序列化器Serializer
1、序列化:序列化器会把模型对象转换成字典,经过Response以后变成JSON格式字符串
2、反序列化:把客户端发送过来的数据,经过Request以后变成字典,序列化器可以把字典转成模型
3、反序列化:完成数据校验功能
# diango 服务终端
python manage.py shell
定义序列化器
class StudentSerializer(serializers.Serializer):
'''
在视图内获取了模型类里面的值(QuerySet类型)
实现的结果等同于基于QuerySet内容进行for循环这个序列化器,将QuerySet中的每个对象属性值
赋给以下和对象属性名相同的字段作为值
'''
id = serializers.IntegerField() # 接收模型类对象的id属性值
name = serializers.CharField() # 接收模型类对象的name属性值
sex = serializers.CharField()
age = serializers.IntegerField()
phone = serializers.CharField()
本质相当于key:value的形式接收值
1、视图传递了{“name”:‘jack’}到序列化器内
2、序列化器定义name字段来接收’jack’这个值
serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
Serializer对象使用
Serializer类构造方法
Serializer(instance=None, data=empty, **kwarg)
1、用于序列化时,将模型类对象传入instance参数
2、用于反序列化时,将要被反序列化的数据传入data参数
3、除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如:
serializer = StudentSerializer(name, context={
'request': request})
通过context参数附加的数据,可以通过Serializer对象的context属性获取。
1、使用序列化器的时候一定要注意,序列化器声明了以后,不会自动执行,需要我们在视图中进行调用才可以。
2、序列化器无法直接接收数据,需要我们在视图中创建序列化器对象时把使用的数据传递过来。
3、序列化器的字段声明类似于我们前面使用过的表单系统。
4、开发restful api时,序列化器会帮我们把模型数据转换成字典.
5、DRF提供的视图会帮我们把字典转换成json,或者把客户端发送过来的数据转换字典.
