-top:15px}.A{line-height:30px}.hide_me{display:none}</style> </head> <body> <div id="p" class="P"> <div class="K">403</div> <div class="O I">Forbidden</div> <p class="J A L">Error Times: Fri, 23 Jun 2023 06:40:43 GMT <br> <span class="F">IP: 60.174.21.124</span>Node information: CS-000-01uyG161 <br>URL: https://www.kugou.com/yy/rank/home/1-8888.html <br>Request-Id: 64953e6b_CS-000-01uyG161_35678-151 <br> <br>Check: <span class="C G" onclick="s(0)">Details</span></p> </div> <div id="d" class="hide_me P H"> <div class="K">ERROR</div> <p class="O I">The Requested URL could not be retrieved</p> <div class="O"> <div>While trying to retrieve the URL:</div> <pre class="B G">https://www.kugou.com/yy/rank/home/1-8888.html</pre></div> <div class="M"> <span>The following error was encountered:</span> <ul class="E"> <li class="D G">Invalid Request</li></ul> </div> <p class="M">The access control configuration prevents your request at this time. <p></p>Please contact your service provider if you feel this is incorrect.</p> <a class="N C" href="#" onclick="s(1)">return</a></div> <script type="text/javascript">function e(i) { return document.getElementById(i); } function d(i, t) { e(i).style.display = (t ? 'block': 'none'); } function s(e) { d('p', e); d('d', !e); }</script> </body> </html>
可以看到,并没有歌手和歌曲内容,应该是搜狗网站进行了一些反爬。于是我们在get里面加上headers={'user-agent':'chrome'},来模拟浏览器访问,代码如下:
import re
url = 'https://www.kugou.com/yy/rank/home/1-8888.html'
try:
req = requests.get(url,headers={'user-agent':'chrome'})
# print(req.text)
songs = re.findall(r'<li.*?title="(.*?)"',req.text)
for song in songs:
print(song)
except:
print('查询失败')这次成功返回我们要的结果:
苏星婕 - 听悲伤的情歌
指尖笑 - 不问ciaga
郭顶 - 凄美地
一只白羊 - 等不到的你
任夏 - 悲伤的爱情
张靓颖、王赫野 - 是你 (Live)
Mae Stephens - If We Ever Broke Up (Explicit)
Kui Kui - 宝贝在干嘛
张紫豪 - 可不可以
周杰伦 - 说好的幸福呢
周杰伦 - 晴天
汪苏泷、吉克隽逸 - Letting Go (Live)
承桓 - 我会等
蔡健雅 - Letting Go
任夏 - 失眠情歌 (Live合唱版)
苏星婕 - 吹着晚风想起你
周杰伦 - 我落泪情绪零碎
云狗蛋 - 天若有情
程响 - 可能
A-Lin - 天若有情
RE-D、是二哈ya、masta - 肯定
G.E.M. 邓紫棋 - 喜欢你
我们来详细分析下:
- 用get方法获取网页内容。这个内容和最开始介绍的内容一样,get方法向服务器发送请求,服务器返回数据。
- 增加headers参数。我们第一次没有得到想要的结果,是网站增加了限制,目的就是用来验证请求是不是正常浏览器发出的,第一次我们的请求明显被服务器发现不正常了,于是我们增加了headers参数,内容为{'user-agent':'chrome'},意思就是浏览器类型为谷歌浏览器,这下骗过了服务器。
- 使用正则匹配我们想要的结果。使用正则我们需要先导入re模块,原始网页内容为<li class=" " title="苏星婕 - 听悲伤的情歌" data-index="0" data-eid="8id4200b">,那么我们只需要匹配以<li开头,内含有title=""的语句就行,那就可以这样写正则表达式<li.*?title="(.*?)",.*?代表除换行以外的其他元素,表达式的返回结果是子表达式的内容,正好是歌手加歌曲。
总结
requests库是一个Python的第三方库,用于发送HTTP请求。它提供了简单易用的API,可以方便地实现各种HTTP请求操作,如GET、POST、PUT、DELETE等。
requests库的主要特点如下:
1. 简单易用:requests库的API设计简洁明了,易于上手使用。
2. 灵活性高:requests库支持多种HTTP请求方法和参数设置,可以根据需要进行灵活配置。
3. 性能优异:requests库采用了高效的HTTP协议解析器和连接池技术,可以提高请求的响应速度和稳定性。
4. 支持多种数据格式:requests库可以处理JSON、XML、HTML等多种数据格式,并提供了丰富的解析器和转换器。
5. 跨平台兼容性好:requests库可以在Windows、Linux、Mac OS等多个操作系统上运行,并且支持Python 2.x和Python 3.x版本。总之,requests库是一个非常实用的HTTP请求工具,可以帮助开发者快速实现各种网络请求操作。