一、Mysql主从架构技术说明
Mysql内建的复制功能是构建大型,高性能应用程序的基础。将Mysql的数据分布到 多个系统上去,这种分布的机制,是通过将Mysql的某一台主机(Master)的数据复 制到其它主(slaves)上,并重新执行一遍来实现的。 复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服 务器将更新写入二进制日志文件,这些日志可以记录发送到从服务器的更新。当一个 从服务器连接主服务器时,它通知主服务器从服务器在日志中读取的最后一次成功更 新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。
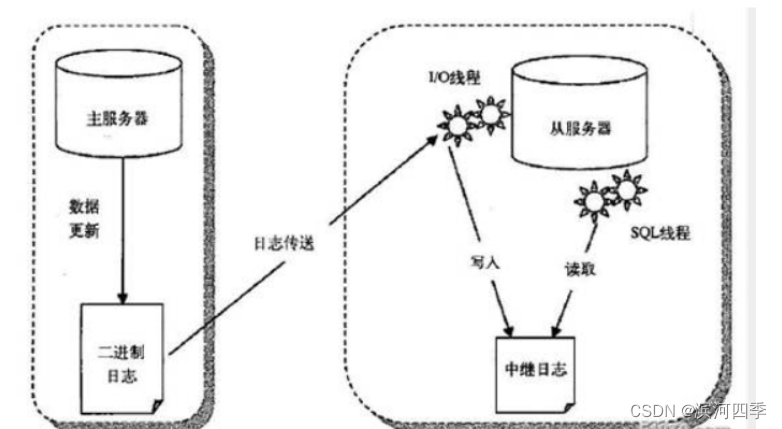
1. 主从复制架构图
二进制日志也就是binlog.log,它里面记录的数据库的操作;
主机数据库的操作记录在二进制日志里;
从机有两个线程:
- I/O线程
- 用来读取主机上的二进制日志的内容,写入到中继日志(relay_log)
- SQL线程
- 将中继日志中的数据读取给从机(因为二进制日志里的内容是sql语句,所以中继日志里的内容也是sql语句,这时候就需要sql线程将中继日志的内容读取,读取后相当于在从机上执行了sql语句,这样实现了主从复制)
2、Mysql复制解决的问题
MySQL复制技术有以下一些特点:
- 数据分布 (Data distribution )
- 负载平衡(load balancing)
- 备份(Backups)
- 高可用性和容错性 High availabilityand failover
主从复制以及主从复制的作用: 在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足 实际需求的,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发 负载能力
3、MySQL主从复制的复制方式
1)异步复制(Asynchronous replication)
MySQL的复制默认是异步的,MySQL主从异步复制是最常见的复制场景。数据的完
整性依赖于主库BINLOG的不丢失,只要主库的BINLOG不丢失,那么就算主库宕机
了,我们还可以通过BINLOG把丢失的部分数据通过手工同步到从库上去。
异步复制是指 主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不
