比赛简介
本次比赛的目标是将学生写作中的论证元素分类为“有效(effective)”、“充分(adequate)”或“无效(ineffective)”。您将创建一个基于代表美国 6-12 年级人口的数据进行训练的模型,以最大程度地减少偏差。从本次比赛中得出的模型将有助于为学生获得有关议论文写作的更多反馈铺平道路。通过自动指导,学生可以完成更多作业,并最终成为更自信、更熟练的作家。
写作是成功的关键。特别是,议论文写作培养批判性思维和公民参与技能,并且可以通过实践来加强。然而,只有13%的八年级教师要求他们的学生每周有说服力地写作。此外,资源限制不成比例地影响黑人和西班牙裔学生,因此与白人同龄人相比,他们更有可能在“低于基本”水平上写作。自动反馈工具是使教师更容易对分配给学生的写作任务进行评分的一种方法,这也将提高他们的写作技巧。
目前有许多可用的自动写作反馈工具,但它们都有局限性,尤其是在议论文写作方面。现有的工具往往无法评估论证要素的质量,例如组织、证据和想法发展。最重要的是,由于成本高昂,教育工作者无法使用其中的许多写作工具,这在很大程度上影响了已经服务不足的学校。
佐治亚州立大学 (GSU) 是亚特兰大的一所本科和研究生城市公共研究机构。《美国新闻与世界报道》将GSU列为全美最具创新性的大学之一。GSU授予非裔美国人的学士学位比该国任何其他非营利性学院或大学都多。GSU和位于亚利桑那州的独立非营利组织The Learning Agency Lab专注于开发基于学习的科学工具和计划,以促进社会公益。
为了让所有学生做好最好的准备,GSU和学习机构实验室联手鼓励数据科学家改进自动写作评估。这种公共努力还可以鼓励更高质量和更易于访问的自动化书写工具。如果成功,学生将收到更多关于他们写作的论证元素的反馈,并将把这项技能应用到许多学科中。
评估方法
本次比赛的第一场比赛侧重于分类的准确性。此轨道的提交使用多类对数损失进行评估。数据集中的每一行都标有一个真实有效性标签。对于每一行,您必须提交商品属于每个质量标签的预测概率。公式为:
