- Makefile
1.1 结构:
targets:prerequisites
command
1.2 gcc编译:-g,-o,-c,-D,-w,-W,-Wall,-O3
-c:源文件进行编译汇编,但不进行链接
示例:
gcc -c test.cpp -o test
-c后跟多源文件情况
当-c后跟多个源文件,会为每个源文件生成一个.o文件,但此时是不能使用-o的。
参考链接:gcc编译选项-o和-c介绍_gcc -o_chengqiuming的博客-CSDN博客
1.3 自动化变量
| 自动化变量 |
说明 |
| $@ |
表示目标文件 |
| $% |
当目标文件是一个静态库文件时,代表静态库的一个成员名。 |
| $< |
表示第一个依赖文件。 |
| $^ |
代表的是所有依赖文件。 |
| $? |
所有比目标文件更新的依赖文件列表。 |
| $+ |
类似“$^”,但是它保留了依赖文件中重复出现的文件。主要用在程序链接时库的交叉引用场合。 |
| $* |
在模式规则和静态模式规则中,代表“茎”。“茎”是目标模式中“%”所代表的部分(当文件名中存在目录时, |
test:test.o test1.o test2.o
gcc -o $@ $^
test.o:test.c test.h
gcc -o $@ $<
test1.o:test1.c test1.h
gcc -o $@ $<
test2.o:test2.c test2.h
gcc -o $@ $<
GNU make 中在这些变量中加入字符 "D" 或者 "F" 就形成了一系列变种的自动化变量,这些自动化变量可以对文件的名称进行操作。
D表示目录部分,F表示文件部分。如:$(@D)、 $(@F)
1.4 目标文件搜索
4.1 VPATH
VPATH := src car
test:test.o
gcc -o $@ $^
先搜索 src 目录下的文件,再搜索 car 目录下的文件。
4.2 vpath
vpath test.c src car
在两个路径里搜索test.c文件
1.5 伪目标
clean:
rm -rf *.o test
二、shell
参考链接: https://www.jianshu.com/p/74e8739ddc01
2.1 shell脚本、
#!/bin/bash
echo "HelloWorld!"
2.2 流程控制语句
if – then – else – fi
if else fi
if elif fi
for 循环
while语句
until 循环(与while条件相反)
case ... esac
-eq/-ne/-gt/-ge/-lt/le
大于等于greater than or equal
-e 如果文件存在则为真
-r 如果文件存在且可读则为真
-w 如果文件存在且可写则为真
-x 如果文件存在且可执行则为真
-s 如果文件存在且至少有一个字符则为真
-d 如果文件且为目录则为真
-f 如果文件存在且为普通文件则为真
-c 如果文件存在且为字符型特殊文件则为真
-b 如果文件存在且为块特殊文件则为真
2.3 函数
示例:
#!/bin/bash
function timesFun(){
echo "这个函数会对两个数字进行乘法运算"
echo "请输入第一个数字"
read num1
echo "请输入第二个数字"
read num2
return $(( ${num1} * ${num2} ))
}
timesFun
echo -n "输入的两个数字的乘法值是 $? "
三、指针
与其他高级编程语言相比,C 语言可以更高效地对计算机硬件进行操作,而计算机硬件的操作指令,在很大程度上依赖于地址。
指针提供了对地址操作的一种方法,因此,使用指针可使得 C 语言能够更高效地实现对计算机底层硬件的操作。另外,通过指针可以更便捷地操作数组。在一定意义上可以说,指针是 C 语言的精髓。
3.1 内存与地址
参考链接:http://c.biancheng.net/c/pointer/
(1)&:取变量地址
(2)指针变量的定义:如int *p;
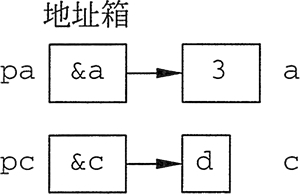
(3)“野”指针
int *pi,a; //pi未初始化,无合法指向,为“野”指针
*pi=3; //运行时错误!不能对”野”指针指向的空间做存入操作。该语句试图把 3 存入“野”指针pi所指的随机空间中,会产生运行时错误
(4)指针与数组
数组指针:例int (*p)[5]; 可表示二维数组
#define M 3
#define N 4
int a[M][N],i,j;
int (*p)[N]=a; // 等价于两条语句 int (*p)[N] ; p=a;
指针数组:例int * a[5];
int a0,a1,a2,a3,a4;
a[0]=&a0;
a[1]=&a1;
...