关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上
已经提交的事务可能并没有传到从上,如果此时,强行将从提升为主,可能导致新主
上的数据不完整。
MySQL 默认的复制策略,Master处理事务过程中,将其写入Binlog就会通知Dump thread线程处理,然后完成事务的提交,不会关心是否成功发送到任意一个slave中;
【问题】:一旦Master 崩溃,发送主从切换将会发送数据不一致性的风险。
(也就是主机崩溃了,因为是异步,主机已经不再接受数据了,而从机还在同步就可能导致数据不一致)
画外音:性能最好

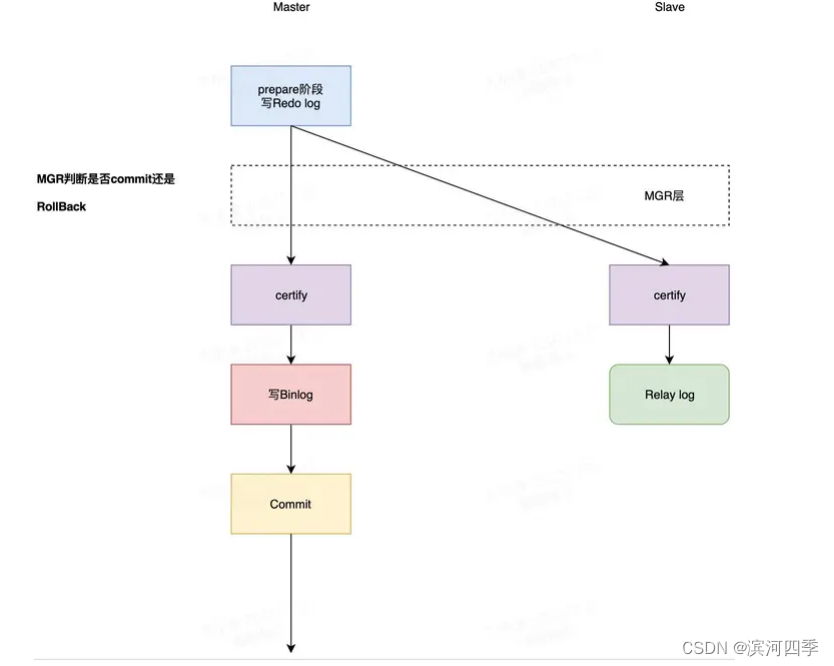
2)全同步复制(Fully synchronous replication)/组复制 (MySQL Group Replication(MGR))
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等 待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。 需要有超时时间。
MySQL在引擎层完成Prepare操作写Redo日志之后,会被MySQL的预设Hook拦截 进入MGR层
MGR层将事务信息打包通过Paxos协议发送到全部节点上,只要集群中过半节点回复 ACK,那么将告诉所有节点数据包同步成功,然后每个节点开始自己认证(certify) 通过就开始写Binlog,提交事务或者写relay log,数据同步,如果认证不通过则 rollback;
什么是Certify? 在不同服务器上并发执行的事务之间可能存在冲突。这种冲突是通过检查和比 较两个不同的并发事务的写入集来检测的,这个过程称为认证 在认证期间,冲突检测是在行级别执行的:如果在不同服务器上执行的两个并 发事务更新了同一行,则存在冲突。 冲突解决过程指出,首先排序的事务将在所有服务器上提交,而第二次排序的 事务将中止,因此将在原始服务器上回滚并被组中的其他服务器丢弃。
总结:MGR内部实现了分布式数据一致性协议,paxos通过其来保证数据一致性。
【问题】
1. 性能不高
2. TP999升高,吞吐量降低;增大20%~30%响应时间
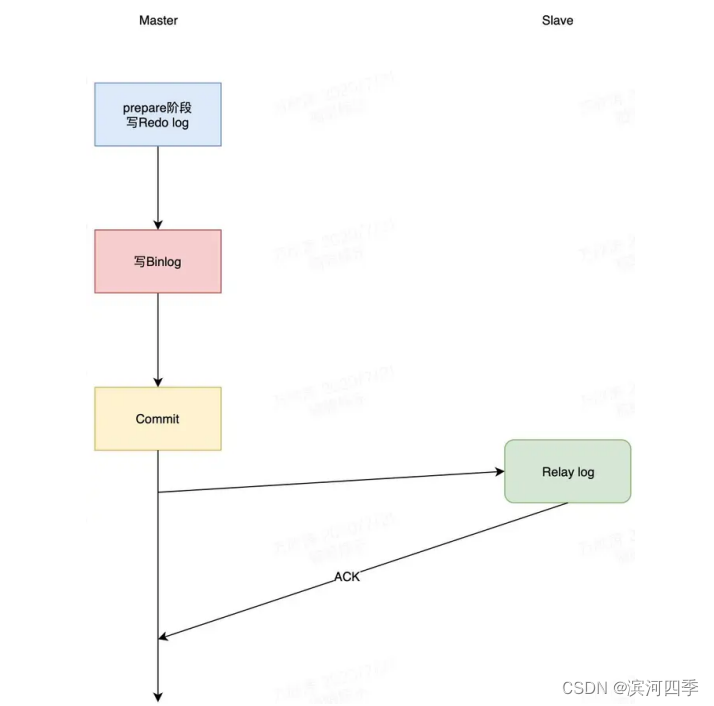
3)半同步复制(Semisynchronous replication)
