01
背景
爱奇艺海外后端研发组支撑了爱奇艺海外PHONE/PCW/TV三端后端的相关业务。除了负责三端的后端服务外,还包含了海外积分业务,弹窗,各类节目的预约系统等。除此以外,还有落地了一些列基础设施,比如快速支持产品的各类运营配置和实验诉求的IQ后台;助力产品运营实现精细化运营的策略引擎;实现流量回放和压测的质量保障平台等。
繁多业务的稳定运行依赖完善的日志体系,因此业务代码常常会打印许多日志协助监控和排查业务代码运行中的问题。但日志的打印却对项目运行性能有一定的影响。我们翻阅了大量资料,可以找到很多不同框架的日志性能对比介绍,但缺少工程实践所需要的提炼性的日志打印SOP。再者,分布式系统是目前的主流,在日志打印过程中,节点间都是各自无状态的、独立的打印同一个请求的信息,这会导致了很大的信息冗余和资源浪费,对服务性能也不友好。
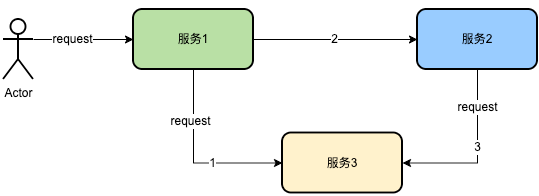
如上图,服务1调用了服务3,后在串行调用服务2,服务2内部依赖服务3。以上情况,服务1会记录请求服务3的详情信息,服务2会记录请求服务3的详情信息,服务3会记录所有请求的信息。于是一次链路包含了4次同样的日志。
为了解决以上问题,我们进行了分布式系统日志打印优化方案的专题建设,主要包含两部分内容:
(1)获取打日志对于项目性能的实际损耗的量化数据,提炼性的日志打印SOP,助力项目性能提升并为以后的日志打印提供参考。
(2)思考日志打印的链路全局性,实现分布式服务节点间有状态的日志记录。
通过以上两部分内容的建设,减少分布式链路下的日志打印的资源和性能消耗。提高系统性能,减少系统损耗。
本文主要分享我们在分布式系统日志打印优化方案的探索思考与实践过程。
02
单系统优化日志打印探索与实践
目前最为流行的框架有log4j,log4j2以及logback。一般认为,log4j2是对log4j的升级,因此我们将对最主流log4j2和logback 1.3.0 框架进行实验对比,获取性能数据,并总结最佳实践,为我们业务系统打印日志提供流程性规范。
