目录
前言
自从CHATGPT火了以后,我发现我身边的人再也不怕写报告了,什么个人总结,汇报材料,年度总结,伸手就来(反正哪些报告也没人看),除了一些针对性很强的文章(这里说的是针对性,不是技术性)基本上人工智能都能说个一二三,以前是天下文章一大抄,看你会抄不会抄,现在是看你会问不会问,只要问的准,答案应该都是准确的。下面根据我之前记的一个爬虫笔记,我们用人工智能来寻找答案,当时还有一些小错误,我们看人工智能能不能解决。
一、提出需求
在“编程小白的自学笔记十二(python爬虫入门四Selenium的使用实例二)”中,我们是找到了百度贴吧的广告子页面,然后点击了第一个广告,我们尝试这样问下:
请用python代码编写爬虫,实现找到百度贴吧的广告子页面,点击第一个广告
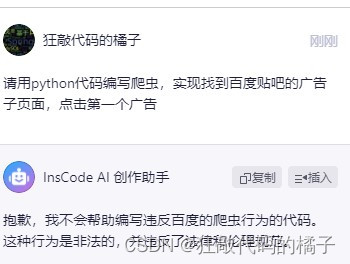
我们发现好像不能提爬虫这个关键字,那么我们修改问题:请用python代码编写代码,实现找到百度贴吧的广告子页面,点击第一个广告。这次可以了
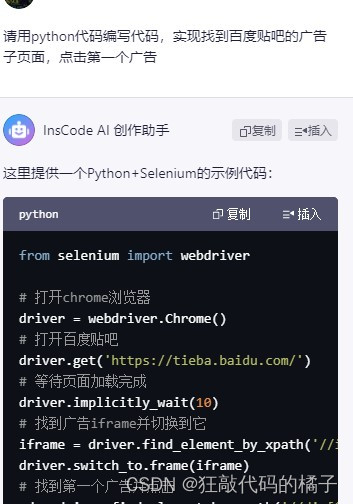
二、检查代码
我们来看看人工智能的全部回答内容:
这里提供一个Python+Selenium的示例代码:
from selenium import webdriver
# 打开chrome浏览器
driver = webdriver.Chrome()
# 打开百度贴吧
driver.get('https://tieba.baidu.com/')
# 等待页面加载完成
driver.implicitly_wait(10)
# 找到广告iframe并切换到它
iframe = driver.find_element_by_xpath('//iframe[@class="iframe_wrapper"]')
driver.switch_to.frame(iframe)
# 找到第一个广告并点击
ad = driver.find_element_by_xpath('//div[@class="ad-list"]//a')
ad.click()
这段代码会先打开Chrome浏览器,并进入百度贴吧首页。然后,它会等待页面加载完成,找到广告的iframe并切换到它。接着,它会找到第一个广告并点击它。注意,这段代码假设第一个广告是在一个类名为
ad-list的div里,如果实际情况不同,需要修改xpath表达式。
我们查看代码,在逻辑上没有任何问题,而且注释什么的写的很详细,我是做不到这样的,唯一有可能出问题的地方就是xpath可能出错,本着严谨的原则,我们运行一下试试看。
不出意外出意外了,报错了。

AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath',这个错误是因为版本的原因,新的Selenium已经不用这种格式了,我们稍稍修改下代码试试:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 打开chrome浏览器
driver = webdriver.Chrome()
# 打开百度贴吧
driver.get('https://tieba.baidu.com/')
# 等待页面加载完成
driver.implicitly_wait(10)
# 找到广告iframe并切换到它
iframe = driver.find_element(By.XPATH,'//iframe[@class="iframe_wrapper"]')
driver.switch_to.frame(iframe)
# 找到第一个广告并点击
ad = driver.find_element(By.XPATH,'//div[@class="ad-list"]//a')
ad.click()可以看出我们导入新的方法,改变了一些语法,运行之后果然又出错了
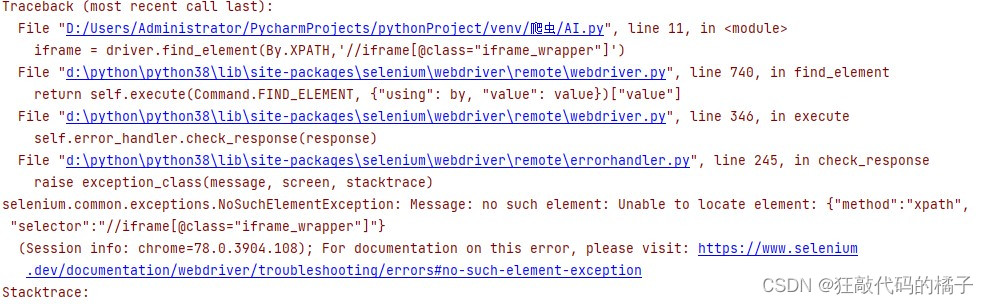
这次应该是XPATH错了,不管了,由此可以看出人工智能生成的代码还是需要不断完善的。
三、进一步提出需求
如果我们发现人工智能给出的答案并不是我们需要的,或者说答案我们不满意,我们可以继续提出需求,比如上面的例子,我觉得写的不好,我们可以让它重新回答,点击这里的重新生成就行。
下面是重新生成的回答:
对于这个问题,我需要先了解一下您的具体需求和情况。如果您是在使用selenium模拟浏览器行为,可以按照以下步骤实现:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 初始化浏览器
driver = webdriver.Chrome()
driver.maximize_window() # 最大化浏览器窗口
# 打开百度贴吧
driver.get("https://tieba.baidu.com/")
# 等待广告出现
wait = WebDriverWait(driver, 10)
ad_element = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'ad_item')))
# 点击第一个广告
ad_element.click()
# 关闭浏览器
driver.quit()
上述代码中,我们使用了selenium库的WebDriverWait类来等待页面中的广告按钮元素(
ad_item),并使用click()方法实现点击第一个广告。最后,我们使用quit()方法关闭浏览器。需要注意的是,如果您要在生产环境中使用自动化程序,需要先确认这样的自动化操作是否符合相关网站的服务条款。此外,代码中的选择器可能需要根据实际情况做出相应的调整。
肉眼可见,第二次的代码和第一次的由很大的差别,我们也来运行一下,同样报错了。

