首先看一下数据生成:

在预处理阶段会将label经过ont-hot编码转换为35个通道,即每个通道都是由(0,1)组成。

在train文件中,对生成器和判别器分别进行更新,根据loss的不同,分别计算对于的损失:
loss_G, losses_G_list = model(image, label, "losses_G", losses_computer)
loss_D, losses_D_list = model(image, label, "losses_D", losses_computer)
在model中:
from models.sync_batchnorm import DataParallelWithCallback
import models.generator as generators
import models.discriminator as discriminators
import os
import copy
import torch
import torch.nn as nn
from torch.nn import init
import models.losses as losses
class DP_GAN_model(nn.Module):
def __init__(self, opt):
super(DP_GAN_model, self).__init__()
self.opt = opt
#--- generator and discriminator ---
self.netG = generators.DP_GAN_Generator(opt).cuda()
if opt.phase == "train" or opt.phase == "eval":
self.netD = discriminators.DP_GAN_Discriminator(opt)
self.print_parameter_count()
self.init_networks()
#--- EMA of generator weights ---
with torch.no_grad():
self.netEMA = copy.deepcopy(self.netG) if not opt.no_EMA else None
#--- load previous checkpoints if needed ---
self.load_checkpoints()
#--- perceptual loss ---#
if opt.phase == "train":
if opt.add_vgg_loss:
self.VGG_loss = losses.VGGLoss(self.opt.gpu_ids)
self.GAN_loss = losses.GANLoss()
self.MSELoss = nn.MSELoss(reduction='mean')
def align_loss(self, feats, feats_ref):
loss_align = 0
for f, fr in zip(feats, feats_ref):
loss_align += self.MSELoss(f, fr)
return loss_align
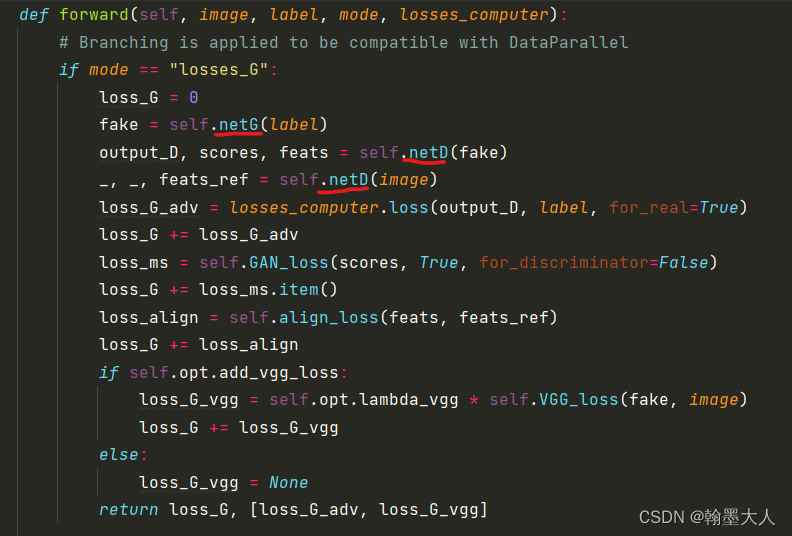
def forward(self, image, label, mode, losses_computer):
# Branching is applied to be compatible with DataParallel
if mode == "losses_G":
loss_G = 0
fake = self.netG(label)
output_D, scores, feats = self.netD(fake)
_, _, feats_ref = self.netD(image)
loss_G_adv = losses_computer.loss(output_D, label, for_real=True)
loss_G += loss_G_adv
loss_ms = self.GAN_loss(scores, True, for_discriminator=False)
loss_G += loss_ms.item()
loss_align = self.align_loss(feats, feats_ref)
loss_G += loss_align
if self.opt.add_vgg_loss:
loss_G_vgg = self.opt.lambda_vgg * self.VGG_loss(fake, image)
loss_G += loss_G_vgg
else:
loss_G_vgg = None
return loss_G, [loss_G_adv, loss_G_vgg]
if mode == "losses_D":
loss_D = 0
with torch.no_grad():
fake = self.netG(label)
output_D_fake, scores_fake, _ = self.netD(fake)
loss_D_fake = losses_computer.loss(output_D_fake, label, for_real=False)
loss_ms_fake = self.GAN_loss(scores_fake, False, for_discriminator=True)
loss_D += loss_D_fake + loss_ms_fake.item()
output_D_real, scores_real, _ = self.netD(image)
loss_D_real = losses_computer.loss(output_D_real, label, for_real=True)
loss_ms_real = self.GAN_loss(scores_real, True, for_discriminator=True)
loss_D += loss_D_real + loss_ms_real.item()
if not self.opt.no_labelmix:
mixed_inp, mask = generate_labelmix(label, fake, image)
output_D_mixed, _, _ = self.netD(mixed_inp)
loss_D_lm = self.opt.lambda_labelmix * losses_computer.loss_labelmix(mask, output_D_mixed, output_D_fake,
output_D_real)
loss_D += loss_D_lm
else:
loss_D_lm = None
return loss_D, [loss_D_fake, loss_D_real, loss_D_lm]
if mode == "generate":
with torch.no_grad():
if self.opt.no_EMA:
fake = self.netG(label)
else:
fake = self.netEMA(label)
return fake
if mode == "eval":
with torch.no_grad():
pred, _, _ = self.netD(image)
return pred
def load_checkpoints(self):
if self.opt.phase == "test":
which_iter = self.opt.ckpt_iter
path = os.path.join(self.opt.checkpoints_dir, self.opt.name, "models", str(which_iter) + "_")