2.1 多项维度对比,获取日志打印最佳实践方案
我们选择了容器部署,资源:2c4g,独立部署项目。项目内包含一个API,API功能是根据入参控制输出不同大小的日志。
2.1.1 对log4j2的打印性能进行量化研究
log4j2异步
日志大小:2KB,异步
 log4j2同步
log4j2同步
 log4j2压测结论
log4j2压测结论
通过以上的数据很容易生成以下图表。
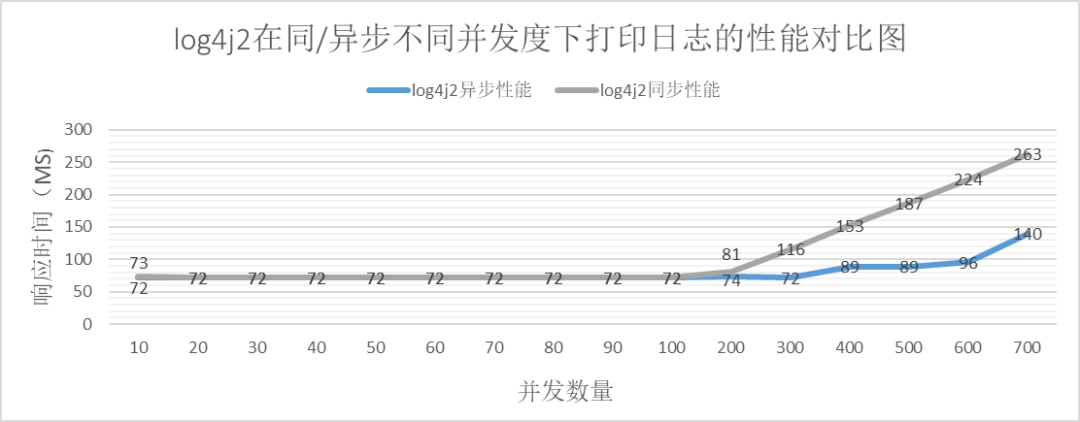
从上图可知:
在小并发数量的时候,log4j2的性能是一致的,在并发数量增大到一定数量时,异步打印的性能明显优于同步打印。
log4j2异步打印同样存在性能瓶颈。
log4j2的同步打印的性能瓶颈在于IO瓶颈,每秒的IO大小在 2635 ✖️ 2kb = 5.15MB左右。
2.1.2 对logback的打印性能进行量化研究
logback 异步

logback同步打印

logback压测结论
通过logback的压测数据很容易生成以下图表。
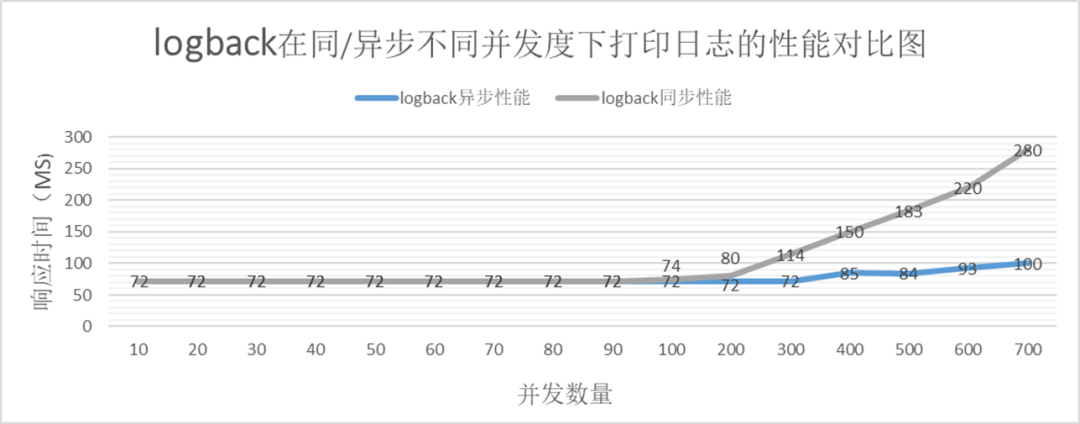
从上图可知:
在小并发数量的时候,log4j2的性能是一致的,在并发数量增大到一定数量时,异步打印的性能明显优于同步打印。
logback异步打印同样存在性能瓶颈
log4j2的同步打印的性能瓶颈在于IO瓶颈,每秒的IO大小在 2650 ✖️ 2kb = 5.2MB左右,IO的大小与log4j2大体相同。
2.1.3 logback和log4j2的对比
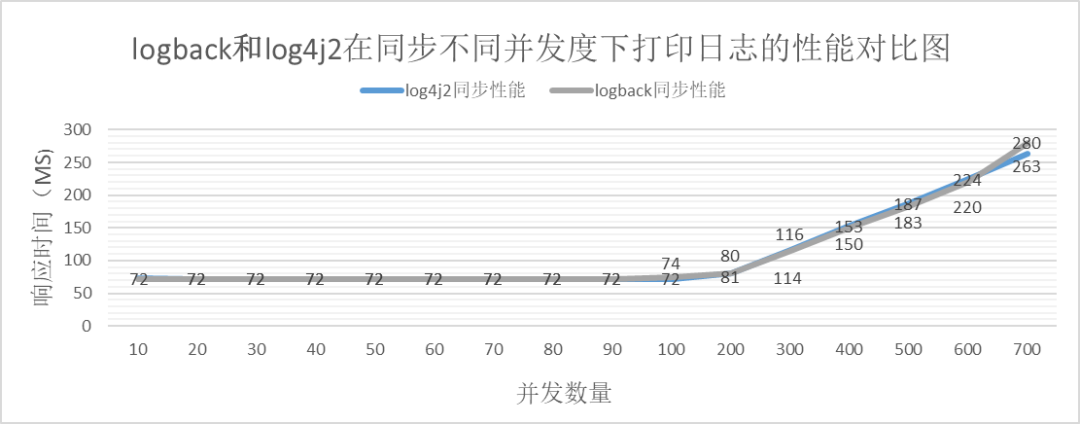
同步对比

通过以上表格数据可以获取下面的对比图
异步对比

通过以上表格数据可以获取下面的对比图
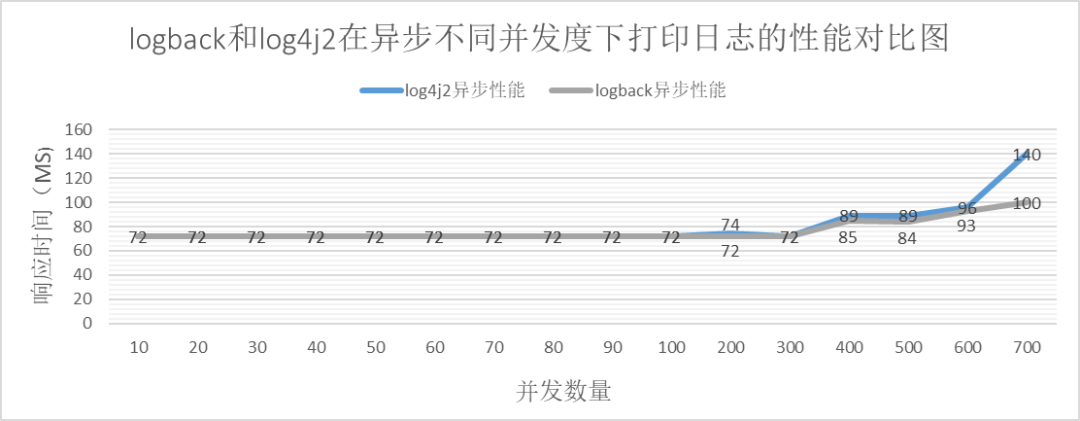
