推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑的3D应用场景
什么是Visual ChatGPT?
Visual ChatGPT 是一个包含 Visual Foundation 模型 (VFM) 的系统,可帮助 ChatGPT 更好地理解、生成和编辑视觉信息。VFM 能够指定输入输出格式,将视觉信息转换为语言格式,并处理 VFM 历史记录、优先级和冲突。
因此,Visual ChatGPT 是一种 AI 模型,它充当了 ChatGPT 限制与允许用户通过聊天进行交流并生成视觉效果之间的桥梁。
ChatGPT 的局限性
在过去的几周和几个月里,ChatGPT 一直是大多数人的对话。但是,由于其语言训练功能,它不允许处理和生成图像。
而你有视觉基础模型,如视觉变压器和稳定扩散,它们具有惊人的视觉功能。这就是语言和图像模型的组合创造了Visual ChatGPT的地方。
什么是可视化基础模型?
视觉基础模型用于对计算机视觉中使用的基本算法进行分组。他们采用标准的计算机视觉技能并将其转移到AI应用程序上,以处理更复杂的任务。
Visual ChatGPT 中的提示管理器由 22 个 VFM 组成,其中包括文本到图像、控制网、边缘到图像等。这有助于 ChatGPT 将图像的所有视觉信号转换为语言,以便 ChatGPT 更好地理解。那么Visual ChatGPT是如何工作的呢?
Visual ChatGPT 如何工作?
Visual ChatGPT 由不同的组件组成,以帮助大型语言模型 ChatGPT 理解视觉对象。
Visual ChatGPT 的架构组件
- 用户查询:这是用户提交查询的位置
- 提示管理器:这会将用户的视觉查询转换为语言格式,以便 ChatGPT 模型可以理解。
- Visual Foundation Models:它结合了各种VFM,例如BLIP(Bootstrapping Language-Image Pre-training),Stable Diffusion,ControlNet,Pix2Pix等。
- 系统原理:这提供了可视化聊天GPT的基本规则和要求。
- 对话历史:这是系统与用户进行交互和对话的第一个点。