if self.opt.no_EMA:
self.netG.load_state_dict(torch.load(path + "G.pth"))
else:
self.netEMA.load_state_dict(torch.load(path + "EMA.pth"))
elif self.opt.phase == "eval":
which_iter = self.opt.ckpt_iter
path = os.path.join(self.opt.checkpoints_dir, self.opt.name, "models", str(which_iter) + "_")
self.netD.load_state_dict(torch.load(path + "D.pth"))
elif self.opt.continue_train:
which_iter = self.opt.which_iter
path = os.path.join(self.opt.checkpoints_dir, self.opt.name, "models", str(which_iter) + "_")
self.netG.load_state_dict(torch.load(path + "G.pth"))
self.netD.load_state_dict(torch.load(path + "D.pth"))
if not self.opt.no_EMA:
self.netEMA.load_state_dict(torch.load(path + "EMA.pth"))
def print_parameter_count(self):
if self.opt.phase == "train":
networks = [self.netG, self.netD]
else:
networks = [self.netG]
for network in networks:
param_count = 0
for name, module in network.named_modules():
if (isinstance(module, nn.Conv2d)
or isinstance(module, nn.Linear)
or isinstance(module, nn.Embedding)):
param_count += sum([p.data.nelement() for p in module.parameters()])
print('Created', network.__class__.__name__, "with %d parameters" % param_count)
def init_networks(self):
def init_weights(m, gain=0.02):
classname = m.__class__.__name__
if classname.find('BatchNorm2d') != -1:
if hasattr(m, 'weight') and m.weight is not None:
init.normal_(m.weight.data, 1.0, gain)
if hasattr(m, 'bias') and m.bias is not None:
init.constant_(m.bias.data, 0.0)
elif hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
init.xavier_normal_(m.weight.data, gain=gain)
if hasattr(m, 'bias') and m.bias is not None:
init.constant_(m.bias.data, 0.0)
if self.opt.phase == "train":
networks = [self.netG, self.netD]
else:
networks = [self.netG]
for net in networks:
net.apply(init_weights)
def put_on_multi_gpus(model, opt):
if opt.gpu_ids != "-1":
gpus = list(map(int, opt.gpu_ids.split(",")))
model = DataParallelWithCallback(model, device_ids=gpus).cuda()
else:
model.module = model
assert len(opt.gpu_ids.split(",")) == 0 or opt.batch_size % len(opt.gpu_ids.split(",")) == 0
return model
def preprocess_input(opt, data):
data['label'] = data['label'].long()
if opt.gpu_ids != "-1":
data['label'] = data['label'].cuda()
data['image'] = data['image'].cuda()
label_map = data['label']
bs, _, h, w = label_map.size()
nc = opt.semantic_nc
if opt.gpu_ids != "-1":
input_label = torch.cuda.FloatTensor(bs, nc, h, w).zero_()
else:
input_label = torch.FloatTensor(bs, nc, h, w).zero_()
input_semantics = input_label.scatter_(1, label_map, 1.0)
return data['image'], input_semantics
def generate_labelmix(label, fake_image, real_image):
target_map = torch.argmax(label, dim = 1, keepdim = True)
all_classes = torch.unique(target_map)
for c in all_classes:
target_map[target_map == c] = torch.randint(0,2,(1,)).cuda()
target_map = target_map.float()
mixed_image = target_map*real_image+(1-target_map)*fake_image
return mixed_image, target_map
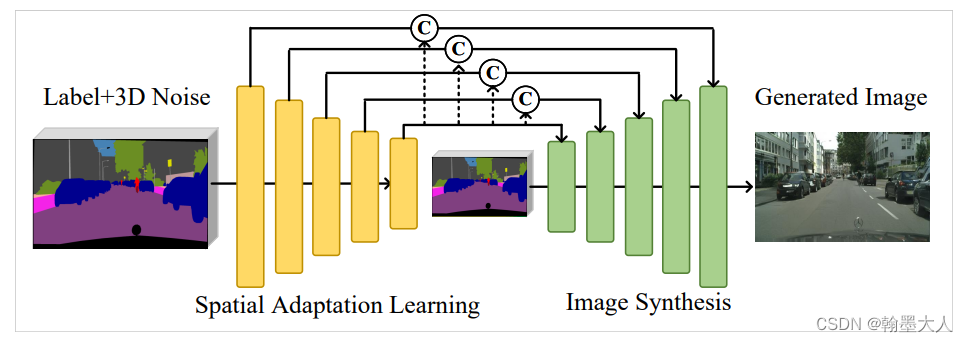
首先看生成器流程:
标签输入到生成器中得到fake image,fake image 和 real image 共同输入到判别器中得到中间变量输出,接着分别计算四个损失。我们需要明白生成器和辨别器模型的搭建,损失计算过程。
首先是生成器的组成:
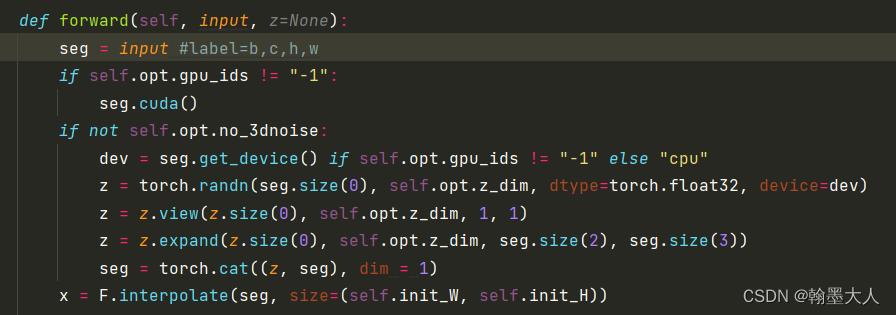
输入标签大小是(b,c,h,w),首先z等于一个正态分布的随机数,大小为(b,64),接着view为(b,64,1,1),再扩张到(b,64,h,w)和(b,c,h,w)沿着通道维度拼接起来。将拼接的结果上采样到W和H大小。
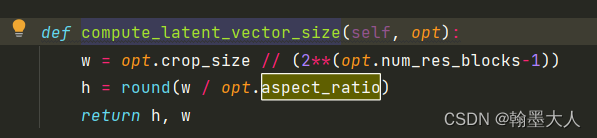
其中在CityscapesDataset指定了:
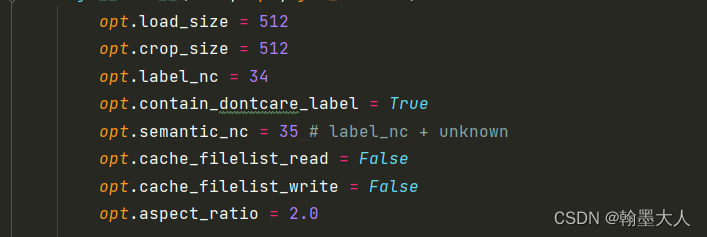
则w=512//2^5=16,h=16/2=8.