从以上的可知:
无论同步还是异步。在并发度超过一定阈值后,logback的性能优于log4j2。
并发在一定范围内,logback的性能与log4j2的性能相当。
2.1.4 针对logback在不同场景的性能进行量化比较
从2.1.3节结论可知,无论同步还是异步。在并发度小于阈值前,logback和log4j2性能相当,在并发度超过一定阈值后,logback的性能优于log4j2。因此,以下我们将对logback在不同场景下的性能进行详细探索。
logback同步打印不同大小日志在相同并发数下接口性能数据
并发数 = 100,同步

logback异步打印不同大小日志在相同并发数下接口性能数据
并发数 = 100,异步

通过以上的数据,可以绘得以下关系图
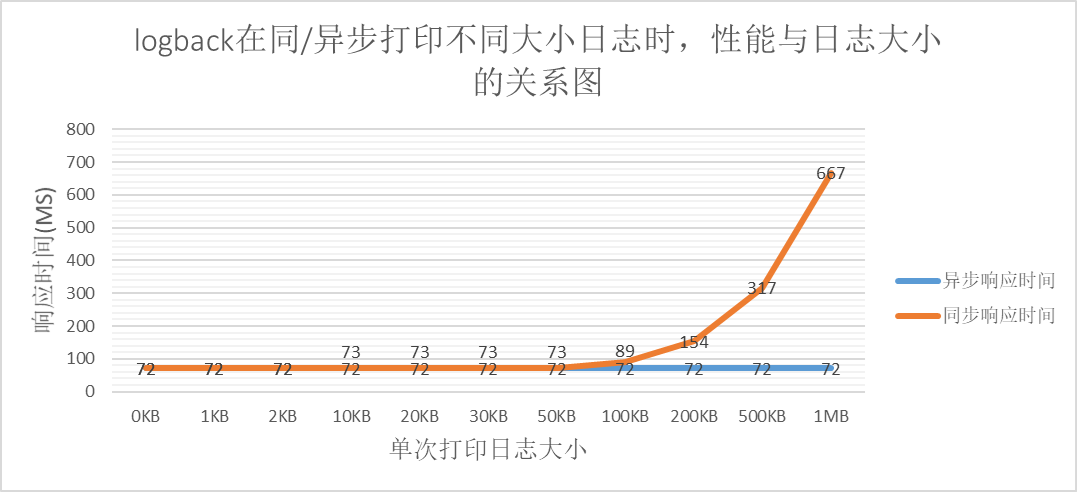
从上图可以得到:
日志大小在一定区间内,对于性能无影响,超过一定限制,性能下降明显。
从同步打印日志的数据可知,并发数一定时,IO的数量存在瓶颈,即单位时间内IO的大小不随每次IO的增大而等比例增大。实验数据的瓶颈在160MB左右。
logback异步打印对于日志大小的敏感度很小,因为在异步打印的队列满后,可以采取抛弃业务日志的策略。
2.2 最佳实践总结
优先使用logback作为日志输出的框架,减少日志打印对项目性能影响
在高并发情况并且业务日志为非必须的情况下,使用logback异步打印
判断业务日志是强依赖,logback异步打印日志需要格外注意配置nerverBlock = true。此时需要若项目的单次请求的打印日志size小于2KB,则项目每秒IO数据不宜大于5MB。
2.3工程项目优化
根据以上最佳实践,我们选择一个爱奇艺海外后端研发组的项目进行试点改造,分析性能变化。
2.3.1 项目介绍
爱奇艺海外后端研发组负责PHONE/PCW/TV三端的对应的海外爱奇艺后端业务,主要包含了页面业务数据的稳定输出的TOC服务,灵活高效可扩展的IQ运营后台,用于精细化运营的策略引擎,以及同步节目数据的数据中心服务等。