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给 客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于 异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个 延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
Master处理事务过程中,提交完事务后,必须等至少一个Slave将收到的binlog写入 relay log返回ack才能继续执行处理用户的事务。
【问题】:
- 一旦Ack超时,将退化为异步复制模式,那么异步复制的问题也将发送
- 性能下降,增多至少一个RTT时间
- 数据不一致性问题,因为等待ACK的点是Commit之后,此时Master已经完成 数据变更,用户已经可以看到最新数据,当Binlog还未同步到Slave时,发生主 从切换,那么此时从库是没有这个最新数据的,用户又看到老数据。
二、Mysql实现企业级数据库主从复制架构实战
1、准备两台服务器
centos系统服务器2台、一台用户做Mysql主服务器,一台用于做Mysql从服务器, 都在同一个网段中,配置好yum源、防火墙关闭、各节点时钟服务同步、各节点之间 可以通过主机名互相通信;
•Master_IP:192.168.198.142
•Slave_IP:192.168.198.148
注意:MySQL版本号最好一致,为了方便学习测试,建议大家直接克隆之前课 程安装过的虚拟机然后修改下网卡配置文件,重新设置一个IP,并关闭防火墙。
2、关闭防火墙和selinux
1)临时关闭防火墙,下次启动虚拟机防火墙依旧是开启状态
systemctl stop firewalld2)永久关闭防火墙,下次启动虚拟机防火墙是关闭状态
systemctl disable firewalld3)清理防火墙规则
iptables -F4)关闭selinx
① 编辑/etc/sysconfig/selinux文件
vim /etc/sysconfig/selinux将高亮显示的地方改为disabled
② 改完之后重启虚拟机
reboot③ 查看selinux状态:
getenforce


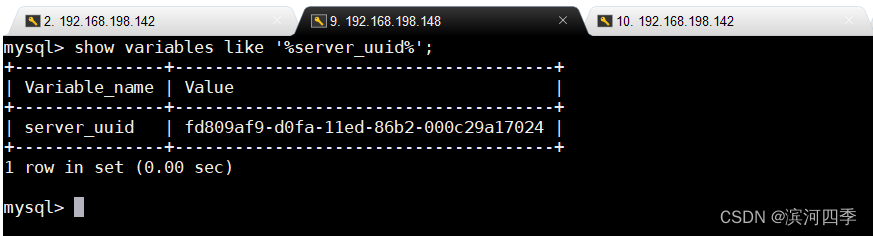
3、更改从机的uuid
mysql 5.6以后的复制引入了uuid的概念,各个复制结构中的server_uuid得保证不一 样,但是查看到直接copy data文件夹后server_uuid是相同的;