序列化器使用阶段
1、在客户端请求时,使用序列化器可以完成对数据的反序列化。
2、在服务器响应时,使用序列化器可以完成对数据的序列化。
序列化器使用方法
基本使用
通过将值传递给序列化器完成对值的序列化,DRF内会序列化成JSON格式,然后进行响应
from rest_framework.views import APIView
from rest_framework.response import Response
from app01 import serializer
from app01 import models
class BookView(APIView):
def get(self,request):
# 获取所有学生对象保存在QuerySet查询集里面
student_list = models.Student.objects.all()
# 如果传递给序列化器的是一个QuerySet查询集类型的数据,那么则需要增加参数many=True
ser = serializer.StudentSerializer(instance=student_list,many=True)
# 序列化后的数据保存在序列化器对象的data属性内
return Response(ser.data)
# views
class SkrAutoView(GenericAPIView):
def get(self, request):
queryset = UserInfo.objects.all()
print(f'queryset:{
queryset}')
print("============")
ser = SkrSerializers(instance=queryset, many=True)
print(ser.data)
user_list = []
for user in queryset:
user_list.append({
"id": user.id,
"name": user.name,
"sex": user.sex,
"age": user.age,
"phone": user.phone
})
return JsonResponse(user_list, safe=False, json_dumps_params={
"ensure_ascii": False})
# Serializers
class SkrSerializers(serializers.Serializer):
SEX_CHOICES = (
(0, '未知'),
(1, '男'),
(2, '女')
)
id = serializers.IntegerField(read_only=True)