a[4]=&a4;
3.2 函数指针
参考链接:https://blog.csdn.net/Jacky_Feng/article/details/108953519
(1)函数指针的定义
若在程序中定义了一个函数,编译时,编译器会为函数代码分配一段存储空间,这段空间的起始地址(又称入口地址)称为这个函数的指针。
实例:
int func(int a,int b);//函数声明
int (*p) (int , int );//定义一个参数列表为两个int型的变量,返回值类型为int型的函数指针p
p=func;//函数指针p指向函数func的起始地址
(2)函数指针的应用
调用函数指针p指向的函数
(*p)(3, 5);
3.3 回调函数
程序通过参数把该函数的函数指针传递给了其它函数,在那个函数里面调用这个函数指针就相当于调用这个函数,这样的过程就叫回调,而被调用的函数就叫回调函数。
示例:
#include <iostream>
using namespace std;
//1.定义回调函数
void print(int n)
{
for (int i = 0; i < n; i++) {
cout << "hello world" << endl;
}
}
//2.定义回调函数原型(函数指针)
typedef void (*CallbackFun)(int);
//3.定义注册回调函数
void registCallback(CallbackFun callback,int n)
{
callback(n);
}
int main()
{
//4.将print函数指针作为参数传入注册函数registerCallback中调用callback,即执行了print函数。
registCallback(print, 10);
}
四、多线程和多进程
对于有线程系统:
(1)进程是资源分配的独立单位
(2)线程是资源调度的独立单位
对于无线程系统:
(1)进程是资源调度、分配的独立单位
4.1 进程之间的通信方式以及优缺点
管道(PIPE)
(1)有名管道:一种半双工的通信方式,它允许无亲缘关系进程间的通信。
①优点:可以实现任意关系的进程间的通信。
②缺点:a、长期存于系统中,使用不当容易出错;b、缓冲区有限。
(2)无名管道:一种半双工的通信方式,只能在具有亲缘关系的进程间使用(父子进程)。
①优点:简单方便。
②缺点:a、局限于单向通信;b、只能创建在它的进程以及其有亲缘关系的进程之间;c、缓冲区有限。
信号量(Semaphore):一个计数器,可以用来控制多个线程对共享资源的访问。
- 优点:可以同步进程。
②缺点:信号量有限。
信号(Signal):一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
消息队列(Message Queue):是消息的链表,存放在内核中并由消息队列标识符标识。
- 优点:可以实现任意进程间的通信,并通过系统调用函数来实现消息发送和接收之间的同步,无需考虑同步问题,方便。
②缺点:信息的复制需要额外消耗 CPU 的时间,不适宜于信息量大或操作频繁的场合。
共享内存(Shared Memory):映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。
- 优点:无须复制,快捷,信息量大。
②缺点:a、通信是通过将共享空间缓冲区直接附加到进程的虚拟地址空间中来实现的,因此进程间的读写操作的同步问题;b、利用内存缓冲区直接交换信息,内存的实体存在于计算机中,只能同一个计算机系统中的诸多进程共享,不方便网络通信。
套接字(Socket):可用于不同计算机间的进程通信
①优点:
a、传输数据为字节级,传输数据可自定义,数据量小效率高;
b、传输数据时间短,性能高;
c、适合于客户端和服务器端之间信息实时交互;
d、可以加密,数据安全性强;
②缺点:需对传输的数据进行解析,转化成应用级的数据。
4.2 线程之间的通信方式
4.2.1 锁机制
包括互斥锁/量(mutex)、读写锁(reader-writer lock)、自旋锁(spin lock)、条件变量(condition)
- 互斥锁/量(mutex):提供了以排他方式防止数据结构被并发修改的方法。
互斥锁机制主要包括下面的基本函数:
- 互斥锁初始化:pthread_mutex_init()
- 互斥锁上锁:pthread_mutex_lock()
- 互斥锁判断上锁:pthread_mutex_trylock()
- 互斥锁接锁:pthread_mutex_unlock()
- 消除互斥锁:pthread_mutex_destroy()
- 读写锁(reader-writer lock):允许多个线程同时读共享数据,而对写操作是互斥的。
读写锁机制主要包括下面的基本函数:
- int pthread_rwlock_init(pthread_rwlock_t * rwlock, const pthread_rwlockattr_t * attr);
- int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