l o g l o s s = − 1 N ∑ i = 1 N ∑ j = 1 M y i j l o g ( p i j ) log\ loss = -\frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{M}y_{ij}log\left ( p_{ij} \right ) log loss=−N1i=1∑Nj=1∑Myijlog(pij)
其中 N N N是测试集中的行数, M M M是类标签的数量, l o g log log是自然对数,如果观察值 i i i在类 j j j中,则 y i j y_{ij} yij为1,否则为0,并且 p i j p_{ij} pij是观察值 i i i属于 j j j类的预测概率,在这种情况下对数是自然对数。
给定话语元素的提交概率不需要加起来:它们在评分之前被重新调整,每行除以行总和。为了避免 l o g log log函数的极端情况,预测概率替换为:
m a x ( m i n ( p , 1 − 1 0 − 5 ) , 1 0 − 15 ) max\left ( min\left ( p, 1-10^{-5} \right ), 10^{-15} \right ) max(min(p,1−10−5),10−15)
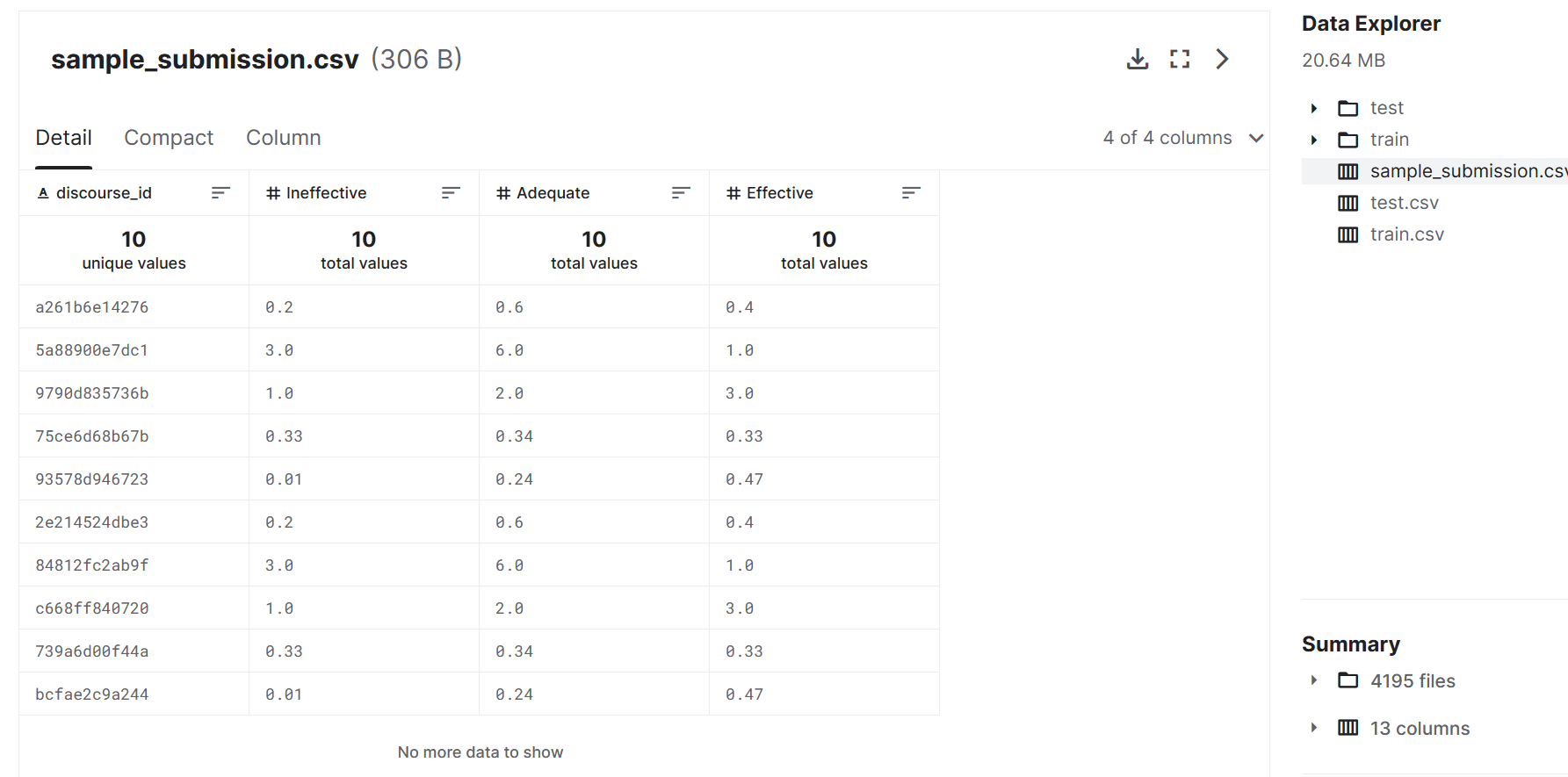
您必须提交一个 CSV 文件,其中包含每个话语元素的discourse_id以及三个有效性评级中每个元素的预测概率。行的顺序无关紧要。该文件必须具有标头,并且应具有以下格式:
discourse_id,Ineffective,Adequate,Effective
a261b6e14276,0.2,0.6,0.4
5a88900e7dc1,3.0,6.0,1.0
9790d835736b,1.0,2.0,3.0
75ce6d68b67b,0.33,0.34,0.33
93578d946723,0.01,0.24,0.47
2e214524dbe3,0.2,0.6,0.4
数据描述
Kaggle提供的数据集包含美国 6-12 年级学生撰写的议论文。这些文章由专家评分者注释,用于议论文中常见的话语元素:
Lead- 以统计数据、引文、描述或其他一些手段开始的介绍,以吸引读者的注意力并指向论文Position- 对主要问题的意见或结论Claim- 支持该立场的主张Counterclaim- 反驳另一项主张或对该立场提出相反理由的主张Rebuttal- 反驳反诉的主张Evidence- 支持主张、反诉或反驳的想法或例子。
Concluding Statement- 重申声明的结论性声明
参赛者的任务是预测每个话语元素的质量等级。人类读者将每个修辞或论证元素按质量递增的顺序评为以下之一:
- Ineffective
- Adequate
- Effective
训练数据
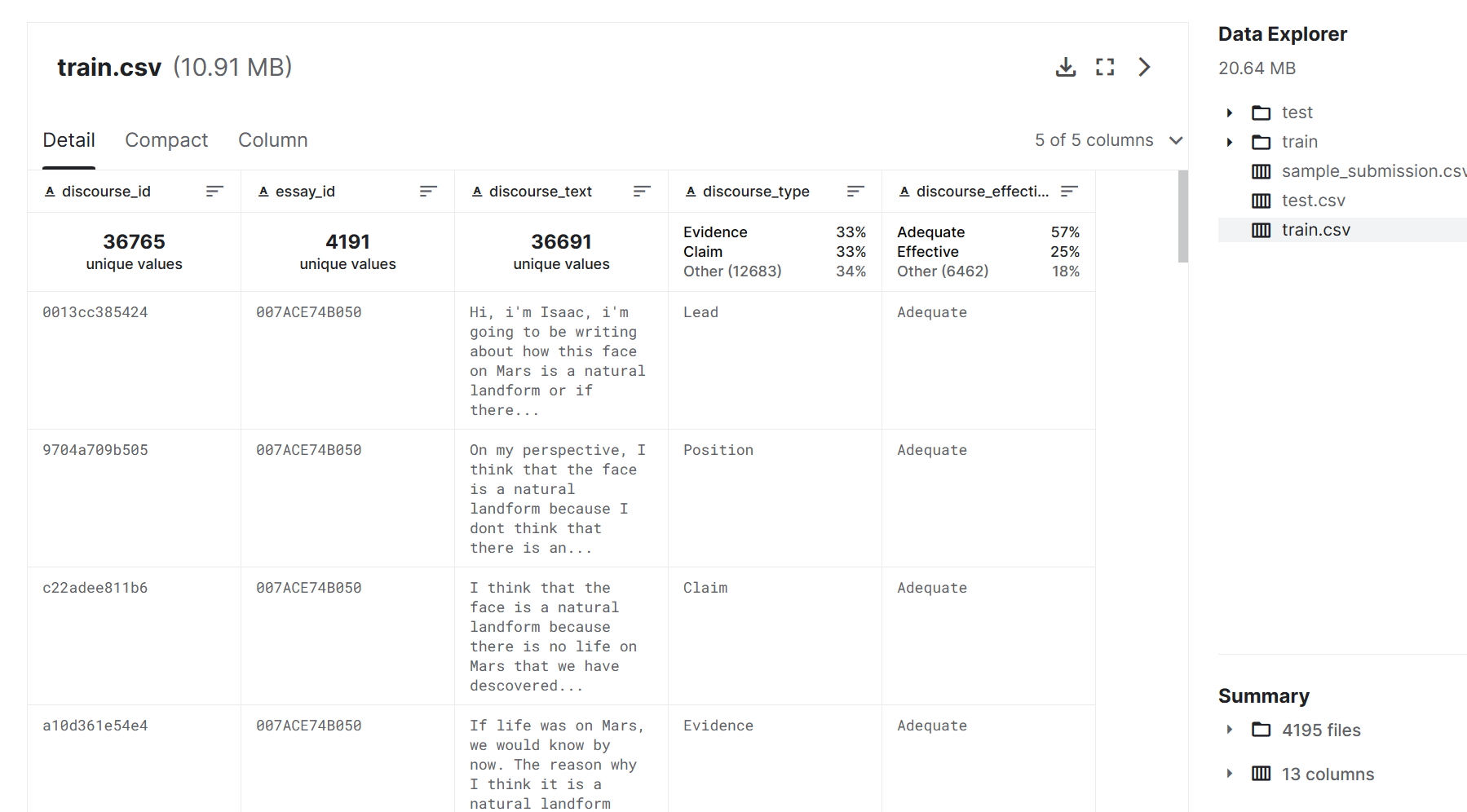
训练集包含一个 .csv 文件,其中包含每篇文章的注释话语元素,包括质量评级,以及包含每篇文章全文的 .txt 文件。 重要的是要注意,论文的某些部分将没有注释(即,它们不属于上述分类之一)并且它们将缺乏质量评级。不包括 train.csv 中未注释的部分。
train.csv- 包含测试集中所有文章的注释话语元素。discourse_id- 话语元素的 ID 代码essay_id- ID - 论文响应的 ID 代码。 此 ID 代码对应于 train/ 文件夹中的全文文件的名称。discourse_text- 话语元素的文本。discourse_type- 话语元素的类标签。discourse_type_num- 论述元素的枚举类标签。discourse_effectiveness- 话语元素的质量评级,目标。
为了帮助参赛者编写提交代码,kaggle提供了一些从测试集中选择的示例实例。 当参赛者 提交笔记本进行评分时,此示例数据将替换为实际测试数据,包括sample_submission.csv 文件。
test/- 包含来自测试集的示例文章的文件夹。 实际测试集包含大约 3,000 篇论文,格式与训练集论文类似。 测试集论文不同于训练集论文。test.csv- 测试集文章的注释,包含train.csv的所有字段,除了目标discourse_effectiveness。sample_submission.csv- 格式正确的示例提交文件。