name = serializers.CharField(max_length=10, error_messages={
'max_length': '名称不能超过10位数哦'}, required=False)# 非必传
sex = serializers.ChoiceField(choices=SEX_CHOICES, label="性别", required=False)
age = serializers.IntegerField(max_value=99, error_messages={
'max_value': '输入的年龄不能大过99岁!!'},
required=False)
phone = serializers.CharField(required=False)
def create(self, validated_data): # 校验合格的数据
userinfo = UserInfo.objects.create(**validated_data) # 将字典形式的数据拆分成关键字形式
return userinfo # 返回新增数据后的对象,Response进行序列化成JSON格式响应到客户端
我们在序列化器里面定义的字段决定了能够响应给客户端什么样的数据,如果只定义了id字段,那么就字段接收到QuerySet里对象的id属性,返回给客户端的自然也就只有id字段的数据了
反序列化器使用 - post请求
使用场景:对传递进来的数据有一定要求时就要对其进行校验,使用序列化器可以达到这一目的。
# 序列化器
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
from app01 import models
class StudentSerializer(serializers.Serializer):
# required字段可以不传值(因为在模型类里面它是一个自增的字段)
id = serializers.IntegerField(required=False)
name = serializers.CharField(max_length=10,error_messages={
'max_length':'名称不能超过10位数哦'},required=False)
sex = serializers.CharField(required=False)
age = serializers.IntegerField(max_value=99,error_messages={
'max_value':'输入的年龄不能大过99岁!!'},required=False)