- int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
- int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
- int pthread_mutex_timedrdlock(pthread_rwlock_t * rwlock,const struct timespec * tsptr);
- int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
- int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
- int pthread_mutex_timedwrlock(pthread_rwlock_t * rwlock,const struct timespec * tsptr);
- int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
- 自旋锁(spin lock)与互斥锁类似,都是为了保护共享资源。互斥锁是当资源被占用,申请者进入睡眠状态;而自旋锁则循环检测保持者是否已经释放锁。
自旋锁机制主要包括下面的基本函数:
- int pthread_spin_destroy(pthread_spinlock_t *lock);
- int pthread_spin_init(pthread_spinlock_t *lock, int pshared);
- int pthread_spin_lock(pthread_spinlock_t *lock);
- int pthread_spin_trylock(pthread_spinlock_t *lock);
- int pthread_spin_unlock(pthread_spinlock_t *lock);
- 条件变量(condition):可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
多线程信号量包括下面的基本函数。
- int sem_init(sem_t *sem, int pshared, unsigned int val);
- int sem_wait(sem_t *sem);
- int sem_post(sem_t *sem);
- int sem_destory(sem_t *sem);
4.2.2 信号量机制(Semaphore)
(1)无名线程信号量
(2)命名线程信号量
信号机制(Signal):类似进程间的信号处理
屏障(barrier):屏障允许每个线程等待,直到所有的合作线程都达到某一点,然后从该点继续执行。
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制
进程之间私有和共享的资源
私有:地址空间、堆、全局变量、栈、寄存器
共享:代码段,公共数据,进程目录,进程 ID
线程之间私有和共享的资源
私有:线程栈,寄存器,程序计数器
共享:堆,地址空间,全局变量,静态变量
4.3 多进程与多线程间的对比、优劣与选择
1. 对比
2. 优劣
3. 选择
(1)需要频繁创建销毁的优先用线程
(2)需要进行大量计算的优先使用线程
(3)强相关的处理用线程,弱相关的处理用进程
(4)可能要扩展到多机分布的用进程,多核分布的用线程
(5)都满足需求的情况下,用你最熟悉、最拿手的方式
五、Linux网络编程
5.1 TCP
5.1.1 TCP网络模型

在Linux下创建一个tcp服务器,有以下六个步骤:
socket – 创建套接字
bind – 绑定主机和端口
listen --设置监听套接字
accept – 接收客户端连接,并生成新的套接字
read/write – 收发数据
close – 关闭套接字
创建客户端主要分为以下几步:
socket --创建套接字
connect --主动连接服务器
write/read --发收数据
close --关闭套接字
- socket – 创建套接字
函数原型:int socket(int domain, int type, int protocol);
参数说明:
domain:协议族,指定通信时用的协议族;常用选项如下:
AF_UNIX, AF_LOCAL:Local communication,用于本地进程/线程间通信;
AF_INET:IPv4 Internet protocols
AF_INET6:IPv6 Internet protocols
type:套接字类型,常用选项如下:
SOCK_STREAM:流式套接字,唯一对应于TCP;
SOCK_DGRAM:数据报套接字,唯一对应于UDP;
SOCK_RAW:原始(透传)套接字;
protocol:通常填0,在type类型为SOCK_RAW时,需要该参数。
返回值:成功时返回套接字(文件描述符),失败返回-1。
- bind – 绑定主机和端口
函数原型:int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
通用地址结构:
struct sockaddr {