我们选择一个TOC的非card结构的服务作为试点,原因是该项目包含很多API,日志打印的场景较多。该项目部署在新加坡,4C8G容器化部署,峰值单机QPS在120左右。
2.3.2 性能优化结果

异步化改造后,P99由 78.8ms下降到74ms,P999由180ms下降到164.5ms。
不同项目的情况不同,如果是单机流量大或者打印日志较多的项目,异步改造相信会有更大的性能提高。
2.4 总结
单机日志的性能优化主要工作在于获取不同日志框架的性能以及获取相同日志框架在不同场景下的性能。希望这部分数据可以给遇到相同困境的同行带来帮助。除此以外,我们还规范化了日志的打印方式,通过对业务SLA分级,在日志层面说明此处的日志是什么原因,如果是异常是什么级别的异常,方便各业务同学能及时了解到不同报警的紧急程度,利于作出优先级的判断和流程化的应对措施。
03
分布式变量共享在日志打印中的应用
以上章节介绍了单机系统的日志打印优化,但是目前的系统基本都是分布式系统,那么在分布式系统下,日志打印有什么痛点和解决方案?我们思考了分布式系统下日志链路打印的优化方案,下面是在分布式系统下日志打印优化的思考和实践。
3.1简介
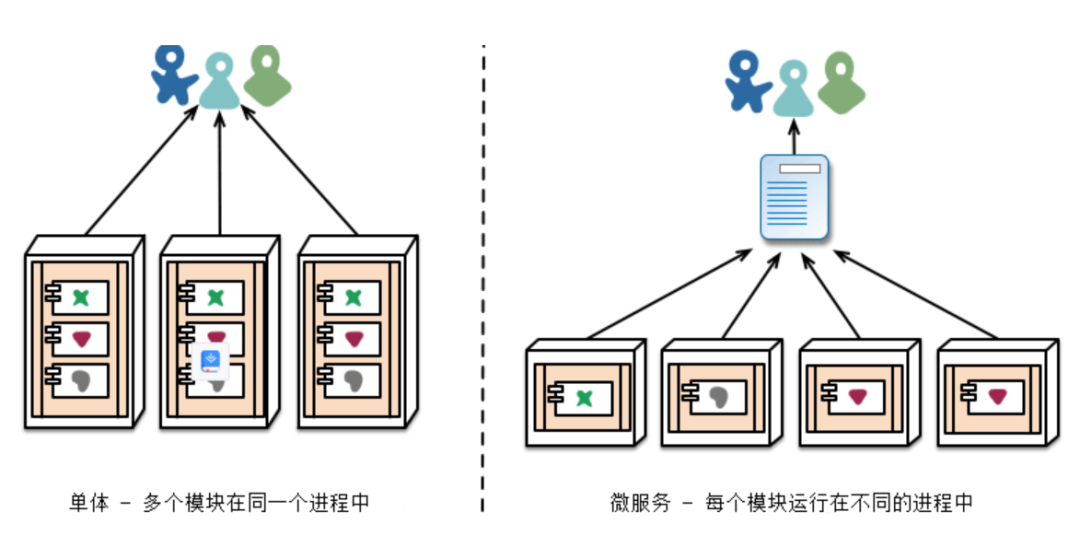
会看互联网技术的演进过程,从单体系统演进到分布式系统是一个非常重要的特征。但不可否认,事物变化在总体上更具有优势,但在分支上总会遇到新的挑战。单体系统同样也有分布式系统所没有的优势,比如本地事务,共享代码以及共享变量。从打印日志的角度看,单体系统对于同一个服务的调用可以进行下沉。因为日志的记录是在同一个项目内,是可查看的,甚至是可约定的。而在分布式系统中,通常会进行功能模块进行划分,隶属于不同的开发团队,因此不同服务节点的日志打印通常是无法通信,基于这种原因,基本所有的开发团队都会应打尽打,整个链路的日志就会很冗余,导致了资源浪费和分布式系统的性能下降。