phone = serializers.CharField(required=False)
def validate_name(self, data): # name字段的局部钩子
'''
:param data: 当前字段的值
:return:
'''
if data.startswith('zz'):
raise ValidationError('名称不能以zz开头')
return data
def validate(self, attrs): # 全局钩子
'''
中间可以有校验过程
:param attrs: attr是一个字典的形式,可以拿到任意字段的值
:return:
'''
return attrs
def create(self, validated_data): # 校验合格的数据
userinfo = UserInfo.objects.create(**validated_data) # 将字典形式的数据拆分成关键字形式
return userinfo # 返回新增数据后的对象,Response进行序列化成JSON格式响应到客户端
# 视图层
from rest_framework.views import APIView
from rest_framework.response import Response
from app01 import serializer
from app01 import models
class BookView(APIView):
def get(self,request):
student_list = models.Student.objects.all()
ser = serializer.StudentSerializer(instance=student_list,many=True)
return Response(ser.data)
def post(self,request):
# request.data属性内具备了post请求发送的数据,将数据传递给序列化器
ser = serializer.StudentSerializer(data=request.data)
if ser.is_valid(): # 判断是否通过序列化器的校验
'''
如果调用序列化器没有传递instance参数,且我们调用了save方法,
那么同时也会执行save方法内的create方法,并进行新增数据,但DRF并不允许我们这么做
DRF框架需要我们重写该方法才能新增数据,所以我们通常会在序列化容器内重写create方法
'''
ser.save()
return Response(ser.data) # 经过序列化器后的数据都保存在data属性内
else:
# 校验不合格的错误信息会集成在序列化器对象的errors属性内
return Response({
'status':102,'error':'您输入的内容不合法,请重新输入','msg':ser.errors})
反序列化器使用 - put请求
# views
# 笔者重写了一下Response方法,每次都能够返回状态码
class MyResponse(Response):
def __init__(self, data=None, status=100):
super().__init__(status=status, data=data)
self.data = {
'status': status, 'msg': data}
class BookDetailView(APIView):
def put(self, request, id):
obj = models.Student.objects.filter(pk=id).first()
response = {
}
if obj:
ser = serializer.StudentSerializer(instance=obj,data=request.data)
if ser.is_valid(): # 判断数据是否符合我们校验规则
ser.save()
# 当向序列化器传递了instance参数时,且调用了save方法,那么就会执行其内的update方法,所以DRF依旧需要我们重写update方法
response['status'] = 200
response['data'] = ser.data
else:
response['status'] = 101
response['data'] = ser.errors # 返回错误信息
else:
response['status'] = 404
response['data'] = '修改的数据不存在'
return Response(response)
# 序列化器
class StudentSerializer(serializers.Serializer):
# code....>>>
def update(self, instance, validated_data):
'''
:param instance: 更新的对象
:param validated_data: 更新的数据
:return:
'''
instance.__dict__.update(validated_data) # 对象里面key与put请求提交过来的key相同的话,值进行更新
instance.save()
return instance # 将对象返回,序列化成JSON格式响应到页面