令s等于input label,输入到pyrmid中,生成结果添加到列表中。
self.seg_pyrmid = nn.ModuleList([])
if not self.opt.no_3dnoise:
self.fc = nn.Conv2d(self.opt.semantic_nc + self.opt.z_dim, 16 * ch, 3, padding=1)
self.seg_pyrmid.append(nn.Sequential(nn.Conv2d(self.opt.semantic_nc + self.opt.z_dim, 32, 3, stride=1, padding=1), nn.BatchNorm2d(32), nn.ReLU(inplace=True)))
else:
self.fc = nn.Conv2d(self.opt.semantic_nc, 16 * ch, 3, padding=1)
self.seg_pyrmid.append(nn.Sequential(nn.Conv2d(self.opt.semantic_nc, 32, 3, stride=1, padding=1), nn.BatchNorm2d(64), nn.ReLU(inplace=True)))
self.seg_pyrmid.append(nn.Sequential(nn.Conv2d(32, 64, 3, stride=1, padding=1), nn.BatchNorm2d(64), nn.ReLU(inplace=True)))
for i in range(len(self.channels)-2):
self.seg_pyrmid.append(nn.Sequential(nn.Conv2d(64, 64, 3, stride=2, padding=1), nn.BatchNorm2d(64), nn.ReLU(inplace=True)))
而pyrmid是一个modulist,便利添加的每一个module,生成一个结果:
首先将标签图和噪声拼接起来经过一个3x3卷积,输出通道变为32,再经过一个1x1卷积,输出通道变为64.再经过经过5个步长为2的3x3卷积,下采样32倍。这样pyrmid列表中就有7个结果。
接着将已经采样的x输入到Fc中,输出通道是1024.这里需要清楚两个变量x,和pyrmid.
1:x是输入下采样到(H,W)大小的label+noise.
2:pyrmid是储存经过七次(五次下采样)卷积之后的label+noise。
接着将pyrmid最后一个值采样到x的大小。然后和pyrmid的第i个值拼接在一起。