① 查看主从机的uuid
show variables like '%server_uuid%';
② 修改从机的uuid
vim /var/lib/mysql/auto.cnf
将原本的24改为25
修改外之后保存退出;
③ 重启mysql服务,重新加载配置
systemctl restart mysqld④ 查看从机的uuid是否修改成功;
修改成功;





4、修改master主机配置
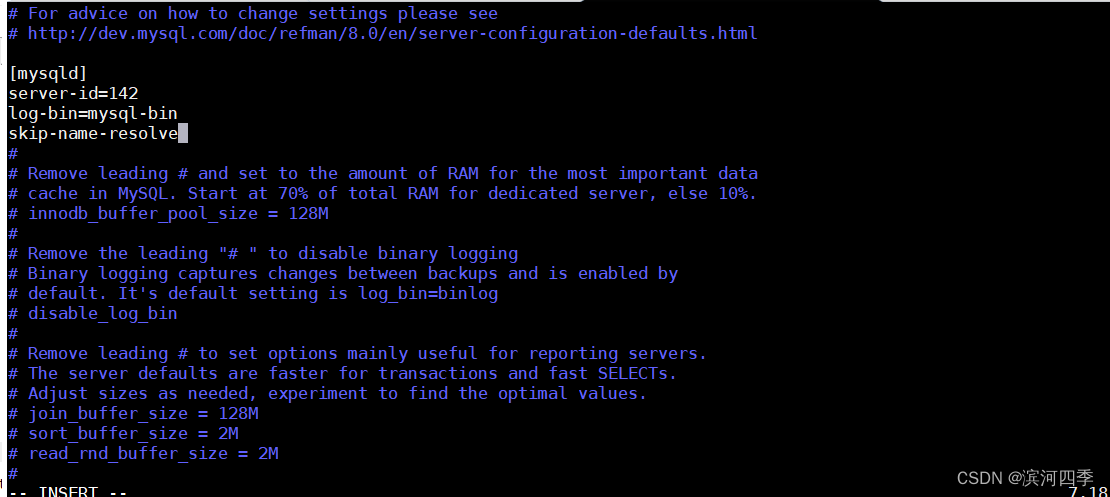
① 修改配置文件
vim /etc/my.cnf[mysqld] server-id=142 #配置server-id,让主服务器有唯一ID号(让从服务器知道他的主服务器是谁),建议使用ip最后3位 log-bin=mysql-bin #打开Mysql日志,日志格式为二进制 skip-name-resolve #关闭名称解析,(非必须)
② 然后重启数据库服务
systemctl restart network

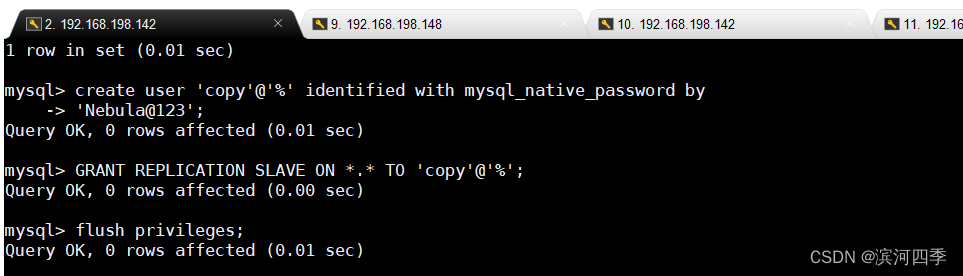
5、创建复制帐号
在Master的数据库中建立一个备份帐户:每个slave使用标准的MySQL用户名和密码 连接master。进行复制操作的用户会授予REPLICATION SLAVE权限。(给从服务器 授权,让它能从主服务器拷贝二进制日志)
create user 'copy'@'%' identified with mysql_native_password by 'Nebula@123'; GRANT REPLICATION SLAVE ON *.* TO 'copy'@'%'; flush privileges;
6、查看主服务器状态
show master status\G;
记录上图结果中File和Position的值。
注意:执行完此步骤后不要再操作主服务器MySQL,防止主服务器状态发生状态值变化。

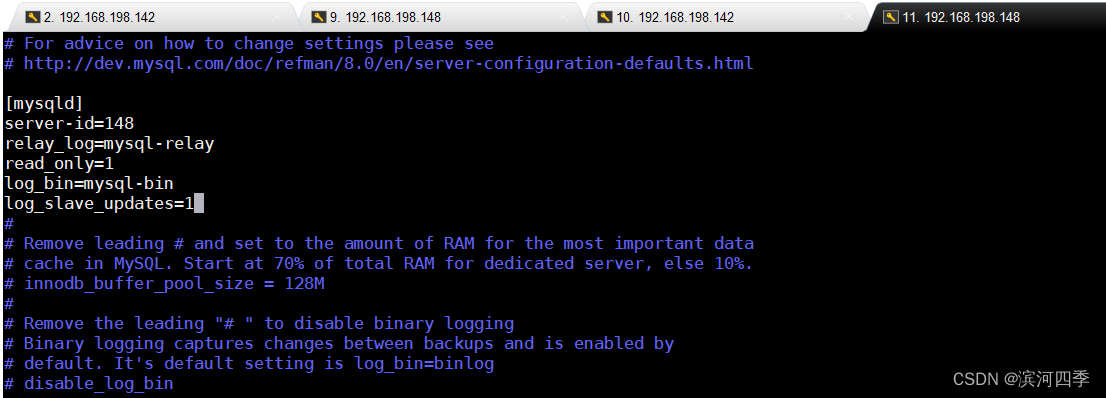
7、配置slave从服务器
① 修改配置文件
vim /etc/my.cnf[mysqld] server-id=148 #配置server-id,让从服务器有唯一ID号,建议使用ip最后3位 relay_log=mysql-relay #打开Mysql日志,日志格式为二进制 read_only=1 #设置只读权限 log_bin=mysql-bin #开启从服务器二进制日志 log_slave_updates=1 #使得更新的数据写进二进制日志中