delete请求
class BookDetailView(APIView):
def delete(self,request,id):
obj = models.Student.objects.filter(pk=id)
response = {
}
if obj:
obj.delete()
response['status'] = 200
response['data'] = '' # 删除成功返回空
else:
response['status'] = 404
response['data'] = '需要删除的数据不存在'
return Response(response)
序列化器常用的字段及参数
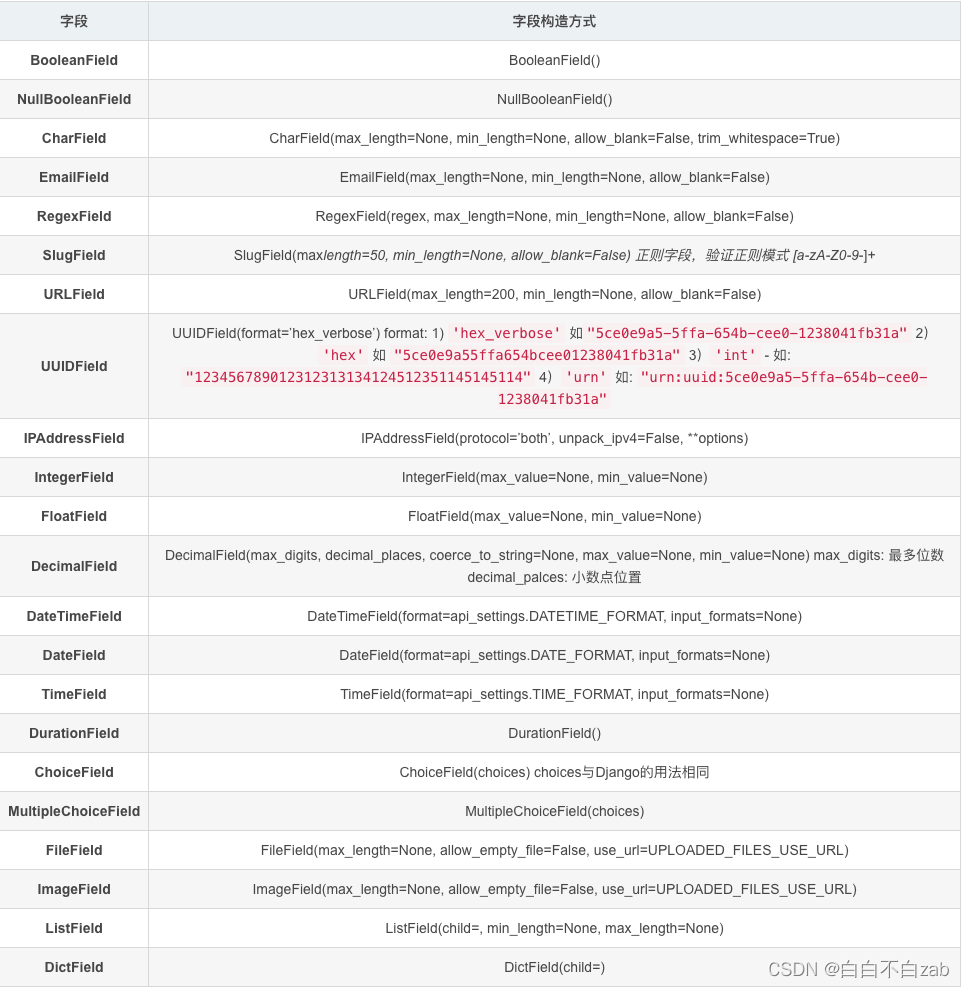
注:在序列化器内使用这些字段则是将接收到的字段转换成某个类型的。
id字段值为int类型,我们通过id=serializer.CharField()来接收,那么返回到视图里面的则是字符串类型了。
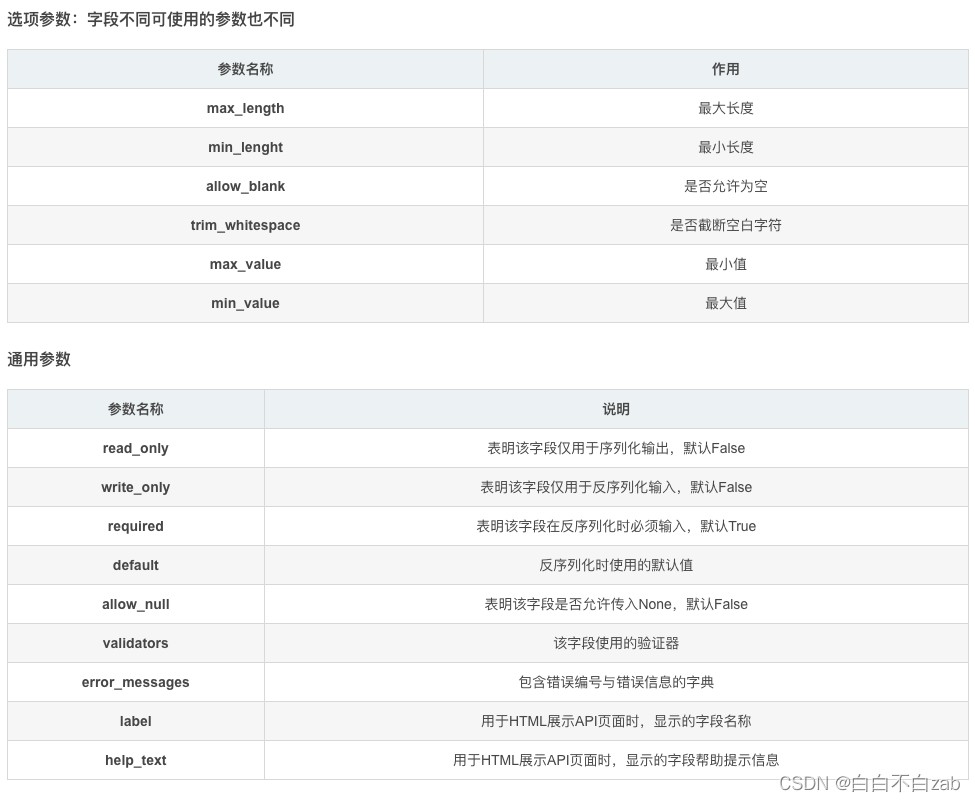
使用序列化器自定义字段、名称
当数据传递到了序列化器里面以后,我们可以在序列化器里面定义字段内容、以及返回哪些字段、及自定义字段
# demo
ph = serializers.SerializerMethodField()
def get_ph(self,obj): # 针对哪个序列化器字段的操作
# obj拿到的是传入到当前序列化器的对象
return obj.phone + "9999" # 将对象的phone属性值赋给ph字段,然后返回到视图
自定义字段名称
# 把phone字段改名叫做ppp
ppp = serializers.CharField(source='phone') # ppp字段值来自哪个字段
自定义返回给视图的数据、及read_only、write_only参数使用
- 视图得到的数据取决于序列化器的字段,当我们序列化器定义了如下内容
class StudentSerializer(serializers.Serializer):
id = serializers.IntegerField(required=False)
name = serializers.CharField()
sex = serializers.CharField()
age = serializers.IntegerField()
# phone = serializers.CharField()
- 视图只能将序列化器定义返回4个字段转换成JSON格式响应到客户端、
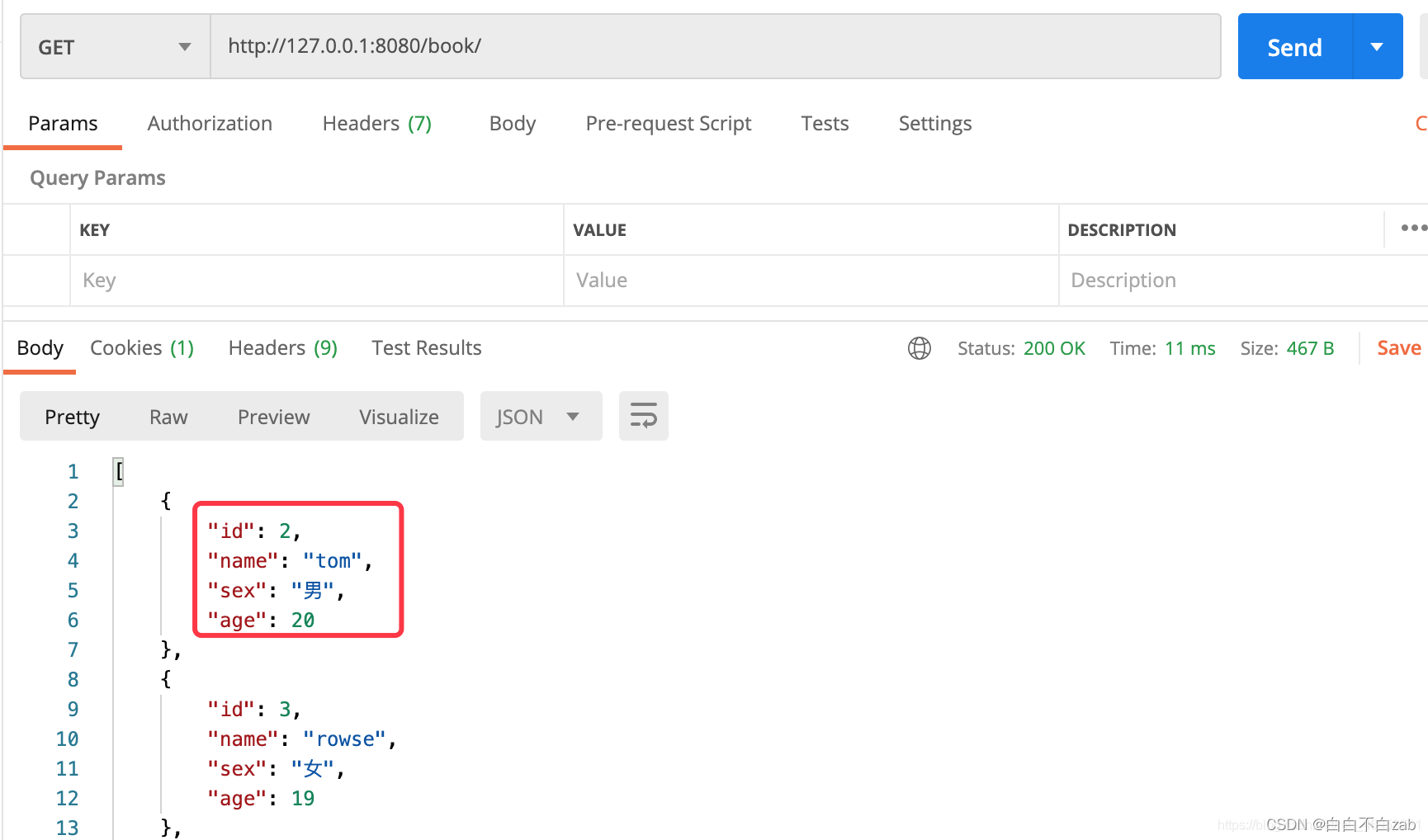