- 推理的历史:这使用不同VFM过去具有的先前推理来解决复杂的查询。
- 中间答案:通过使用 VFM,模型将尝试输出几个逻辑上低估的中间答案。
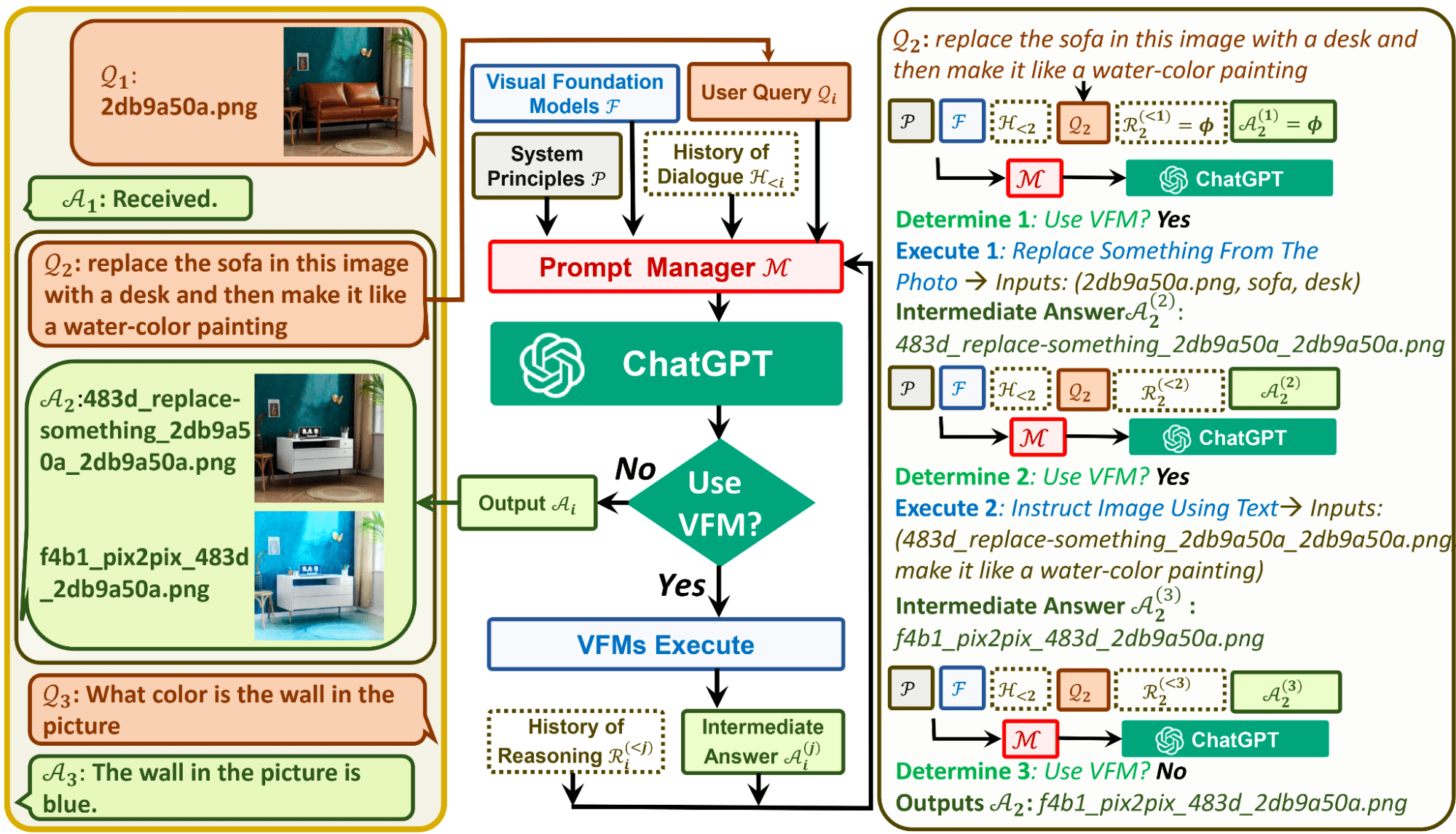
有关提示管理器的更多信息
你们中的一些人可能认为这是 ChatGPT 处理视觉效果的强制解决方法,因为它仍然将图像的所有视觉信号转换为语言。上传图像时,提示管理器会合成包含文件名等信息的内部聊天历史记录,以便 ChatGPT 可以更好地了解查询所指的内容。
例如,用户输入的图像的名称将充当操作历史记录,然后提示管理器将协助模型通过“推理格式”来确定需要对图像执行的操作。在 ChatGPT 选择正确的 VFM 操作之前,您可以将此视为模型的内部想法。
在下图中,您可以看到提示管理器如何启动可视 ChatGPT 的规则:
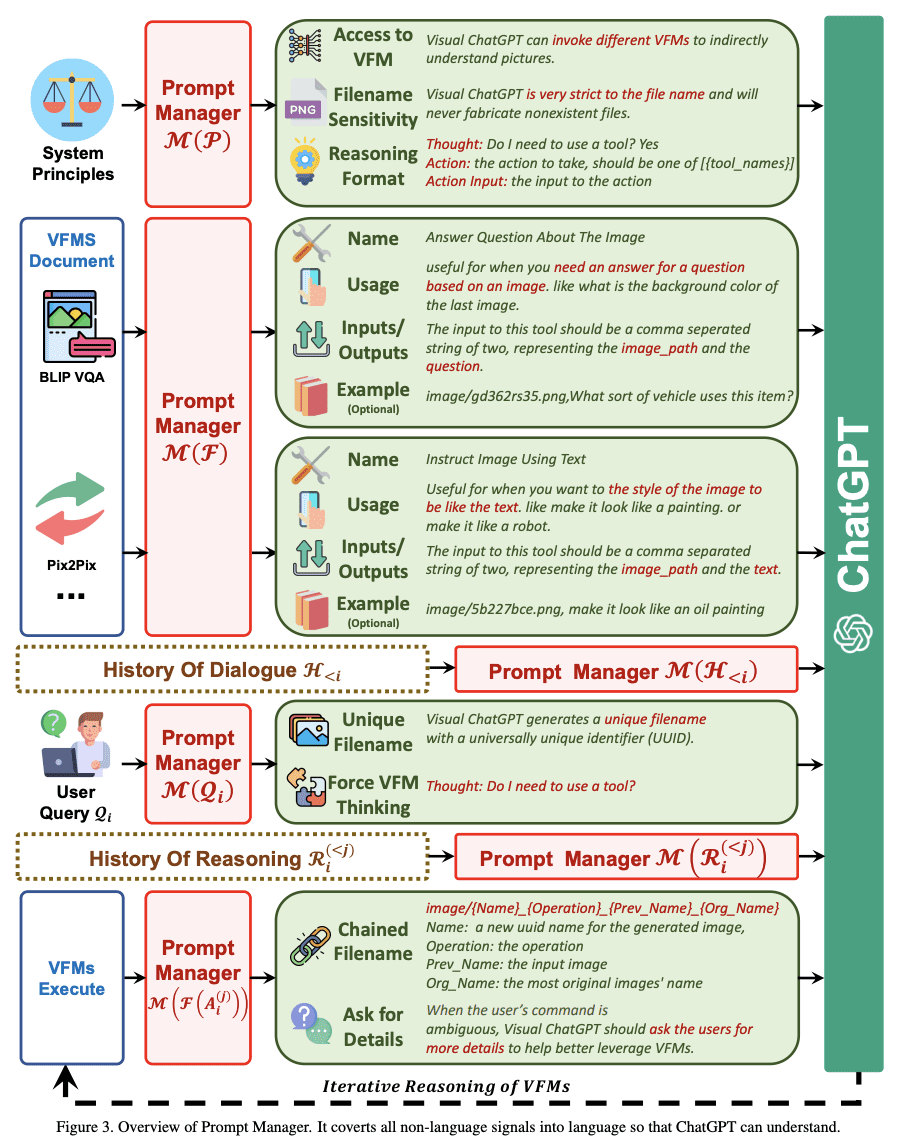
开始使用可视化聊天GPT
要开始您的 Visual ChatGPT 之旅,您需要先运行 Visual ChatGPT 演示:
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirement.txt
# download the visual foundation models
bash download.sh
# prepare your private openAI private key
export OPENAI_API_KEY={Your_Private_Openai_Key}
# create a folder to save images
mkdir ./image
# Start Visual ChatGPT !
python visual_chatgpt.py您还可以在Microsoft的Visual ChatGPT GitHub上了解更多信息。确保查看每个视觉基础模型上的 GPU 内存使用情况。
可视化聊天GPT的用例
那么Visual ChatGPT能做什么呢?
图像生成
您可以要求Visual ChatGPT从头开始创建图像,并提供描述。您的图像将在几秒钟内生成,具体取决于可用的计算能力。其使用文本数据的合成图像生成基于稳定扩散。
更改图像背景