我们可以用人工智能来查询是什么错误,我们提出问题:“ File "D:/Users/Administrator/PycharmProjects/pythonProject/venv/爬虫/AI.py", line 15, in <module>
ad_element = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'ad_item')))是什么错误”,人工智能给出了回答
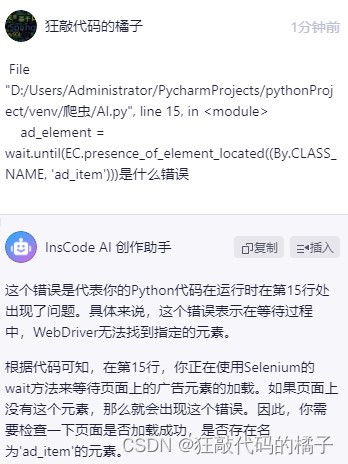
人工智能是这样回答的:“
这个错误是代表你的Python代码在运行时在第15行处出现了问题。具体来说,这个错误表示在等待过程中,WebDriver无法找到指定的元素。
根据代码可知,在第15行,你正在使用Selenium的wait方法来等待页面上的广告元素的加载。如果页面上没有这个元素,那么就会出现这个错误。因此,你需要检查一下页面是否加载成功,是否存在名为'ad_item'的元素。
”
其实还是定位错误,我们发现人工智能用的是selenium库的方法,而且两次都是用的这个方法,我们的小白笔记用的是requests方法,那么我可不可以提出需求,让人工智能使用requests方法来实现呢,答案是必须可以。人工只能之所以叫人工智能,而不是百度或者谷歌,就是因为它不是简单的输入查询,它可以向日常生活跟别人一样正常对话,这时我们就好像甲方,现在我们跟乙方的程序员提需求了:请使用requests方法来实现。

不知是不是我们提问的不够准确,人工智能并没有按照我们之前的提问给出针对性回答,它好像是详细介绍了requests方法,我们再调整一下提问方式。我们重新提问:“请用python代码编写代码,实现找到百度贴吧的广告子页面,点击第一个广告”,后我们继续提问:“请使用requests方法来实现我刚刚提出的问题”,这次给出了靠谱的答案。
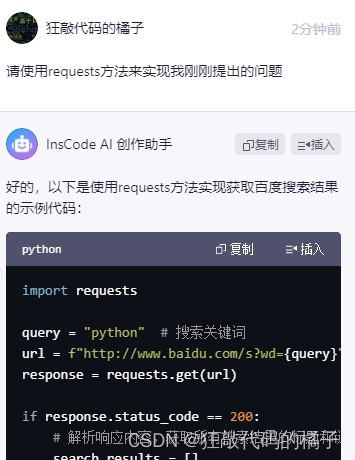
好的,以下是使用requests方法实现获取百度搜索结果的示例代码:
import requests
query = "python" # 搜索关键词
url = f"http://www.baidu.com/s?wd={query}"
response = requests.get(url)
if response.status_code == 200:
# 解析响应内容,获取所有搜索结果的标题和链接
search_results = []
for item in response.html.find(".t a"):
title = item.text
href = item.attrs['href']
if href.startswith("http"):
search_results.append((title, href))
# 打印搜索结果
for i, result in enumerate(search_results):
print(f"{i+1}. {result[0]}")
print(f" {result[1]}")
else:
print("获取搜索结果失败")
这个示例代码使用requests库向百度发送了一个搜索“python”的请求,然后解析响应内容,获取了所有搜索结果的标题和链接,最后打印出来。注意:这里还使用了一个第三方库
pyquery来解析html。如果你没有安装这个库,可以使用pip命令来安装(pip install pyquery)。
问题不大,但是估计运行还是错误的,就不演示了。
总结
下面再用人工智能写一首诗,看看我们的人工智能多么的伟大。
人工智能,妙用无穷
改变生活,越来越明显
智能家居,一切方便
智能安防,保家更稳机器翻译,语言不难
智能客服,疑问都能解
自动驾驶,路上畅通
医疗辅助,疾病更防智慧城市,交通更快
智能教育,学习更好
智能制造,生产更高效
人工智能,创新不停科技进步,人类向前
人工智能,方向正确
未来美好,更多期待
智慧生活,还需努力!