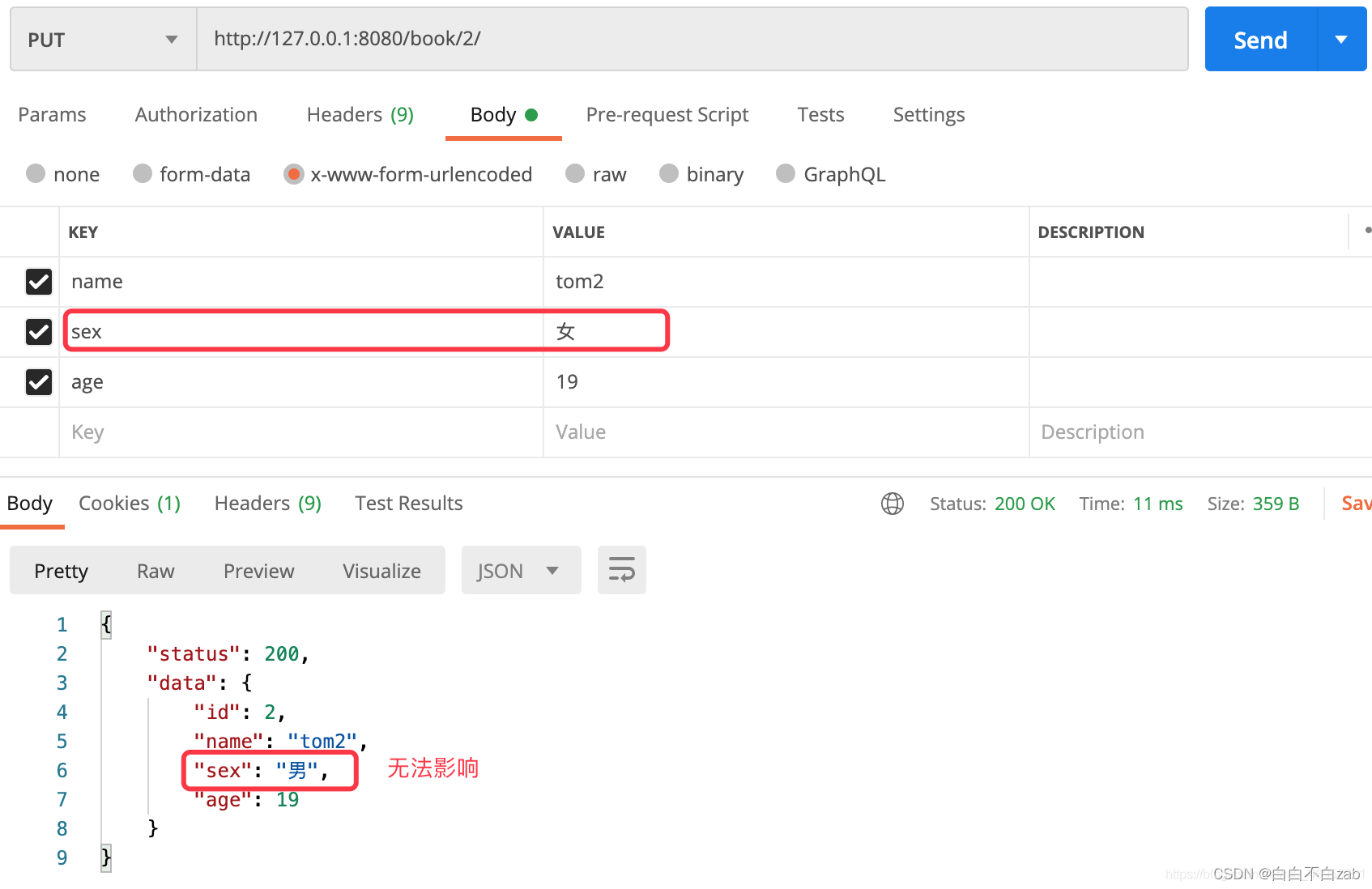
- 而如果字段设置了write_onely=True参数,那么该字段就只能作为每次接收数据的作用,而不会返回到视图里面。
class StudentSerializer(serializers.Serializer):
id = serializers.IntegerField(required=False)
name = serializers.CharField()
sex = serializers.CharField(write_only=True) # 不会返回到视图
age = serializers.IntegerField()
- 设置了write_only只是不用于返回给前端,调用时还是需要传值的
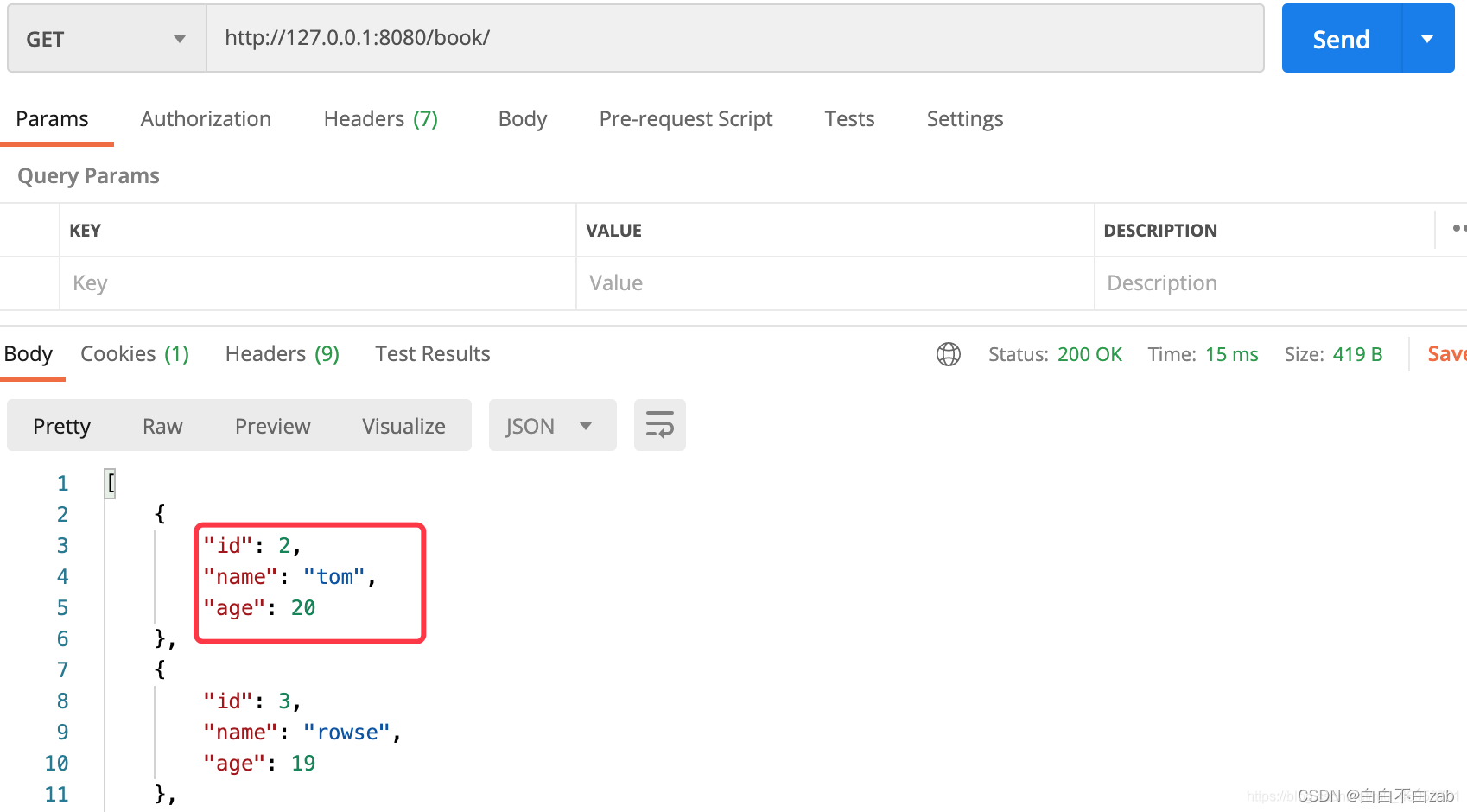
- 当某个字段设置了read_only=True参数后,那么就只能作为每次返回到视图响应到客户端的作用,而POST或PUT请求则不能影响该字段。
class StudentSerializer(serializers.Serializer):
id = serializers.IntegerField(required=False)
name = serializers.CharField()
sex = serializers.CharField(read_only=True)
age = serializers.IntegerField()
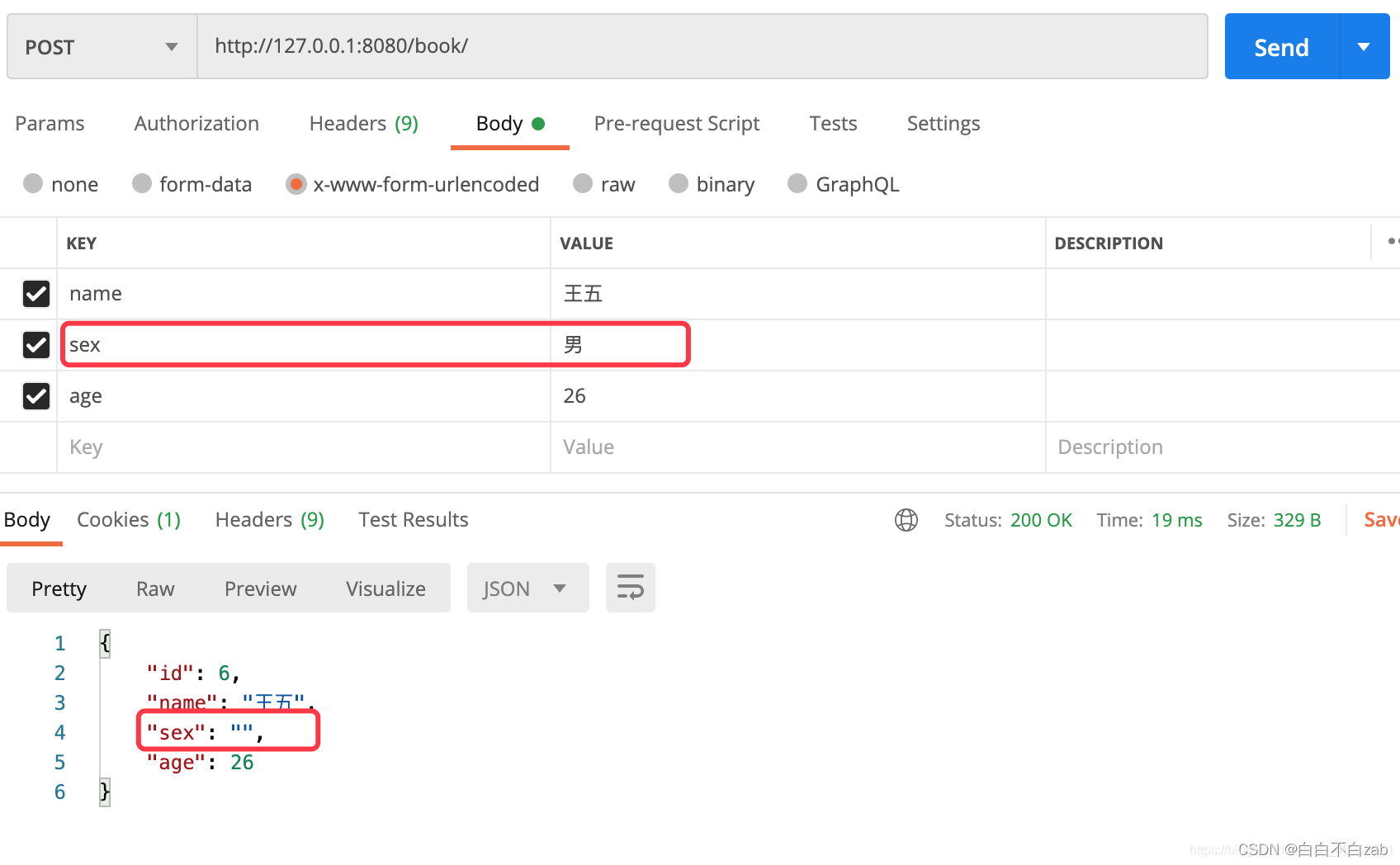
- 无法给设置了read_only=True的字段新增值或修改值
模型类序列化器
自定义的序列化器需要我们自己去手动创建每一个字段(太繁琐),模型类序列化器可以帮助我们省去这个繁琐步骤。
DRF提供了模型类序列化器:Model Serializer。作用就是简化对应Django模型类的序列化器的定义。
ModelsSerializer与常规的Serializer相同,但提供了如下主要功能:
1、基于模型类自动生成一系列字段(不需要我们一一手动定义)
2、基于模型类自动为Serializer生成Validators,比如字段唯一的校验器
3、不需要重写create()和update()实现新增、修改功能。
继承ModelSerializer类的序列化器是基于Meta内部类来完成一些字段定义:
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = models.Student # 指明参照的模型类