同样,使用稳定的扩散,Visual ChatGPT可以改变您输入的图像的背景。用户可以向助手提供他们希望将背景更改为什么的任何描述,稳定的扩散模型将绘制图像的背景。
更改彩色图像和其他效果
您还可以根据为应用程序提供描述来更改图像的颜色并应用效果。Visual ChatGPT将使用各种预训练模型和OpenCV来更改图像颜色,突出显示图像边缘等。
对图像进行更改
Visual ChatGPT 允许您通过编辑和修改图像中的对象来删除或替换图像的各个方面,并向应用程序提供定向文本描述。但是,需要注意的是,此功能需要更多的计算能力。
Visual ChatGPT 的局限性
众所周知,组织总需要努力解决某种形式的缺陷来改善其服务。
计算机视觉和大型语言模型的结合
Visual ChatGPT 严重依赖 ChatGPT 和 VFM,因此,这些各个方面的准确性和可靠性会影响 Visual ChatGPT 的性能。使用大型语言模型和计算机视觉的组合需要大量的提示工程,并且可能难以实现熟练的性能。
隐私和安全
Visual ChatGPT能够轻松插入和拔出VFM,这可能是一些用户对安全和隐私问题的担忧。Microsoft需要更多地研究敏感数据如何不被泄露。
自我校正模块
Visual ChatGPT的研究人员遇到的限制之一是由于VFM的失败和提示的多样性而导致的生成结果不一致。因此,他们得出结论,他们需要研究一个自我更正模块,以确保生成的输出符合用户的要求,并能够进行必要的更正。
需要大量 GPU
为了从Visual ChatGPT中受益并利用22个VFM,您将需要大量的GPU RAM,例如A100。根据手头的任务,确保您了解有效完成任务所需的 GPU 量。
总结
Visual ChatGPT仍有其局限性,但这是同时使用大语言模型和计算机视觉的重大突破。如果您想了解有关Visual ChatGPT的更多信息,请阅读本文:Visual ChatGPT:使用Visual Foundation Models进行对话,绘图和编辑
Visual ChatGPT 与 ChatGPT4 相似吗?如果你尝试过这两种方法,你有什么看法?在下面发表评论!
原文链接:Visual ChatGPT:Microsoft ChatGPT 和 VFM 相结合 (mvrlink.com)