前言
相信大家在项目中都是用过redis,比如用来做一个分布式缓存来提高程序的性能。
当使用到了redis来做缓存,那么我们就必须要考虑几个问题,除了缓存击穿,缓存穿透,缓存雪崩,那么我们还需要考虑哪些问题呢?
高并发写
对于高并发情况下,比如直播下单,直播下单跟秒杀不一样,秒杀是有限定的库存,但是直播下单是可以一直下的,而且是下单越多越好的。比如说我们的库存有10万个,如果这个商品特别火,那么可能一瞬间流量就全都打过来了。虽然我们的库存是提前放到redis中,并不会去访问MySql,那么这时候所有的请求都会打到redis中。
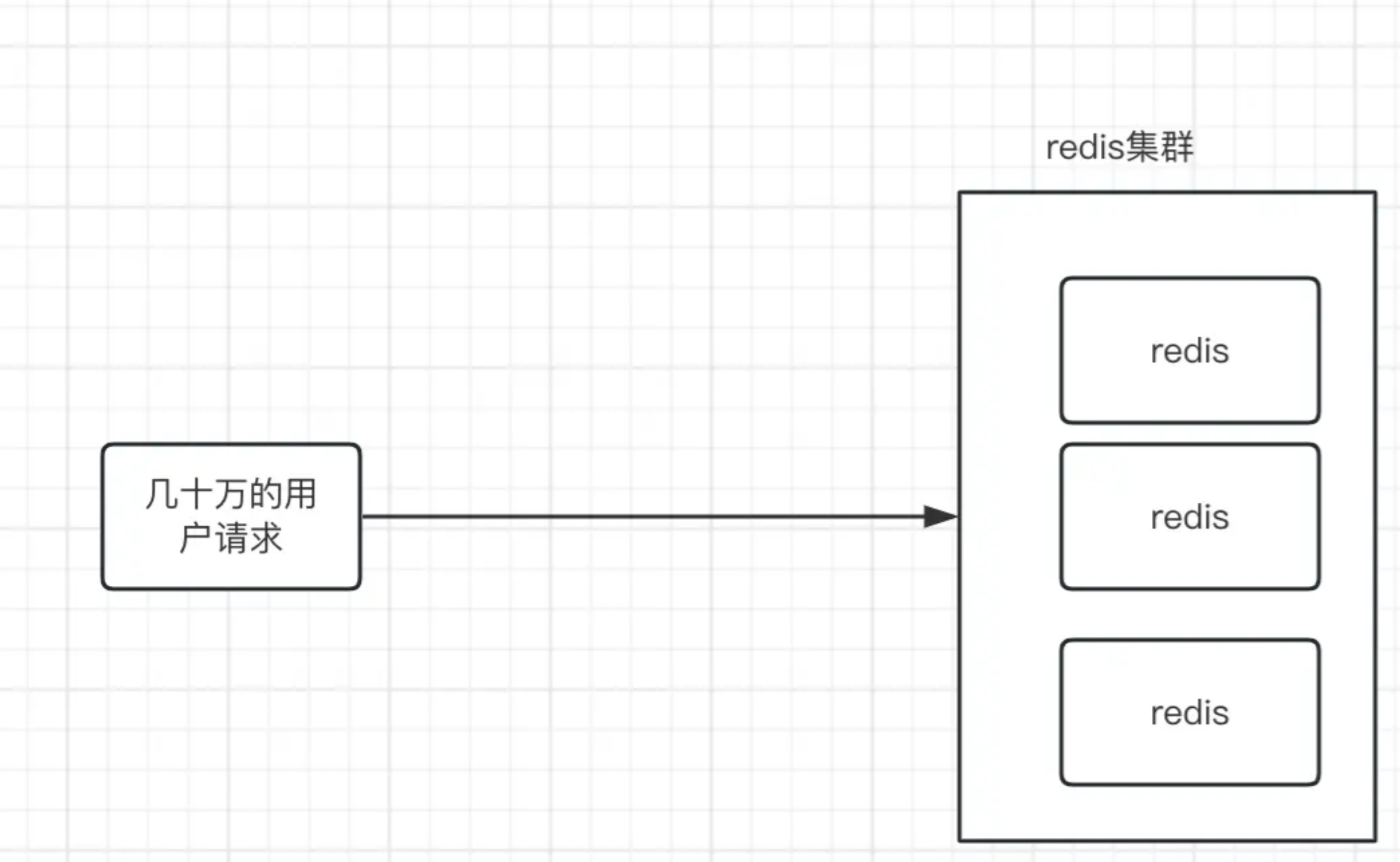
表面看起来确实没问题,但是你有没有想过,即使你做了集群,但是访问的还是只有一个key,那么最终还是会落到同一台redis服务器上。这时候key所在的那台redid就会承载所有的请求,而集群其它机器根本就不会访问到,这时候你确定你的redis能扛住吗???如果这时候读的请求很多,你觉得你的redis能扛住吗?