fields = '__all__' # 包含模型类的所有字段
# fields = ('id','name') 只使用id、name字段作为序列化字段
# exclude = ('sex') 排除sex字段使用其它作为序列化字段
# read_only_fields = ('sex','age') 只读字段,即仅用于序列化输出的字段
# extra_kwargs,为字段增加一些参数
extra_kwargs = {
'create_date':{
'required':False,'read_only':True}
}
'''
可以自定义一些字段,返回给视图,但是需要设置成read_only=True,required=True,不然每次向这个序列化传的值也要包括这些自定义的字段,导致无法入库。
这里可以与继承Serializer类定义完字段以后使用方式相同。
ddd = serializer.CharField(source='name')
注意:一定要写在Meta类外面
'''
并且当我们如果以POST、PUT请求向数据库新增、修改数据的话,也是不需要重写create、update方法了。
这里我们将上面的StudentSerializer内容替换成以下:
class StudentSerializer(serializers.ModelSerializer):
class Meta:
model = models.Student # 指明参照的模型类
fields = '__all__' # 包含模型类的所有字段
# 为字段添加一些参数
extra_kwargs = {
'create_date': {
'required': False, 'read_only': True}
}
现在就可以直接向后端提交POST请求,但并没有重写create方法
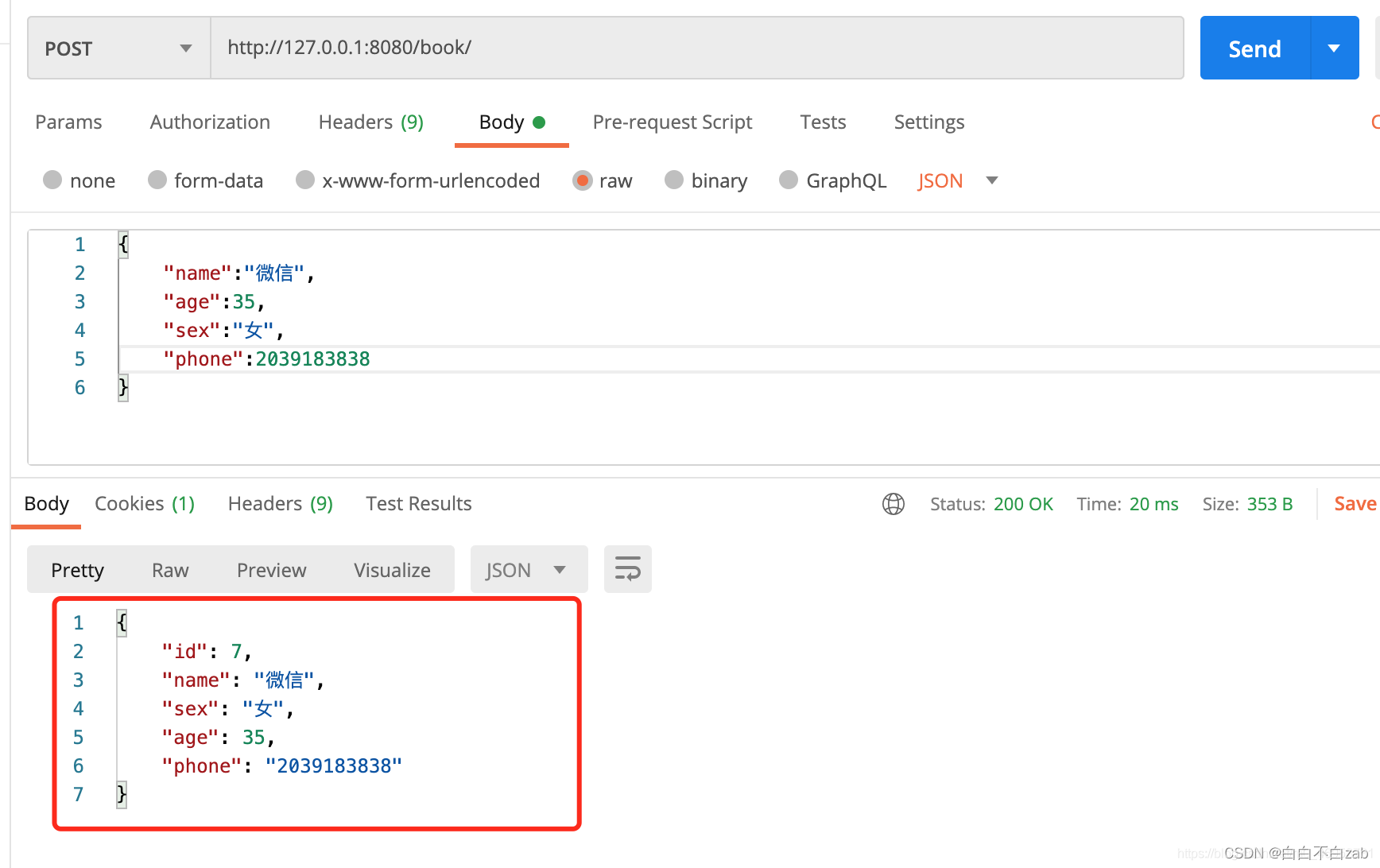
没有重写create方法就能实现新增数据的目的,这是因为ModelSerializer已经帮助我们重写了create与update方法
create与update方法
在使用Serializer作为序列化器继承类的话,我们新增、修改数据有两种方案:
1、在is_valid里面将数据手动存储到数据库
2、重写create、update方法接收过滤后的值,然后存储到数据库
但是以上两种都过于麻烦,需要我们手动将数据存储到数据库,而ModelSerializer类里面的create、update方法基本不需要我们重写了,除非需要将两张表之间的关联通过第三张表记录下来。这种情况即使继承了ModelSerializer类也是需要重写create或者update方法的。