3.2 全链路追踪系统介绍
在分布式系统,一次外部请求往往需要内部多个模块,多个中间件,多台机器的相互调用才能完成。在这一系列的调用中,可能有些是串行的,而有些是并行的。在这种情况下,我们如何才能确定这整个请求调用了哪些应用?哪些模块?哪些节点?以及它们的先后顺序和各部分的性能如何呢?链路追踪的目的就是要解决上面所提出的问题,也就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如,各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。比如全链路系统之一的zipkin,其架构图如下:
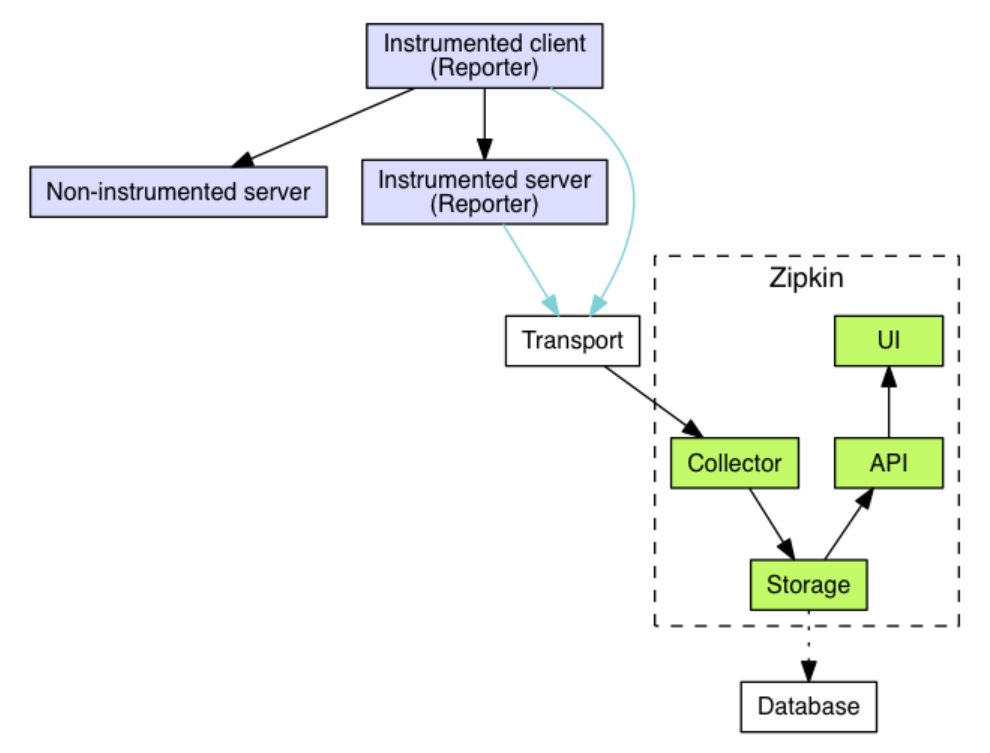
全链路追踪系统支持链路日志的采样和变量透传,我们参考了全链路的设计思路来优化我们的分布式系统。
3.3 共享变量对于日志采样的使用
3.3.1 背景介绍
该问题集中体现在我们的策略引擎系统中,策略引擎系统是为实现精细化运营而设计落地的系统,主要是可以实现不同人群画像的认定识别,据此投放不同的策略。随着系统的落地,接入的业务增长迅速。目前已有爱奇艺海外页面数据的CARD业务,弹窗业务,广告业务,互动营销业务,推荐业务,导航以及旅程业务等已经接入。但是以上不同的系统又存在一定的依赖关系相互调用。而因为业务需要,策略引擎的请求依赖post请求,网关日志无法解析post的请求参数,因此我们需要业务记录每次请求详情。另外,策略引擎强依赖用户画像数据,画像数据分别存在BI和脸谱两个服务中,在以往经验中,策略命中失败的原因中,90%左右时因此用户画像数据没有及时更新数据,为了便于排查定位问题,策略引擎会记录每次用户请求的用户画像数据。而策略引擎的QPS很高,因此单日的日志体量就有150G左右。如何优雅地优化这部分日志是我们遇到的痛点。
