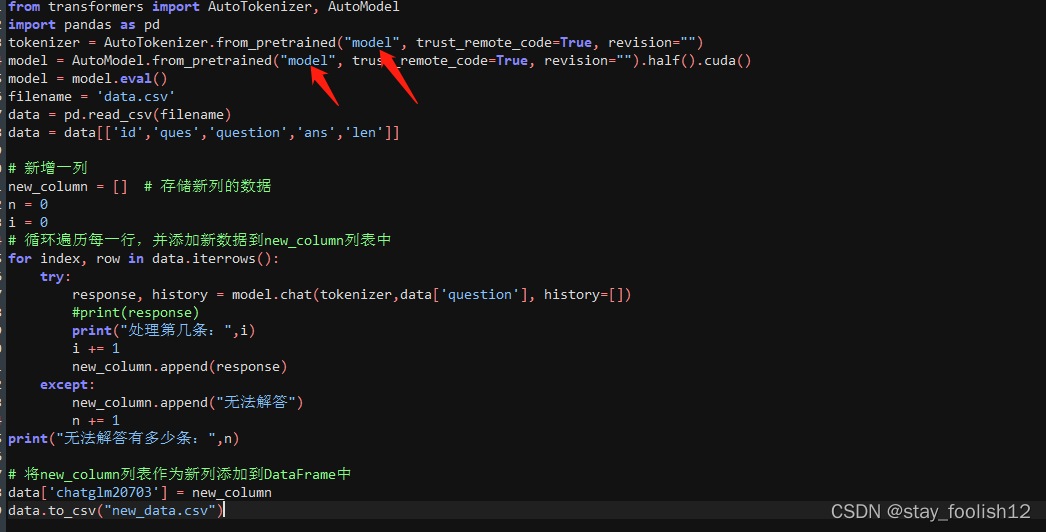
from transformers import AutoTokenizer, AutoModel
import pandas as pd
tokenizer = AutoTokenizer.from_pretrained("model", trust_remote_code=True, revision="")
model = AutoModel.from_pretrained("model", trust_remote_code=True, revision="").half().cuda()
model = model.eval()
filename = 'data.csv'
data = pd.read_csv(filename)
data = data[['id','ques','question','ans','len']]
# 新增一列
new_column = [] # 存储新列的数据
n = 0
i = 0
# 循环遍历每一行,并添加新数据到new_column列表中
for index, row in data.iterrows():
try:
response, history = model.chat(tokenizer,data['question'], history=[])
#print(response)
print("处理第几条:",i)
i += 1
new_column.append(response)
except:
new_column.append("无法解答")
n += 1
print("无法解答有多少条:",n)
# 将new_column列表作为新列添加到DataFrame中
data['chatglm20703'] = new_column
data.to_csv("new_data.csv")
修改的位置,model。
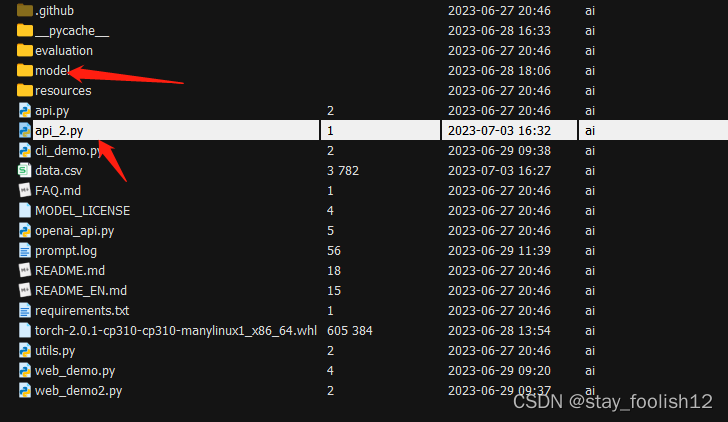
model目录下,放入你从下载的模型文件,比如,我这放的是chatglm2模型。
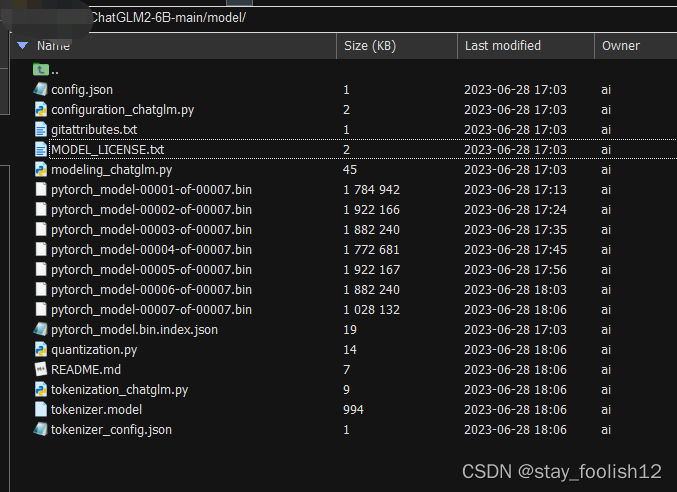
清华大学云盘 https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm2-6b&mode=list