所以对于这种情况我们可以采用数据分片的解决方案,比如你有10万个库存,那么这时候可以搞10台redis服务器,每台redis服务器上放1万个库存,这时候我们可以通过用户的ID进行取模,然后将用户流量分摊到10台redis服务器上
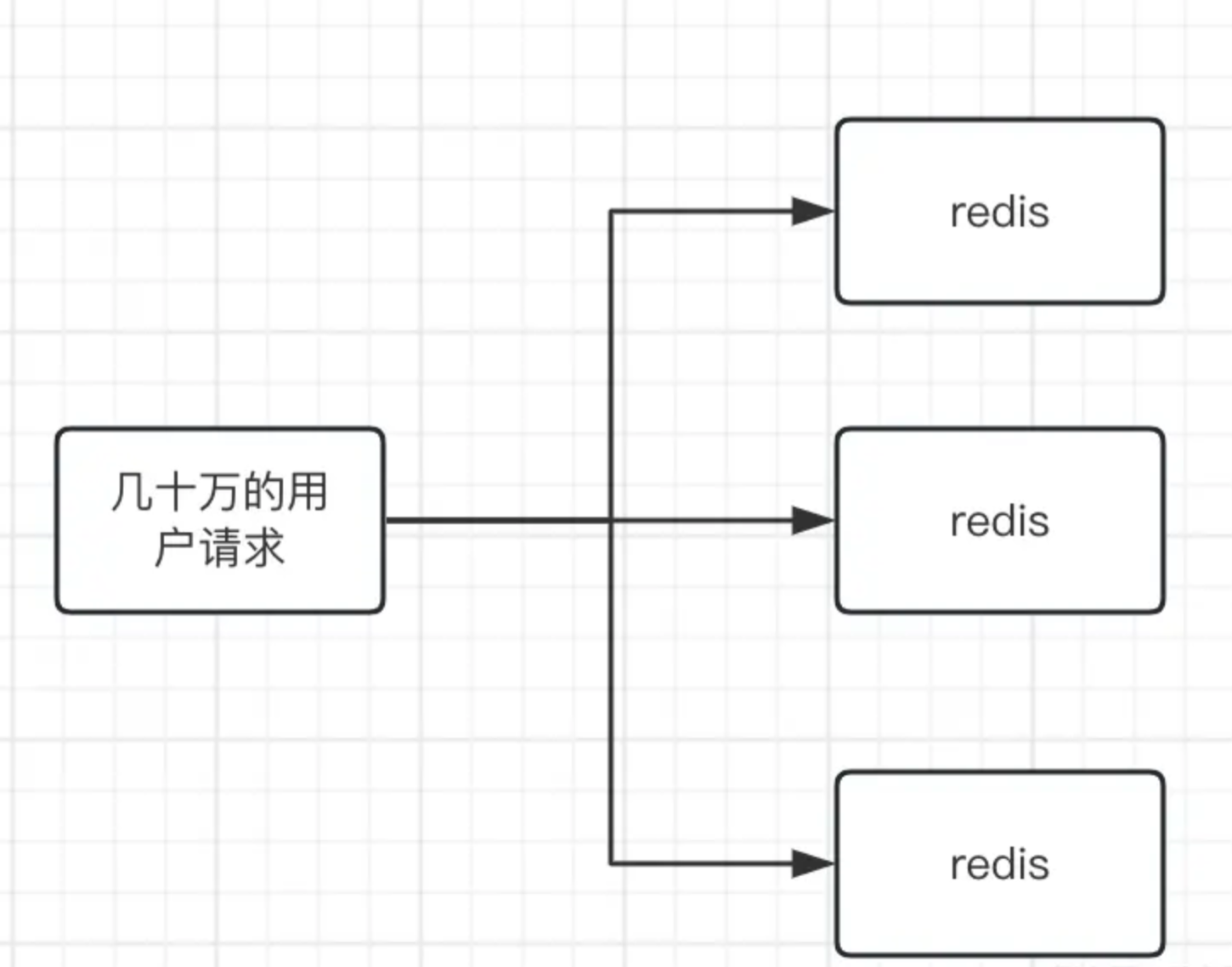
所以对于热点数据来说,我们要做的就是将流量进行分摊,让多台redis分摊承载一部分流量,尤其是对于这种高并发写来讲
高并发读
使用redis做缓存可以说是我们项目中使用到的最多的了,可能由于平时访问量不高,所以我们的redis服务完全可以承载这么多用户的请求但是我们可以想一下,一次reids的读请求就是一次的网络IO,如果是1万次,10万次呢?那就是10万次的网络IO,这个问题我们在工作中是不得不考虑的。因为这个开销其实是很大的,如果访问量太大,redis很有可能就会出现一些问题
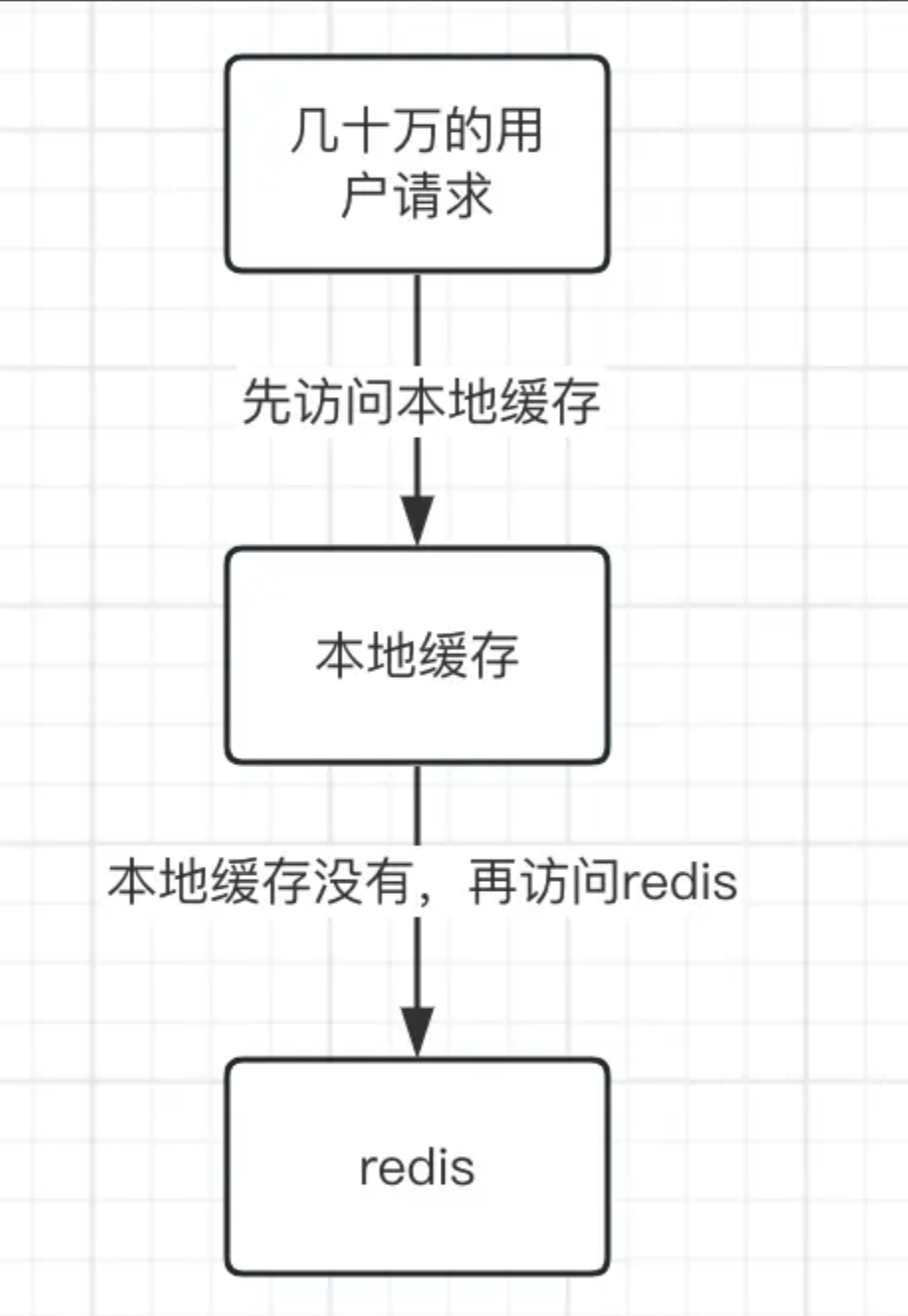
我们可以使用本地缓存+redis分布式缓存来解决这个问题,对于一些热点读数据,更新不大的数据,我们可以将数据保存在本地缓存中,比如Guava等工具类,当然本地缓存的过期时间要设置的短一点,比如5秒左右,这时候可以让大部分的请求都落在本地缓存,不用去访问redis。
如果这时候本地缓存没有,那么再去访问redis,然后将redis中的数据再放入本地缓存中即可。
加入了多级缓存,那么就会有相应的问题,比如多级缓存如何保证数据一致性。
总结
没有完美的方案,只有最适合自己的方案,当你决定采用了某种技术方案的时候,那么势必会带来一些其它你需要考虑的问题,redis也一样,虽然我们使用它来做缓存可以提高我们程序的性能,但是在使用redis做缓存的时候,有些情况我们也是需要考虑到的,对于用户访问量不高来说,我们直接使用redis完全是够用的,但是我们可以假设一下,如果在高并发场景下,我们的方案是否能够支持我们的业务