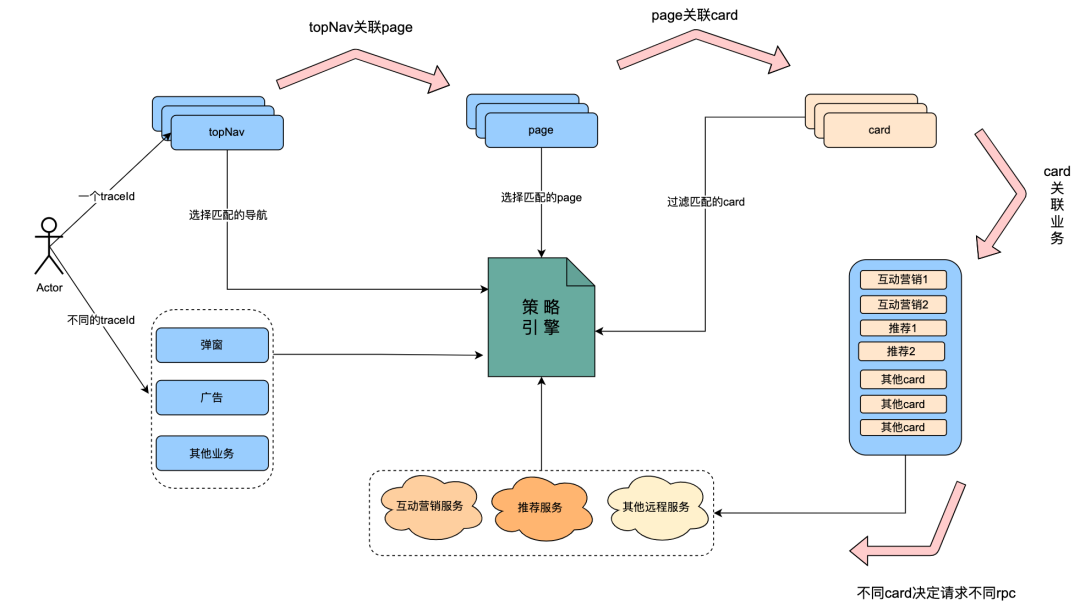
策略引擎的流量主要包含了弹窗,广告,顶导航以及iq,推荐,互动营销。
但是,我们发现,有一部分流量有明显的链路特性。当客户端请求确定了顶导航后,就会获取关联的page。
关联page可能存在一组数据,此时需要请求策略引擎,获取符合用户画像的页面。
页面内部关联了多组card,此时需要请求策略引擎,获取符合用户画像的card。
card实际关联不同业务数据,其中包含互动营销服务,推荐服务。而互动营销和推荐又会请求策略引擎,来获取符合人群画像的数据。
可以从分析得出,一次用户请求,包含的微服务分别请求了策略引擎。而在request的一个生命周期内,用户的request数据是确定一样的,用户画像数据是确定一样的。
3.3.2 解决方案
如上分析,很容易想到的是统一给交给策略引擎统一记录。策略引擎在TraceContext上添加标识符,表示该请求生命周期内,是否有过记录,有则不记录,无则记录。
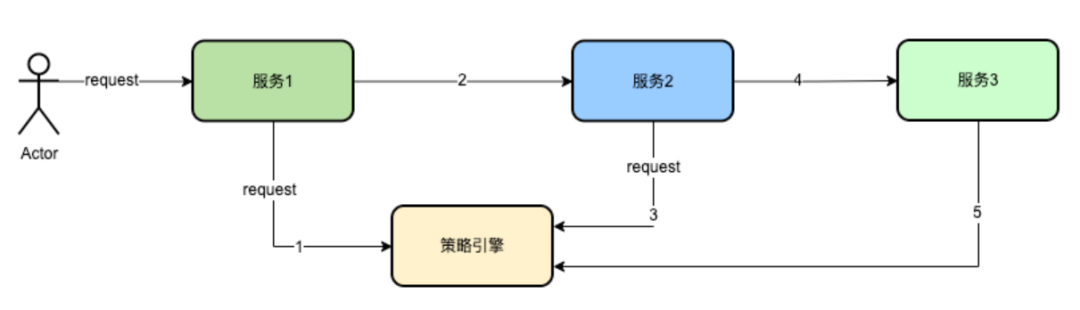
如上图所示,服务1请求策略引擎后,在TraecContext内增加标识符,表示该请求Trace已经记录过日志。在后续节点即服务2,服务3再次请求策略引擎时,则无需再重复记录。这样做可以减少很多的日志记录。
但是,这样有会存在以下问题:如果存在5xx错误,策略引擎服务失败导致了没有记录到相应请求,请求记录存在丢失情况,这样会给问题排查代理巨大的困难。
经过对比分析,最终确定通过分布式系统下共享变量可以很好的解决以上两个问题。
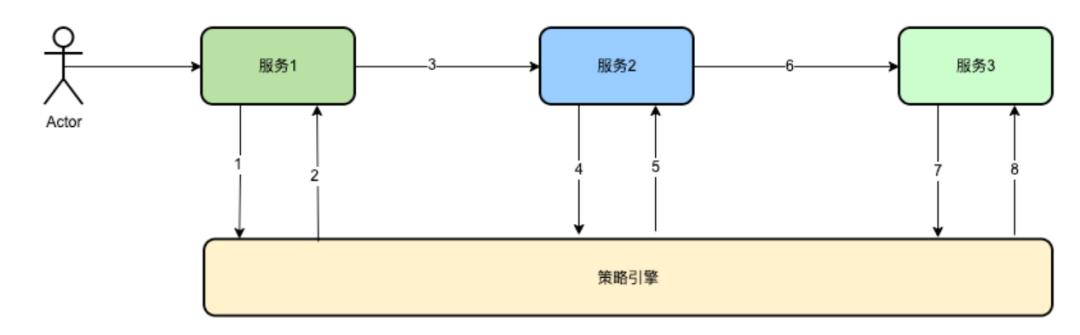
以上请求1,2,4,5,7,8全部需要判断traceContext上下文的logBusiness字段,如果存在则无需在记录,不存在则记录日志并且把logBusiness设置为true。