对应于:
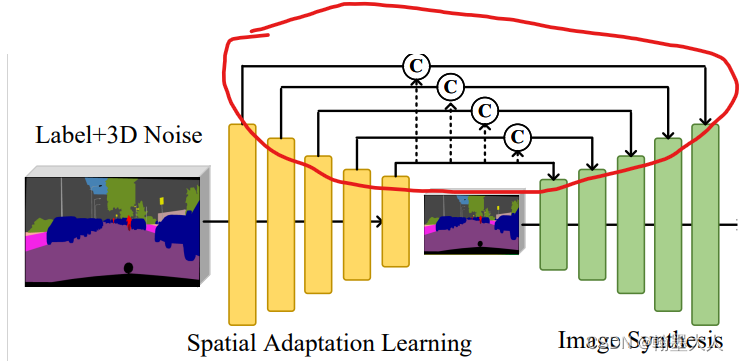
每拼接一次生成的值和经过Fc之后的label+noise共同作为输入:

输入到SPADE块中:
首先要判断SPAD的两个参数即输入通道是否相等。
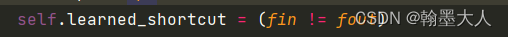
如果相等就输入到SPADE模块,如果不等令变量等于输入值。

其中最后一个参数是类别值:在Cityscape数据集设定语义标签是34类。有一类是未知,加上噪声的64个通道。

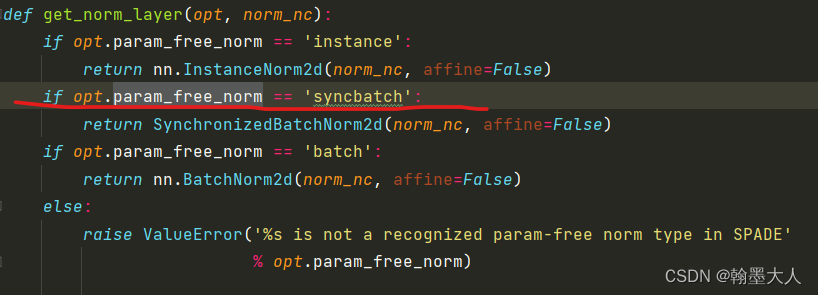
SPADE:
class SPADE(nn.Module):
def __init__(self, opt, norm_nc, label_nc):
super().__init__()
self.first_norm = get_norm_layer(opt, norm_nc)
ks = opt.spade_ks
nhidden = 128
pw = ks // 2
#self.mlp_shared = nn.Sequential(
# nn.Conv2d(label_nc, nhidden, kernel_size=ks, padding=pw),
# nn.ReLU()
#)
self.mlp_gamma = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw)
self.mlp_beta = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw)
def forward(self, x, segmap):
normalized = self.first_norm(x)
#segmap = F.interpolate(segmap, size=x.size()[2:], mode='nearest')
#actv = self.mlp_shared(segmap)
actv = segmap
gamma = self.mlp_gamma(actv)
beta = self.mlp_beta(actv)
out = normalized * (1 + gamma) + beta
return out
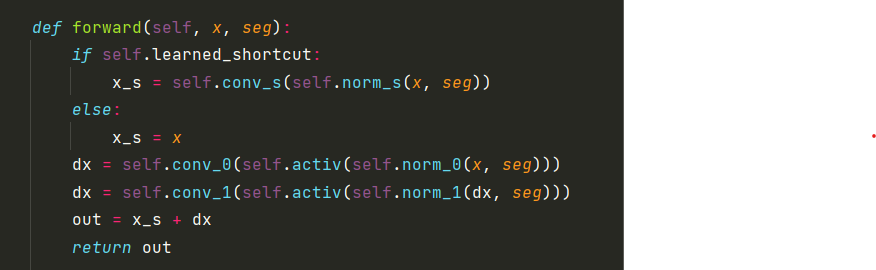
公式:

首先X经过一个norm层,即为分布式BN。

接着使用卷积学习β和γ。


卷积核大小都为3,padding为1。
接着经过bn之后的变量和γ相乘在和β相加,再和经过归一化之后的x相加。

接着:x和seg经过相同的norm操作。再进过一个LeakyReLU,再进行一个卷积层。中间有个midlayer过渡。


输出的结果经过一个跳连接得到最后输出。
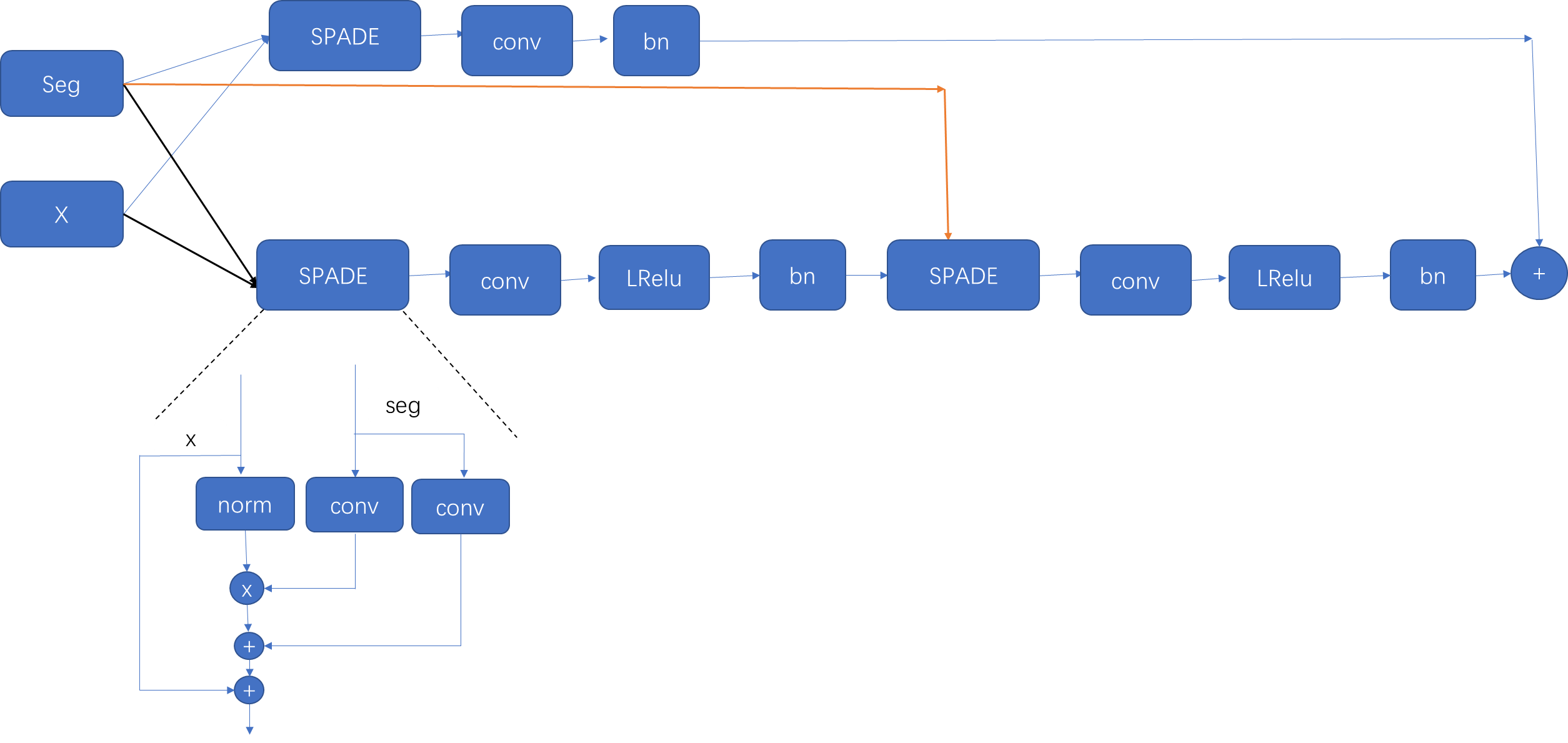
经过SPADE之后的输出上采样两倍作为输入输入到下一个SPADE中。
最终输出一个通道为3的RGB图片。