② 然后重启数据库服务
systemctl restart mysqld

8、启动从服务器复制线程
①在从机上连接主机
【直接复制可能会有莫名其妙的报错,最好手敲一遍】
CHANGE MASTER TO master_host = '192.168.198.142', #主库的IP地址 master_user = 'copy', #在主库上创建的复制账号 master_password = 'Nebula@123', #在主库上创建的复制账号密码 master_log_file = 'mysql-bin.000004', #开始复制的二进制文件名(从主库查询结果中获取) master_log_pos = 773; #开始复制的二进制文件位置(从主 库查询结果中获取)
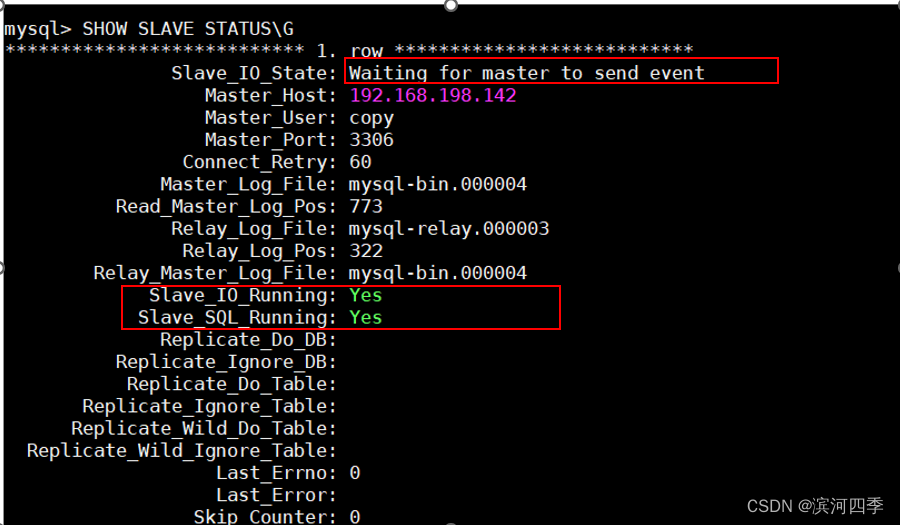
② 执行start slave;# 启动复制线程。
③ 出现红框的内容,表示主从复制配置成功
④ 测试主从复制是否成功
Master中和Slave中执行SQL:
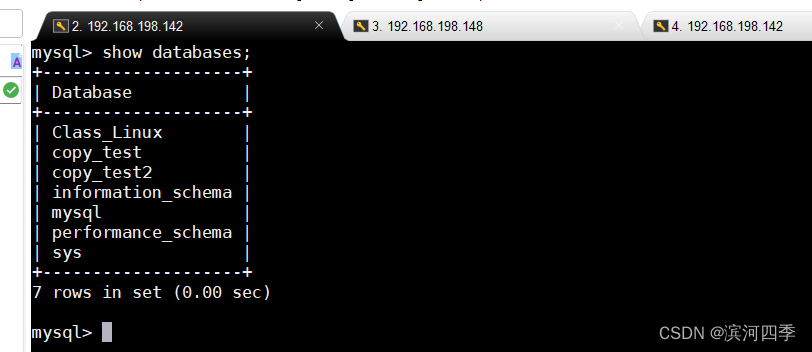
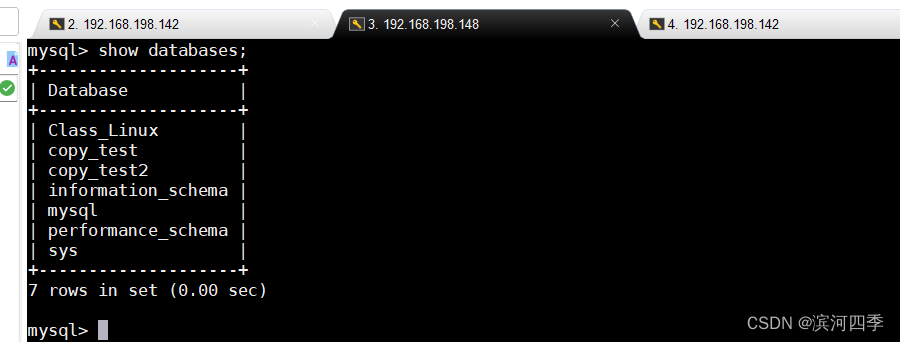
show databases;Master:
Slave:
在Master中创建数据库并创建数据表并插入一条数据:
create database copy_test2; use copy_test2; create table tab1(id int auto_increment,name varchar(10),primary key(id)); insert into tab1(id,name) values (1,'why');
⑥ 查看主从机是否都有copy_test2数据库;





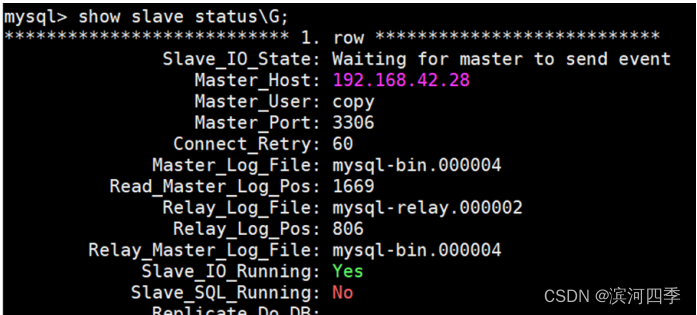
9、mysql 主从数据不一致,提示:Slave_SQL_Running: No 的解决方法
在slave服务器上通过如下命令:
show slave status\G;效果如下图所示,表示slave不同步
解决方法(忽略错误,继续同步):
① 先停掉slave
stop slave;② 跳过错误步数,后面步数可变
set global sql_slave_skip_counter=1;③ 再启动slave
start slave;④ 查看同步状态
show slave status\G;