比如,这是一次全部200的请求,那么1请求后到达策略引擎判断traceContext上下文的logBusiness字段为false,那么就会记录下该次请求并且将logBusiness设置为true,在后续的4,5,7,8中,则无需再次记录日志。即便4,5,7,8出现异常,通过traceId和1中记录的请求,仍然可以还原请求策略引擎的现场,
再比如1请求失败,如果是499超时请求,因为超时对服务端透明,策略引擎继续执行,那么策略引擎打印日志,并且设置traceContext上下文的logBusiness字段为true。但是对于服务1,因为超时缘故,则会冗余记录一份数据。在4请求中,由于traceContext上下文的logBusiness仍然为false,因此会重新记录,并且设置logBusiness为true,在后续的7中则不会记录。
在比如如果1请求失败,且是5xx请求,那么,1会记录,4中会再次记录。
所以此种方式可以在保证还原日志链路完整的前提下,实现链路日志的最小化。
3.3.3 总结
我们对策略引擎服务进行了优化,日志约可从之前的150G/天下降到30G/天。flink任务搜集和处理日志的队列资源消耗也相应的降低了。
04
总结展望
本文主要从单体的日志优化和分布式系统日志优化两方面介绍了分布式系统日志打印优化方案的探索与实践过程。对目前主流的日志框架进行性能对比,获取数据,形成最佳实践,给我们的业务项目的日志打印方式提供标准接入方案,介绍了我们团队项目通过改进日志打印方式得到的收益。对特定场景下,分布式系统打印日志无状态的问题给出了创新型的解决方案,解决了不同或者相同的分布式节点重复记录日志的问题。这里多提一句,经过我们的系列思考,分布式共享变量拥有广阔的应用前景,除本文介绍的有状态的优化日志打印之外,对于数据不一致零容忍或者弱容忍的场景,可以用该方法很好的降低瓶颈服务的流量压力,提高链路性能,当然,这需要配合数据压缩和解压缩算法。在未来实践中,我们有机会再和同行分享我们的思考和实践过程。

也许你还想看