一. 内容简介
python调用百度翻译api,将中文论文翻译英文,并保留部分格式
二. 软件环境
2.1vsCode
2.2Anaconda
version: conda 22.9.0
三.主要流程
3.1 创建id
百度翻译开放平台,https://fanyi-api.baidu.com/
登录以后,自己名字下边有一个开发者信息,

进去以后这样,
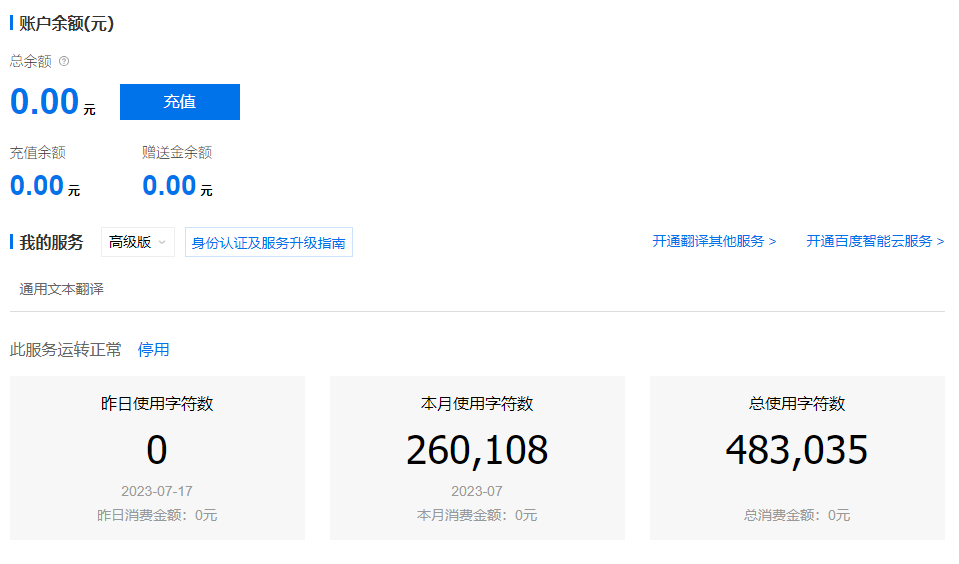
点击总览,然后把进行身份认证,就可以切换为高级版了,
切换完了以后,去开发者信息看自己的id啥的,
3.2 调用百度翻译api
import random
import hashlib
import urllib.parse
import http.client
import json
def baiduTranslate(translate_text, flag=1):
appid = '' # 填写你的appid
secretKey = '' # 填写你的密钥
httpClient = None
myurl = '/api/trans/vip/translate' # 通用翻译API HTTP地址
fromLang = 'auto' # 原文语种
if flag:
toLang = 'en' # 译文语种
else:
toLang = 'zh' # 译文语种
salt = random.randint(3276, 65536)
sign = appid + translate_text + str(salt) + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(translate_text) + '&from=' + fromLang + \
'&to=' + toLang + '&salt=' + str(salt) + '&sign=' + sign
# 建立会话,返回结果
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
# return result
return result['trans_result'][0]['dst']
except Exception as e:
print(e)
finally:
if httpClient:
httpClient.close()
if __name__ == '__main__':
# 手动录入翻译内容,q存放
# q = raw_input("please input the word you want to translate:")
q = "要翻译的句子。"
'''
flag=1 输入的句子翻译成英文
flag=0 输入的句子翻译成中文
'''
result = baiduTranslate(q, flag=1) # 百度翻译
print("原句:"+q)
print(result)

3.3 读写docx
注释我给写代码里面了
# 安装命令,我实在jupyter中写的,
! pip install python-docx
from docx import Document
from docx.shared import Pt
def translate_document(file_path):
doc = Document(file_path)
paragraphs = doc.paragraphs
i = 1
for paragraph in paragraphs:
original_text = paragraph.text
translated_text = baiduTranslate(original_text, flag=1) # 使用百度API翻译原文
# 这块是吧原文的文字给更为翻译完的,但是字体是有样式的,原来的样式被翻译完的覆盖了,段落的样式什么的都还在的
paragraph.text = translated_text
# run 就是段落中的几个字(不是一句一句的),具体怎么分的我也不太清楚,中文和英文分的也不一样
# 就当是给整段设置的样式,
for run in paragraph.runs:
run.font.name = "Times New Roman"
run.font.size = Pt(10.5)
# 给大标题设置样式
if i == 1:
for run in paragraph.runs:
run.bold = True
# 设置字号,多少多少磅对应word里面的字体几号几号
run.font.size = Pt(14)
i = i + 1
# 给小标题设置样式
if len(original_text) > 1:
if original_text and original_text[0] in "123456789":
for run in paragraph.runs:
run.bold = True
# 设置字号,多少多少磅对应word里面的字体几号几号
run.font.size = Pt(10.5)
translated_file_path = 'luu.docx' # 指定翻译后的文档保存路径
doc.save(translated_file_path)
print('翻译完成,保存为', translated_file_path)
# 提供你的原始论文文件路径
file_path = 'lu.docx'
# 使用百度API翻译文档并保存为新的文档
translate_document(file_path)
结果就不展示了,应该没问题的