sa_family_t sa_family; //地址族
char sa_data[14];
}
Internet地址结构:
struct sockaddr_in {
u_short sin_family; // 地址族, AF_INET,2 bytes
u_short sin_port; // 端口,2 bytes
struct in_addr sin_addr; // IPV4地址,4 bytes
char sin_zero[8]; // 8 bytes unused,作为填充
};
IPv4地址结构
// internet address
struct in_addr
{
in_addr_t s_addr; // u32 network address
};
本地通信协议地址结构:可用于进程间通信
struct sockaddr_un
{
sa_family_t sun_family; //协议族
char sun_path[108]; //套接字文件路径
}
- listen --设置监听套接字
参数:sockfd --- 套接字文件描述符
backlog --- 监听队列长度
- accept – 接收客户端连接,并生成新的套接字
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
参数:
sockfd --- 套接字文件描述符
addr --- 客户端的IP和端口号
addrlen --- 客户端的地址长度
注: addr和addrlen用于获取客户端的地址,如果不需要知道客户端,则这两个参数置为NULL
- connect –主动连接服务器(客户端)
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
参数:
sockfd --- 套接字文件描述符
addr --- 服务器的地址
addrlen--- addr的长度
- read/write – 收发数据
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
参数:
sockfd --- 套接字文件描述符
buf --- 发送数据的首地址
len --- 发送的字节数
flags --- 发送方式(0)
size_t recv(int sockfd, void *buf, size_t len, int flags);
参数: sockfd --- 套接字文件描述符
buf --- 存放数据的空间首地址
len --- 想要接收的字节数
flags --- 接收方式(0)
- close – 关闭套接字
- setsockopt函数
参考链接:https://blog.csdn.net/Mr_XJC/article/details/106788694
5.2 UDP
步骤(函数调用见TCP):
(1)创建socket
(2)绑定IP及端口bind
(3)收发消息
参考链接:Linux环境下实现UDP通信_linux udp通信_workingwei的博客-CSDN博客
六、数据结构
typedef struct和struct定义结构体的区别
参考链接:【C语言】typedef struct 和 struct 使用区别_typedef struct和直接struct的区别_米杰的声音的博客-CSDN博客
struct 的语法比较复杂,我们一一举例。
例一:
struct{
char a;
int b;
} x;
这里,创建了一个变量,包含两个成员,
一个字符,一个整数。
例二:
struct STUDENT{
char name;
int age;
};
这里,创建了一个标签(tag),
为成员列表提供了一个STUDENT的名字。
以后就可以通过 struct STUDENT x; 来声明变量
接下来是 typedef 与 struct 的结合使用
例三:
typedef struct{
char name;
int age;
}STUDENT;
这里的作用和例二基本一致,
STUDENT现在是一个数据类型的名字。
以后声明可以直接写为 STUDENT x;
例四:
typedef struct NODE{
int data;
struct NODE* next;
}node;
这是创建链表节点的一种常见写法,可以分为两步:
第一步
struct NODE{
int data;
struct NODE* next;
};
创建了一个叫NODE的结构类型,
第二步 typedef NODE node;
把 NODE 这种数据类型命名为 node
值得注意的是
在创建链表时,
typedef struct NODE{
int data;
struct NODE* next;
}node;
创建指针使用的是 struct NODE* next;
在之后的创建、插入、删除、查找函数,以及主函数中,
声明指针统一用的是 node* pointer;
遇到的问题
- 多线程编译时,缺少库链接,编译时增加 –lpthread或者-pthread
如:gcc -o test.c test -lpthread
- Scanf空格问题,两种解决方法
- 换成fgets();
- scanf(“%[^\n]”, msg);